在前面blog文章中:《在hadoopHA节点上部署flume高可用组件》和《在hadoopHA节点上部署kafka集群组件》,已经实现大数据实时数据流传输两大组件的部署和测试,本文将讨论flume组件连接kafka集群相关内容,两组件在项目架构图的位置如下图1红圈所示:
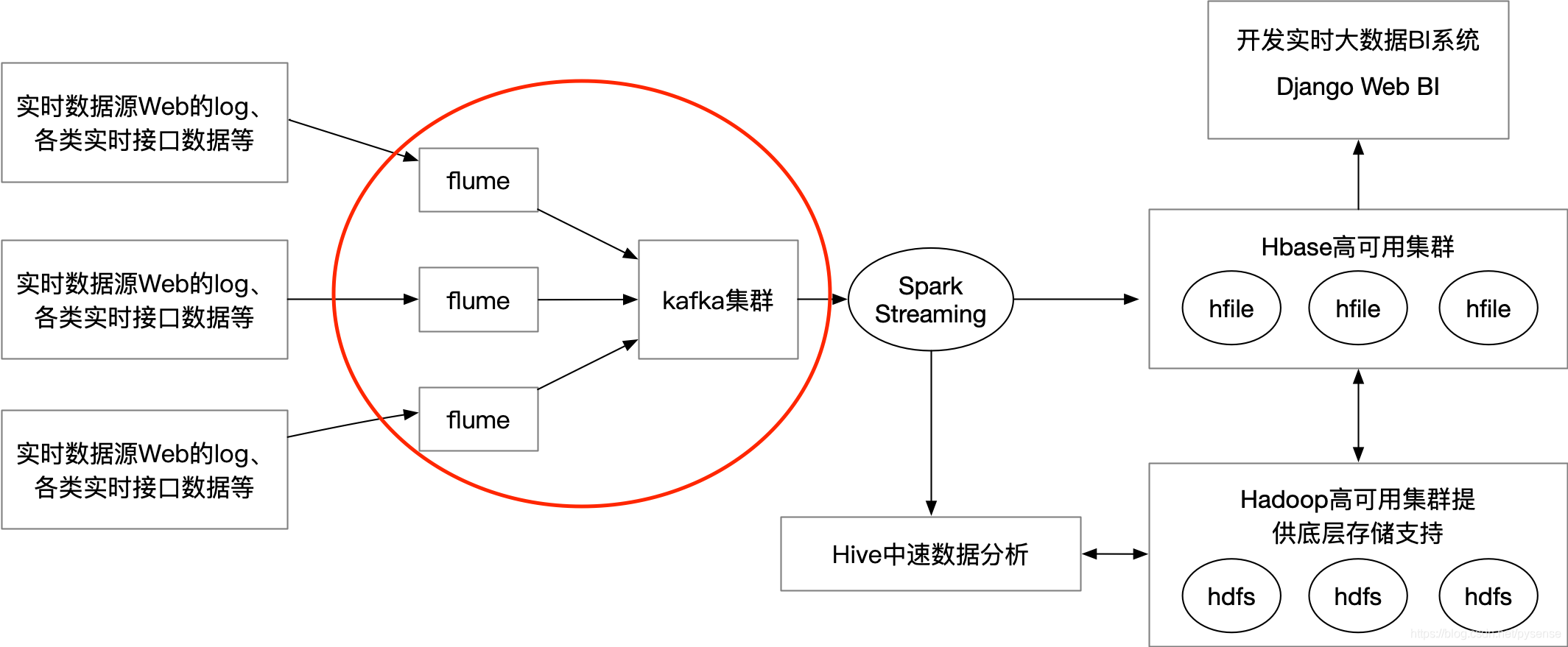 flume NG集群前向的source是各类实时的log数据,通过flume sink将这些日志实时sink到后向kafka集群,所有flume sink其实是本架构里kafka的producer角色,kafka集群后向连接spark streaming,用于消费kafka的实时消息(log日志数据)流。
flume NG集群前向的source是各类实时的log数据,通过flume sink将这些日志实时sink到后向kafka集群,所有flume sink其实是本架构里kafka的producer角色,kafka集群后向连接spark streaming,用于消费kafka的实时消息(log日志数据)流。
组件版本:
flume-1.9.0、kafka-2.12
1.在kafka集群上创建相应的topic
在实时大数据项目中,实时数据是被flume sink到kafka的topic里,而不是直接sink到hdfs上。
创建topic需要做一定规划,考虑到目前有三个broker节点,分别为nn、dn1以及dn2节点,所以创建了3个分区,每个分区有三个replica,topic名为:sparkapp1
2
3
4
5
6
7
8[root@nn kafka_2.12]# bin/kafka-topics.sh --create --zookeeper nn:2181/kafka-zk --replication-factor 3 --partitions 3 --topic sparkapp
Created topic sparkapp.
