前面的blog已实现了hadoopHA的项目环境,本文继续为该hadoop环境引入flume组件,用于实时大数据项目的开发。考虑到项目已经使用了hadoopHA,那么flume的组件也相应的部署成HA模式
| hadoop节点 | 数据源节点 | 角色 |
|---|---|---|
| nn | nn | NameNode,DataNode数据源 |
| dn2 | dn2 | NameNode,DateNode数据源 |
| dn1 | dn1 | DataNode,数据源 |
其他hbase、hive等不再此表给出,因为前面的文件已有相关表格。
1、flume 的基本介绍
1.1 基本介绍
Flume is a distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of log data. It has a simple and flexible architecture based on streaming data flows. It is robust and fault tolerant with tunable reliability mechanisms and many failover and recovery mechanisms. It uses a simple extensible data model that allows for online analytic application.
简单来说:flume 是一个分布式、高可靠、高可用的用来收集、聚合、转移不同来源的大量日志数据到中央数据仓库的工具
目前flume最新版本为今年1月发布的 Flume 1.9.0,具体优化的内容:
- Better SSL/TLS support
- Configuration Filters to provide a way to inject sensitive information like passwords into the configuration
- Float and Double value support in Context
- Kafka client upgraded to 2.0
- HBase 2 support
环境要求:
Java Runtime Environment - Java 1.8 or later
1.2 数据流模型
这里以Flume收取web的日志再将其写入到hdfs作为数据流模型示例说明。
(需要注意的flume支持多级配置、扇入、扇出,这里仅介绍单级、单输入、单输出的模式)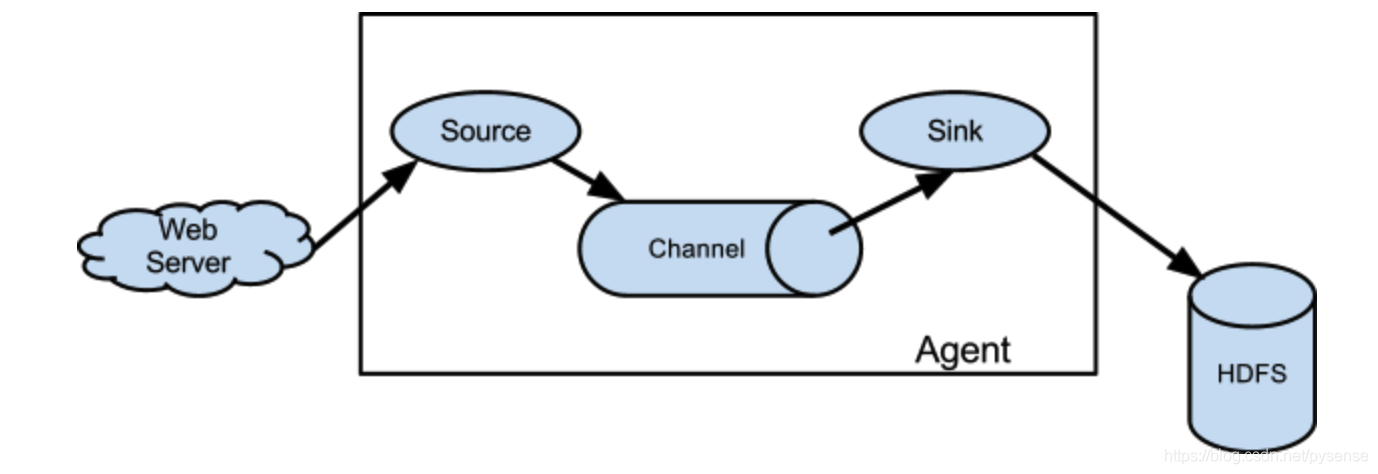
==Event==
Event是Flume定义的一个数据流传输的最小单元。Agent就是一个Flume的实例,本质是一个JVM进程,该JVM进程控制Event数据流从外部日志生产者那里传输到目的地(或者是下一个Agent)。
在Flume中,event表示数据传输的一个最小单位,从上图可以看出Agent就是Flume的一个部署实例, 一个完整的Agent中包含了三个组件Source、Channel和Sink,Source是指数据的来源和方式,Channel是一个数据的缓冲池,Sink定义了数据输出的方式和目的地。
==Source组件==
Source是数据的收集端,负责将数据捕获后进行特殊的格式化,将数据封装到事件(event) 里,然后将事件推入Channel中。(对于实时大数据项目,这个source其实就是不断滚动的log数据文件。)
Flume提供了各种source的实现,具体参考官方文档:
Flume Sources、Avro Source、Thrift Source、Exec Source、JMS Source、Taildir Source、Kafka Source、NetCat TCP Source、NetCat UDP Source、Syslog Sources、HTTP Source、Custom Source等
==Channel组件==
Channel是连接Source和Sink的组件,可以看作一个数据的缓冲区,它可以将事件暂存到内存中也可以持久化到磁盘上, 直到Sink处理完该事件。flume提供多个channel提供对event数据的缓存:
Memory Channel、JDBC Channel、Kafka Channel、File Channel、Spillable Memory Channel、Pseudo Transaction Channel、Custom Channel
(在本大数据实时项目中,使用Memory Channel即可,生产环境需要根据具体需求而定)
==Sink组件==
