zookeeper的分布式方案当然最优雅也最可靠,如果redis集群服务已经搭起或者哨兵模式已经部署的条件下,那么基于多个redis实例实现的分布式锁同样高可用,而且redis性能凸显,本文给出的是在单个redis服务上使用setnx+expire实现可用的分布式锁,也可使用redis的事务MULTI+WATCH机制实现分布式锁,只不过这种方式相对简单,本文不再赘述。
1、基于redis单实例实现的分布式锁 加锁 加锁实际上就是在redis中,给Key键设置一个全局唯一值,为避免死锁(客户端加锁后,一直没有释放锁),并该key设一个过期时间,命令如下:
1 2 3 4 5 6 7 8 SET locker uuid NX PX 20000 # locker 所有客户端都统一在redis设置的key,名称可以根据业务逻辑,例如app_write_locker # uuid是客户端自己生成的全局唯一的字符串标识,在python中可以通过UUID库生成唯一标识。 # NX 代表只在键不存在时,才能成功设置key也即成功加锁,否则给客户端返回false # PX 设置键的过期时间为2000毫秒。 # EX 若要设置秒数,则用EX # 如果上面的命令执行成功,则证明客户端获取到了锁。
延期锁的过期时间 假设有这样的场景:A客户端从加锁-业务执行-释放锁,这一过程需要5秒,锁的过期时间仅为2秒,显然2秒后,A的锁已经失效,B客户端加锁成功,但A还未处理完业务,也即出现两个客户端都加锁成功的情况。当然你可以将锁的失效时间设为更大值,这取决你对业务逻辑执行时长的熟悉度。
事实上,无需熟悉业务执行时长的情况下,也可以让客户端加锁后,再开启一个子线程不断对该客户端创建的锁延期,以保证足够的时间让业务逻辑执行完。
这个“延期锁的过期时间”在分布式锁当中,不是强制要实现的,正如前面所说,你非常清楚业务执行流程耗时基本不超过1秒,那么设置锁过期5秒,也完全OK。
解锁 解锁就是客户端将自己设置的Key删除,而且只能限制客户端A的删除自己设置的key,而且不能删除其他客户端设置的key,通过比加锁时设置的uuid,以及释放锁拿到的uuid是否一致作为实现。为了保证删除key操作的原子性,这里借用redis官方建议LUA脚本key的删除操作。
为何客户端只能删除自己设定key?
例如客户端A加锁locker成功,业务执行需要5秒,而key过期时间为2秒;2秒后导致客户端B加锁成功,业务执行需要5秒,当时间线来到第5秒时,A把B的锁删除了(客户端C此时加锁成功),而此时B还在执行业务,显然不合理。
2、python代码实现 基于redis单实例的分布式锁流程图
这里用with协议封装,使得使用者简单调用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 import redisimport timeimport datetimefrom _thread import start_new_threadimport uuidclass RedLock (object def __init__ (self, host, port, redis_timeout, retries, retry_itv, locker_key, expire, watch,extend, extend_interval ): self.host = host self.port = port self.retries = retries self.retry_itv = retry_itv self.r_timeout = redis_timeout self.locker_key = locker_key self.expire = expire self.extend = extend self.extend_interval = extend_interval self.watch_dog_thread = watch self.app_id=None self.is_get_lock=False self.conn_pool = redis.ConnectionPool(host=self.host, port=self.port, socket_connect_timeout=self.r_timeout) self.r = redis.Redis(connection_pool=self.conn_pool) def watch_dog (self ): ''' 为客户端的锁延长过期时间 ''' while True : new_app_id = self.r.get(self.locker_key) if not new_app_id: continue if self.app_id == new_app_id.decode('utf-8' ): self.expire=self.expire+self.extend self.r.set (self.locker_key, self.app_id, ex=self.expire) ttl=self.r.pttl(self.locker_key) print('watch_dog已延长该锁的过期时间至:{}s' .format (ttl/1000 )) time.sleep(self.extend_interval) continue else : break def acquire (self,retries ): self.app_id = str (uuid.uuid1()) is_set = self.r.set (self.locker_key, self.app_id, ex=self.expire, nx=True ) if is_set: print('已获得锁{}开始watch dog 线程' .format (self.app_id)) if self.watch_dog_thread: self.start_new_thread(self.watch_dog, ()) self.is_get_lock=True return self.is_get_lock else : retries=retries-1 if retries == 0 : self.is_get_lock=False return self.is_get_lock print('未获得锁,重试获锁剩余次数:{0},每次获取锁的间隔时长:{1}s' .format (retries,self.retry_itv)) time.sleep(self.retry_itv) self.acquire(retries) def atomic_delete (self ): """ 在redis服务端执行原生lua脚本,保证原子删除key,也即保证一定能解锁 """ lua_del_script = """ if redis.call("get",KEYS[1]) == ARGV[1] then return redis.call("del",KEYS[1]) else return 0 end """ lua_del_func = self.r.register_script(lua_del_script) result= lua_del_func(keys=[self.locker_key], args=[self.app_id]) return result def release (self ): now_app_id = self.r.get(self.locker_key) if not now_app_id: print('客户端未完成任务,但锁提前过期了,无法完成更新数据' ) return if self.app_id == now_app_id.decode('utf-8' ): self.atomic_delete() print('执行原子删除,锁释放:' , self.app_id) return def __enter__ (self ): self.acquire(self.retries) return self.is_get_lock def __exit__ (self, exc_type, exc_val, exc_tb ): self.release() def doing_jobs (n ): print('doing jobs at:' ,datetime.datetime.now()) time.sleep(n) print('finish jobs at' ,datetime.datetime.now()) if __name__ == "__main__" : db_conf = { 'host' : '192.168.100.5' , 'port' : 6379 , 'retries' : 5 , 'retry_itv' : 1 , 'redis_timeout' : 2 , 'locker_key' : 'locker' , 'expire' : 1 , 'extend' : 1 , 'extend_interval' : 1 } with RedLock(**db_conf) as lock: if lock: doing_jobs(5 ) else : print('获取锁超时' )
注意:在释放锁的逻辑中,引用了lua脚本执行redis删除键,这是非常微妙且核心的细节,如果使用非原生删除,有可能会出现以下极端情况:1 2 if redis.call("get",KEYS[1]) == ARGV[1] then return redis.call("del",KEYS[1])
单线程运行结果:
任务运行需要5秒,锁过期时长为1秒,那么watch_dog每隔1秒延长锁的过期时间1秒,那么在任务运行5秒这个过程中,总共将锁过期时长延长至6秒,足以保证任务完整运行且锁不失效
1 2 3 4 5 6 7 8 9 已获得锁0381e3c6-d6fa-11e9-bfb9-a45e60c5a11d开始watch dog 线程 doing jobs at: ** 10:14:50.119315 watch_dog已延长该锁的过期时间至:1.999s watch_dog已延长该锁的过期时间至:2.999s watch_dog已延长该锁的过期时间至:4.0s watch_dog已延长该锁的过期时间至:5.0s watch_dog已延长该锁的过期时间至:6.0s finish jobs at ** 10:14:55.121694 执行原子删除,锁释放: 0381e3c6-d6fa-11e9-bfb9-a45e60c5a11d
不开启watch_dog,模拟任务运行时间过长,锁先失效的情况,程序运行1秒后,锁已经失效,该客户端任务结束后,发现自己加的锁没有了,为了数据安全,客户端只能放弃本次更新记录
1 2 3 4 已获得锁e04f94b0-d6fa-11e9-b8cf-a45e60c5a11d开始watch dog 线程 doing jobs at: ** 10:21:00.531881 finish jobs at ** 10:21:05.532265 客户端未完成任务,但锁提前过期了,无法完成更新数据
3、多线程模拟多个客户端并发争取分布式锁 这里改下一部分代码:也即,每个线程共享redis连接池对象
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 class RedLock (object def __init__ (self,r,redis_timeout, retries, retry_itv, locker_key, expire, extend, extend_interval ): ...... self.r = r ...... def doing_jobs (r ): thread_name = threading.currentThread().name bonus = 'money' total = r.get(bonus) if int (total) == 0 : print('奖金已被抢完' .format (thread_name)) return if not total: print('奖金池没设置' ) return result = r.decr(bonus, 1 ) print('客户端:{0}抢到奖金,还剩{1}' .format (thread_name, result)) def run (redis_conn ): info = { 'r' :redis_conn, 'retries' : 5 , 'retry_itv' : 1 , 'redis_timeout' : 5 , 'locker_key' : 'locker' , 'expire' : 1 , 'extend' : 1 , 'extend_interval' : 1 } with RedLock(**info) as lock: if lock: doing_jobs(redis_conn) else : print('获取锁超时' ) if __name__ == "__main__" : pool_obj = redis.ConnectionPool(host='192.168.100.5' , port=6379 , socket_connect_timeout=5 ) redis_conn_obj = redis.Redis(connection_pool=pool_obj) threads = [] for _ in range (100 ): t = threading.Thread(target=run, args=(redis_conn_obj,)) threads.append(t) for t in threads: t.start() for t in threads: t.join()
在redis服务端设置值
1 2 127.0.0.1:6379> set money 10 OK
测试结果,资源为10份,故对应有10个客户端可获得资源,且是有序的扣减,其他客户端要么未抢到锁,要么抢到锁后发现没资源
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 客户端:Thread-14抢到奖金,还剩9 客户端:Thread-3抢到奖金,还剩8 客户端:Thread-78抢到奖金,还剩7 客户端:Thread-16抢到奖金,还剩6 客户端:Thread-11抢到奖金,还剩5 客户端:Thread-17抢到奖金,还剩4 客户端:Thread-5抢到奖金,还剩3 客户端:Thread-66抢到奖金,还剩2 客户端:Thread-38抢到奖金,还剩1 客户端:Thread-9抢到奖金,还剩0 获取锁超时 获取锁超时 奖金已被抢完 奖金已被抢完 ...