[root@nn kafka-2.12]# bin/kafka-topics.sh --describe --zookeeper nn:2181/kafka-zk --topic sparkapp
Topic:sparkapp PartitionCount:3 ReplicationFactor:3 Configs:
Topic: sparkapp Partition: 0 Leader: 11 Replicas: 11,12,10 Isr: 11,12,10
Topic: sparkapp Partition: 1 Leader: 12 Replicas: 12,10,11 Isr: 12,10,11
Topic: sparkapp Partition: 2 Leader: 10 Replicas: 10,11,12 Isr: 10,11,12
-zookeeper nn:2181/kafka-zk:因为kafka在zk的所有znode都统一放置在/kafka-zk路径下,所以启动时需要注意加上该路径。
2.单节点配置flume的agent sink
2.1 配置flume 文件
这里首先给出单节点的flume是如何连接到kafka集群,在nn节点上启动flume进程。在第3章节,将给出flume集群连接kafka集群,实现两组件之间的高可用实时数据流。
flume source的数据源为/opt/flume_log/web_log/access.log
这里拷贝一份新的配置文件,配置过程简单,相关组件的参数说明可以参考flume官网最新文档:
kafka-sink章节[root@nn conf]# cp flume-conf.properties flume-kafka.properties
1 | [root@nn conf]# pwd |
这里的linger.ms=5主要是处理下情况:
producer是按照batch进行发送,但是还要看linger.ms的值,默认是0,表示不做停留。这种情况下,可能有的batch中没有包含足够多的produce请求就被发送出去了,造成了大量的小batch,给网络IO带来的极大的压力。
这里设置producer请求延时5ms才会被发送。
2.2 测试数据消费情况
在dn1节点上启动kafka consumer进程,等待flume sink,因为kafka已经集群,所以—bootstrap-server 选任意一个节点都可以,前提所选节点需在线1
[root@dn1 kafka-2.12]# bin/kafka-console-consumer.sh --bootstrap-server nn:9092 --topic saprkapp
在nn节点上启动flume agent,这里不是后台启动,目的是为了实时观测flume agent 实时数据处理情况。1
2
3
4[root@nn flume-1.9.0]# pwd
/opt/flume-1.9.0
启动flume agent 实例
[root@nn flume-1.9.0]# bin/flume-ng agent -c conf -f conf/flume-kafka.properties --name a1
手动在source文件最加新的文本行
[root@nn web_log]# echo “testing flume to kafka” >>access.log
在dn1 上可以看到实时输出nn节点上flume sink过来的消息1
2[root@dn1 kafka_2.12]# bin/kafka-console-consumer.sh --bootstrap-server nn:9092 --topic sparkapp
testing flume to kafka
以上完成单节点flume实时数据到kafka的配置和测试,下面将使用flume集群模式sink到kafka集群
3.flume NG集群连接kafka集群
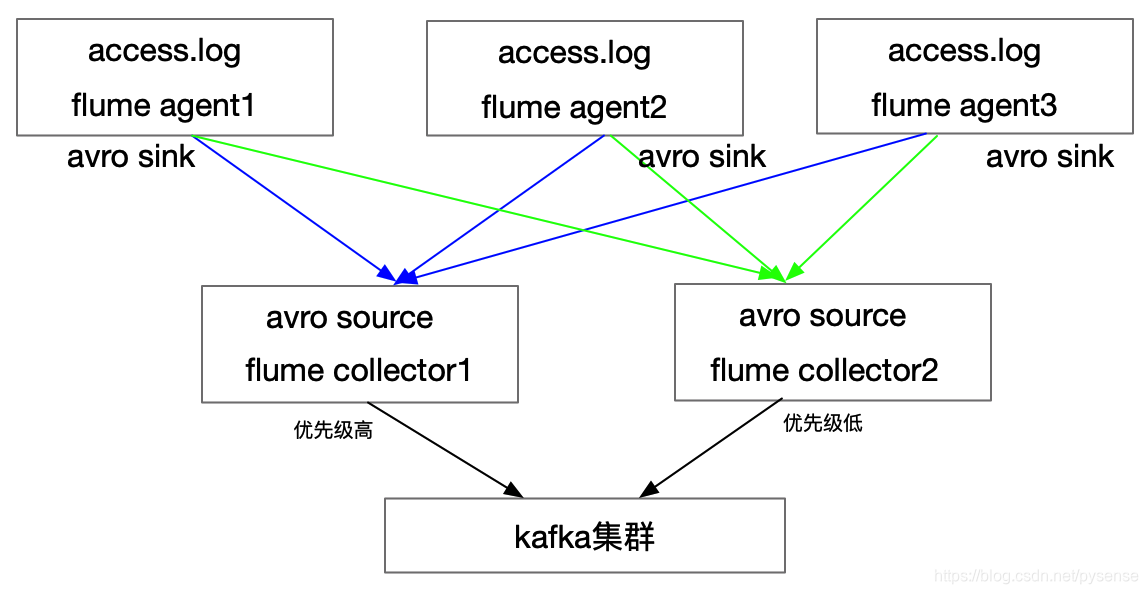 图3 为flume NG集群连接kafka集群的示意图
图3 为flume NG集群连接kafka集群的示意图
配置也相对简单,只需要把《在hadoopHA节点上部署flume高可用组件》第4.2章节的collector配置的sinks部分改为kafkasink,agent1、agent2和agent3用第4.1章节所提的配置文件内容即可,本文不再给出。
给个flume节点角色分布表
| 节点 | flume 角色|kafka角色|
|—|—|—|
| nn | agent1,collector 1|kafka broker
| dn1 | agen2 |kafka broker
| dn2 | agent3,collector2 |kafka broker
3.1 配置collector
因为测试环境计算资源有限,每个flume进程和kafka进程都在同一服务器上运行,实际生产环境flume和kafka分别在不同服务器上。
配置collector:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31[root@nn conf]# pwd
/opt/flume-1.9.0/conf
[root@nn conf]# vi avro-collector.properties
# 定义三个组件
collector1.sources = r1
collector1.sinks = k1
collector1.channels = c1
# 定义source:这里的source配成avro,连接flume agent端sink avro
collector1.sources.r1.type = avro
# bind的属性:dn2节点对应改为dn2
collector1.sources.r1.bind = nn