Sink从Channel取出event数据,并将其写入到文件系统中,数据库中,hadoop中储数据,在日志数据较少时,可以将数据存储在文件系中,并且设定一定的时间间隔保存数据。在日志数据较多时,可以将相应的日志数据存储到Hadoop中,便于日后进行相应的数据分析。
Flume也提供了各种sink的实现,具体参考官方说明:
HDFS Sink、Hive Sink、Logger Sink、Avro Sink、Thrift Sink、IRC Sink、File Roll Sink、Null Sink、HBaseSinks、AsyncHBaseSink、ElasticSearchSink、Kite Dataset Sink、Kafka Sink、HTTP Sink、Custom Sink
(在实时大数据项目中,用sink配置将数据写入kafka sink)
以上的数据模型的详细介绍可以参考中文翻译文档:地址
(注意:该翻译文档对应flume1.8版本的内容,若想查阅最新的flume,参考官网1.9原文)
2、flume的配置文件说明
flume配置遵循Java properties文件格式的文本文件。一个或多个Agent配置可放在同一个配置文件里。配置文件包含Agent的source,sink和channel的各个属性以及他们的数据流连接。
完整的配置流程如下:
命名各个组件(定义流)—>连接各个组件—>配置各个组件的属性—>启动Agent
2.1 配置过程
这里以后面文章——flume整合kafka的配置文件说明。
(有较多的blog文章会照搬a1.sources=r1,a1.sinks=k1,a1.channels=c1这样的写法,a1?r1?k1?c1?到底指代什么?所以建议要参考官方文档,否则一头雾水?当然熟悉flume后,可以使用短命名,设置配置属性字符串不会显得太长)
1 | 1、列出Agent的所有Source、Channel、Sink |
对于本blog的实时大数据项目的配置,Agent名字为:agent_log从本地服务器读取log数据文件,使用内存channel缓存,然后通过kafka Sink从channel读取后发送到kafka集群,它的配置文件应该这样配:
1 | 1、定义Agent的所有source、sink和channel组件 |
通过上面的配置,就形成了[log-src]->[log-mem-channel]->[log-sink]的数据流,这将使Event通过内存channel(log-mem-channel)从log-src流向Kafka-sink,从而实现数据源-flume-kafka的实时数据流动。
3、单点flume agent测试
本节主要在name节点上部署单个flume agent,用于测试单agent的使用。
数据流向:
手动写日志内容—->flume spooldir抽取—->flume sink到hadoop集群文件系统上
3.1 基本安装
个人习惯将所有的hadoop组件都放置在同一个dir下,方便管理,如下所示1
2
3
4[root@nn opt]# ls
flume-1.9.0 hive-3.1.2 xcall.sh
hadoop-3.1.2 jdk1.8.0_161 scala-2.13.1
hbase-2.1.7 mariadb-10.4.8 spark-2.4.4-bin-hadoop2.7 zookeeper-3.4.14
配置flume-env.sh1
2
3
4
5
6[root@nn conf]# pwd
/opt/flume-1.9.0/conf
[root@nn conf]# cp flume-env.sh.template flume-env.sh
vi flume-env.sh
配置java1.8的路径
export JAVA_HOME=/opt/jdk1.8.0_16
这里的配置要注意的点:如果已经在系统的环境变量配置JAVA_HOME,那么flume-env.sh可以不用再配置java路径
配置flume-conf.properties
这里就是用于配置flume agent的文件。有了第2章节的介绍后,这里有关source、channel、sink配置则相对简单,因此可以使用短字符进行配置1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31 列出三个组件
a1.sources = r1
a1.channels = c1
a1.sinks = k1
设置source数据源为本地某个文件目录,flume监听这个目录下日志文件
a1.sources.r1.type = spooldir
a1.sources.r1.channels = c1
注意这里不需要写成web_log/
a1.sources.r1.spoolDir = /opt/flume_log/web_log