以上的实现都是基于redis单服务,若redis服务不可用或宕机之类的,所有客户端都无法加锁,显然单点故障不可靠,因此要实现高可用的redis分布式锁,还需设计如何在多个redis服务上实现,这就需要参考RedLock算法,后面的文章将进一步讨论。

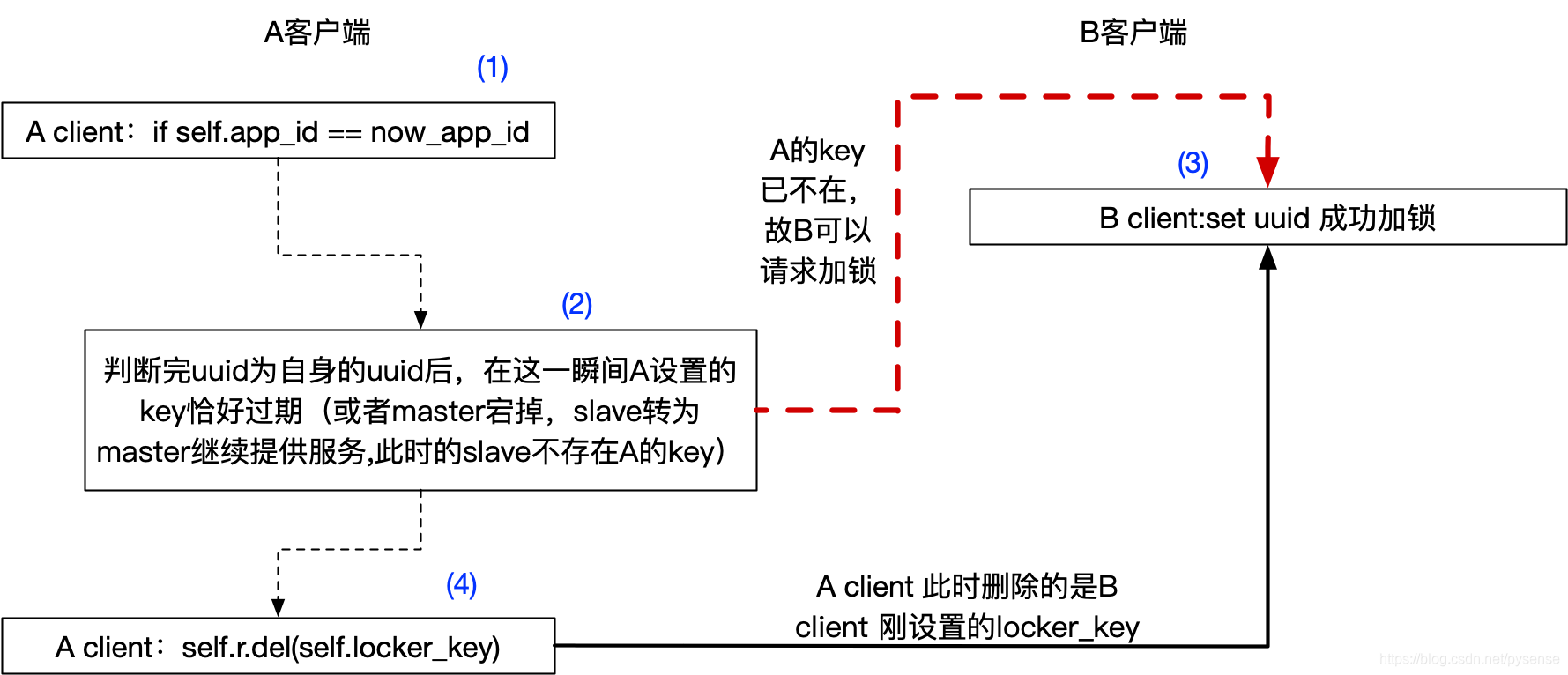 (补充极限情况(2)的另外一个突发场景:key过期时间设置为毫秒单位,
(补充极限情况(2)的另外一个突发场景:key过期时间设置为毫秒单位,