collector1.sources.r1.port = 52020
#定义channel
collector1.channels.c1.type = memory
collector1.channels.c1.capacity = 500
collector1.channels.c1.transactionCapacity = 100
# 指定sinktype 为kafka sink,从而使得flume collector成为kafka的producer
collector1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
collector1.sinks.k1.kafka.bootstrap.servers = nn:9092,dn1:9092,dn2:9092
collector1.sinks.k1.kafka.topic = sparkapp
collector1.sinks.k1.kafka.flumeBatchSize = 20
collector1.sinks.k1.kafka.producer.acks = 1
collector1.sinks.k1.kafka.producer.linger.ms = 5
collector1.sinks.k1.kafka.producer.compression.type = snappy
# source组件和sinks组件绑定channel组件
collector1.sources.r1.channels = c1
collector1.sinks.k1.channel=c1
3.2 启动flume-ng集群服务
在nn和dn2节点上使用nohup & 后台启动flume collector进程
nn节点上collector进程,jps可以看到Application进程
1
2
3
4
5
6
7[root@nn flume-1.9.0]# nohup bin/flume-ng agent -c conf -f conf/avro-collector.properties --name collector1 -Dflume.root.logger=INFO,console &
[1] 26895
[root@nn flume-1.9.0]# jps
27168 Jps
15508 QuorumPeerMain
23589 Kafka
26895 Application
dn2同样操作,这里不再给出。
分别在nn、dn1和dn2节点上使用nohup & 后台启动启动flume agent进程1
2
3
4
5
6
7[root@nn flume-1.9.0]# nohup bin/flume-ng agent -c conf -f conf/avro-agent.properties --name agent1 -Dflume.root.logger=INFO,console &
[root@nn flume-1.9.0]# jps
15508 QuorumPeerMain
324 Jps
23589 Kafka
30837 Application
32462 Application
可以在nn节点看到两个 Application进程,一个是flume collector进程,另外一个是flume agent进程。
dn1和dn2取同样的后台启动方式,这里不再给出。
3.3 测试flume与kafka高可用
任找一个节点,启动kafka consumer 进程,这里在dn1节点上启动1
[root@dn1 kafka_2.12]# ./bin/kafka-console-consumer.sh --bootstrap-server nn:9092,dn1:9092,dn2:9092 --topic sparkapp
因为nn、dn1、dn2三个节点上都有flume agent进程,分别在每个节点下的access.log追加新数据行,如下所示:1
2
3
4
5
6
7
8
9
10
11
12# nn节点追加新数据行
[root@nn web_log]# pwd
/opt/flume_log/web_log
[root@nn web_log]# echo "flume&kafka HA--msg from nn" >>access.log
# dn1节点追加新数据行
[root@dn1 web_log]# pwd
/opt/flume_log/web_log
[root@dn1 web_log]#echo "flume&kafka HA--msg from dn1" >>access.log
# dn2节点追加新数据行
[root@dn2 web_log]# pwd
/opt/flume_log/web_log
[root@dn2 web_log]# echo "flume&kafka HA--msg from dn2" >>access.log
在kafka consumer shell可以看到实时接收三条记录:
能否关闭其中collector所在服务器中的一台用于同时测试flume和kafka的高可用,例如关闭nn服务器?
不能,因为这里只有三个节点,zookeeper集群必须要三个及以上才能保证高可用,因此这里只需要kill nn节点上的collector,此时flume集群只有dn2的collector在工作,按上面的步骤,在三个节点上都给access.log新增数据行,同样可以正常观测到dn1的kafka consumer拿到3条message
4.小结
本文给出了flume与kafka连接的高可用部署过程,设置相对简单,考虑到测试环境资源限制,这里把flume集群和kafka集群放在同一服务器,生产环境中,flume集群有独立的服务器提供,kafka集群也由独立的服务器提供。后面几篇文章将给出有关spark的深度理解和kafka与spark streaming整合内容,目的为用于实现实时处理批数据的环节。