设置channel,使用本节点的内存缓存event
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
将evevt数据写到hadoop文件系统的指定目录下
a1.sinks.k1.channel=c1
a1.sinks.k1.type=hdfs
需自行创建该目录,hdapp为hadoop集群名称,不需要加入端口,否则flume无法写入,
a1.sinks.k1.hdfs.path=hdfs://hdapp/flume/web_log
a1.sinks.k1.hdfs.fileType=SequenceFile
a1.sinks.k1.hdfs.writeFormat=Writable
存放在hdfs的文件文件命名方式,其实还有更详细的配置,这里仅给出简单示例,具体可参考官网。
a1.sinks.k1.hdfs.filePrefix=%Y-%m-%d
a1.sinks.k1.hdfs.fileSuffix=.txt
从flume过来的数据,每128M分割成一个文件
a1.sinks.k1.hdfs.rollSize = 128000000
最终在hdfs的文件名称为:%Y-%m-%d.TimeStamp.txt
a1.sinks.k1.hdfs.useLocalTimeStamp = true
这里在配置source.type要注意的是,配成spooldir类型后:允许把要收集的文件放入磁盘上的某个指定目录。它会将监视这个目录中产生的新文件,并在新文件出现时从新文件中解析数据出来。数据解析逻辑是可配置的。
与Exec Source不同,Spooling Directory Source是可靠的,即使Flume重新启动或被kill,也不会丢失数据。
但这种可靠有一定的代价和限制:指定目录中的文件必须是不可变的、唯一命名的。Flume会自动检测避免这种情况发生,如果发现问题,则会抛出异常:
如果文件在写入完成后又被再次写入新内容,Flume将向其日志文件(这是指Flume自己logs目录下的日志文件)打印错误并停止处理。如果在以后重新使用以前的文件名,Flume将向其日志文件打印错误并停止处理。
为了避免上述问题,最好在生成新文件的时候文件名加上时间戳,可以通过加入属性项实现:a1.sinks.k1.hdfs.useLocalTimeStamp = true
3.2 启动flume agent进程
1 | [root@nn flume-1.9.0]# pwd |
命令含义1
2
3
4
5
6
7
8
9
10commands:
help display this help text
agent run a Flume agent
avro-client run an avro Flume client
version show Flume version info
global options:
--conf,-c <conf> use configs in <conf> directory
agent options:
--name,-n <name> the name of this agent (required)
--conf-file,-f <file> specify a config file (required if -z missing)
创建数据文件,测试flume 能否成功把目录下的文件推到hdfs指定目录上1
2
3
4
5
6
7
8[root@nn web_log]# pwd
/opt/flume_log/web_log
[root@nn web_log]# vi log.txt
aaa
bbb
当文件创建后,发现该log.txt被命名为log.txt.COMPLETED,说明已经被flume 读取过
[root@nn web_log]# ls
log.txt.COMPLETED
hdfs上可看到数据文件已经上传到到/flume/web_log(这里打码了时间)1
2
3[root@nn web_log]# hdfs dfs -ls /flume/web_log
Found 1 items
-rw-r--r-- 3 root supergroup 161 **** /flume/web_log/2019-**-**.15**0.txt
3.3 将source.type配成tail F
Spooling Directory Source是可靠的,它会将监视这个目录中产生的新文件,并在新文件出现时从新文件中解析数据出来,当此种方式不适合本blog后面开发的实时大数据项目需求。具体说明如下:
本blog后面开发的实时大数据项目需求:
实时抽取access.log的访问日志,access.log每插入一行,flume 就会把它实时sink到hdfs上(本文用于测试所以先sink到hdfs,若已经到开发阶段,这里会改为sink到kalka集群上)。
对于spooldir模式,当log.txt被sink后其文件名变为log.txt.COMM,若继续向log.txt.COMPLETED append数据行,flume不会再抽取该文件,也说明无法把新来的数据sink到hdfs上,显然不符合需求。
source需做以下调整,使用exec source:1
2
3
4 修改source type
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /opt/flume_log/web_log/access.log
a1.sources.r1.channels = c1
这里sink的文件滚动策略很重要,若配置不当,flume sink会在hdfs不断滚动生成多个小文件,例如access.log新增一行,触发flume sink在hdfs新增一个对应的文件。
以下的配置:access.log在hdfs存放的形式为:
/flume/web_log/2019-05-31.1579*.txt
每达到128M则开始滚动新建一个文件。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16 将evevt数据写到hadoop文件系统的指定目录下
a1.sinks.k1.channel=c1
a1.sinks.k1.type=hdfs
需自行创建该目录
a1.sinks.k1.hdfs.path=hdfs://hdapp/flume/web_log
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat =Text
a1.sinks.k1.hdfs.useLocalTimeStamp = true
a1.sinks.k1.hdfs.rollInterval = 0
a1.sinks.k1.hdfs.rollSize = 128M
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.minBlockReplicas=1
a1.sinks.k1.hdfs.idleTimeout=0
a1.sinks.k1.hdfs.useLocalTimeStamp = true
a1.sinks.k1.hdfs.filePrefix=%Y-%m-%d
a1.sinks.k1.hdfs.fileSuffix=.txt
但exec source方式也有缺点:会丢失数据,例如当flume 挂了重启,之前进来的日志行将不会被重启后flume抽取到,正官方的提示:
The problem with ExecSource and other asynchronous sources is that the source can not guarantee that if there is a failure to put the event into the Channel the client knows about it. In such cases, the data will be lost.
这种数据丢失其实还可以接受,毕竟大部分日志收集应用场景还没到高级事务的严格标准,而且服务器集群运行以及进程运行稳定,即使宕机、断电再重启,也只是一小部分日志行丢失。
==测试结果:==
启动flume agent,并将日志实时打印在shell1
2
3[root@nn flume-1.9.0]# bin/flume-ng agent -c conf -f conf/flume-conf.properties --name a1 -Dflume.root.logger=INFO,console
将日志追加新数据行
[root@nn web_log]# echo 'test'>>access.log
在hdfs上,存放的文件会以文件名.txt.tmp形式保持打开状态,供flume实时写入,若达到滚动条件,则会生成日期+时间戳.txt的数据文件,再新建另外一个日期+时间戳.txt.tmp文件。
至此,已完成flume的部署,下一步,在三个节点上配置高可用的flume集群。
4、flume高可用配置
Flume高可用又称Flume NG高可用,NG:Next Generation。
flume高可用的实现思路比较清晰:多个节点flume agent avro sink 到 多个flume collector avro source上,这些flume collector 会有优先级,优先级高的collector负责把数据sink到hdfs或者kafka上。因为agent和collector是多节点运行,在agent端:某个agent挂了,还有其他agent工作;在collecor端,某个collector挂了,还有其他collector继续工作。
架构图如下: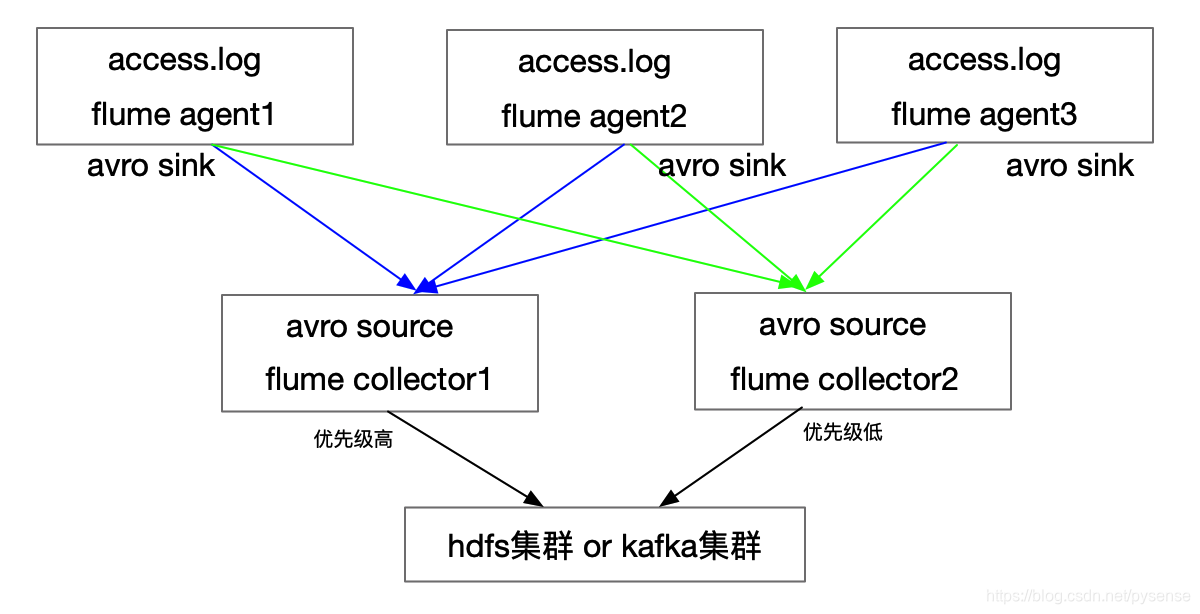 各个节点规划,考虑到测试虚拟机资源有限,其中两个节点都分布运行agent和collector进程。
各个节点规划,考虑到测试虚拟机资源有限,其中两个节点都分布运行agent和collector进程。
| 节点 | flume 角色|
|—|—|
| nn | agent1,collector 1|
| dn1 | agen2 |
| dn2 | agent3,collector2 |
4.1 三个agent的flume配置
三个agent的配置其实都一样,不同的部分:每个agent命名不同。
在nn节点的/opt/flume-1.9.0/conf新建一个avro-agent.properties1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42 列出agent1的组件,sinks有两个,分别去到collector1和collector2
agent1.sources = r1
agent1.channels = c1
agent1.sinks = k1 k2
设置source属性
agent1.sources.r1.channels = c1
agent1.sources.r1.type = exec
agent1.sources.r1.command = tail -F /opt/flume_log/web_log/access.log
设置channel
agent1.channels.c1.type = memory
agent1.channels.c1.capacity = 1000
agent1.channels.c1.transactionCapacity = 100
设置sink到collector1
agent1.sinks.k1.channel = c1
agent1.sinks.k1.type = avro
agent1.sinks.k1.hostname = nn
agent1.sinks.k1.port = 52020
设置sink到collector2
agent1.sinks.k2.channel = c1
agent1.sinks.k2.type = avro
agent1.sinks.k2.hostname = dn2
agent1.sinks.k2.port = 52020
创建sink groups,将多个sinks绑定为一个组,agent会向这些组sink 数据,将k1和k2设置负载均衡模式,也可以设置为failover模式,本文使用load_balance
agent1.sinkgroups = g1
agent1.sinkgroups.g1.sinks = k1 k2
agent1.sinkgroups.g1.processor.type = load_balance
agent1.sinkgroups.g1.processor.backoff = true
agent1.sinkgroups.g1.processor.selector = round_robin
agent1.sinkgroups.g1.processor.selector.maxTimeOut=10000
failover模式,只有collector1工作。仅当collector1挂了后,collector2才能启动服务。
agent1.sinkgroups.g1.processor.type = failover
值越大,优先级越高,collector1优先级最高
agent1.sinkgroups.g1.processor.priority.k1 = 10
agent1.sinkgroups.g1.processor.priority.k2 = 1
发生异常的sink最大故障转移时间(毫秒),这里设为10秒
agent1.sinkgroups.g1.processor.maxpenalty = 10000
将avro-agent.properties拷贝到dn1和dn2节点,agent1这个名字可改,可不改。
4.2 配置 collector
分别在nn和dn2节点的/opt/flume-1.9.0/conf新建一个avro-collector.properties1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33 在dn2节点上,则改为collector2,不改也没关系,这里只是为了区分两个collector
collector1.sources = r1
collector1.sinks = k1
collector1.channels = c1
定义source:这里的source配成avro,从而连接agent端sink avro
collector1.sources.r1.channels = c1
collector1.sources.r1.type = avro
bind的属性:dn2节点需改为dn2
collector1.sources.r1.bind = nn
collector1.sources.r1.port = 52020
定义channel
collector1.channels.c1.type = memory
collector1.channels.c1.capacity = 1000
collector1.channels.c1.transactionCapacity = 100
定义sinks:由collector将数据event推到hdfs上
collector1.sinks.k1.channel=c1
collector1.sinks.k1.type=hdfs
collector1.sinks.k1.hdfs.path=hdfs://hdapp/flume/web_log
collector1.sinks.k1.hdfs.fileType = DataStream
collector1.sinks.k1.hdfs.writeFormat =Text
collector1.sinks.k1.hdfs.useLocalTimeStamp = true
collector1.sinks.k1.hdfs.rollInterval = 0
collector1.sinks.k1.hdfs.rollSize = 0
collector1.sinks.k1.hdfs.rollCount = 0
collector1.sinks.k1.hdfs.minBlockReplicas=1
collector1.sinks.k1.hdfs.idleTimeout=0
collector1.sinks.k1.hdfs.useLocalTimeStamp = true
collector1.sinks.k1.hdfs.filePrefix=%Y-%m-%d
collector1.sinks.k1.hdfs.fileSuffix=.txt
4.3 测试flume高可用
在nn节点和dn2节点启动各自的collector1
2
3
4
5
6
7nn节点启动collector进程,因为该节点的avro-collector.properties agent名字为collector1,所以这里启动的--name 为collector1
[root@nn flume-1.9.0]#
bin/flume-ng agent -c conf -f conf/avro-collector.properties --name collector1 -Dflume.root.logger=INFO,console
dn2节点启动collector进程,因为该节点的avro-collector.properties agent名字为collector2,所以这里启动的--name 为collector2
[root@nn flume-1.9.0]#
bin/flume-ng agent -c conf -f conf/avro-collector.properties --name collector2 -Dflume.root.logger=INFO,console
在nn、dn1和dn2节点启动各自的agent,在shell可以看到以下agent 进程打印的信息,说明三个agent都可以连接到两个collector的source组件k1和k21
2
3
4
5Monitored counter group for type: SINK, name: k1: Successfully registered new MBean.
Rpc sink k1 started.
......
Monitored counter group for type: SINK, name: k2: Successfully registered new MBean.
Rpc sink k2 started.
在nn节点上的access.log新增信息 echo ‘foo’ >>access.log后,在hdfs上可以看到*.txt.tmp文件可以相应的文件内容
停止collector1经常,此时测试collector2可以正常接替服务。
至此,已完成本文内容。下一篇文章为Hadoop引入Kafka组件,在实时大数据项目中,实时数据是被flume sink到kafka的topic里,而不是本文测试的hdfs。