在前面的《基于hadoop3.1.2分布式平台上部署spark HA集群》,这篇是基于非HA模式下hadoop集群的spark集群HA配置,而本文将给出基于HA模式下hadoop集群的spark集群HA配置,并将yarn HA集群映入到spark中,做资源管理。为何要做些环境的配置呢?因为到本篇文章为止,已经完成hadoop HA集群、hbaseHA集群,hive集群(非HA)、sparkHA集群、flumeHA集群、kafka HA集群,实现实时数据流动,接下的文章重点探讨spark streaming、spark以及pyspark相关知识,这将涉及多个计算任务以及相关计算资源的分配,因此需要借助yarn HA集群强大的资源管理服务来管理spark的计算任务,从而实现完整的、接近生产环境的、HA模式下的大数据实时分析项目的架构。
服务器资源分配表(仅列出yarn和spark):
| 节点 | yarn 角色 | spark 角色 |
|---|---|---|
| nn | ResourceManager, NodeManager | Master,Worker |
| dn1 | NodeManager | Worker |
| dn2 | ResourceManager, NodeManager | Master,Worker |
这里再提下yarn管理大数据集群计算中对资源有效管理(主要指CPU、物理内存以及虚拟内存)的重要性:
整个集群的计算任务由ResourceManager和NodeManager共同完成,其中,ResourceManager中的调度器负责资源的分配,而NodeManager则负责资源的供给和隔离。ResourceManager将某个NodeManager上资源分配给任务(这就是所谓的“资源调度”)后,NodeManager需按照要求为计算任务提供相应的资源,甚至保证这些资源应具有独占性,为任务运行提供基础的保证,这就是所谓的资源隔离。
因为spark就是负责计算,有大量计算任务要运行,每个任务总得分配cpu和内存给它用,否则某些计算任务会被“饿死”(巧妇难为无米之炊),这种比喻比较形象。
YARN HA模式的配置
yarn HA模式的运行是于hadoop HA模式运行的,关于hadoop HA部署和测试可以参考本博客文章《基于Hadoop HA集群部署HBase HA集群(详细版)》的第6章内容,考虑到后面文章将会给出各种spark计算任务,结合测试服务器本身cpu和内存资源有限,这里主要重点介绍yarn-site.xml和mapred-site.xml配置文件说明。
完整 yarn-site.xml配置
yarn-site的配置其实分为两大块:第一部分为yarn HA集群的配置,第二部分为根据现有测试服务器资源来优化yarn配置。
==yarn-site.xml在三个节点上都使用相同配置,无需更改==
第一部分:yarn HA集群的配置
(注意这里仅给出property,若复制该配置内容,需在xml文件里面加入<configuration></configuration>)
1 | <!-- 启用yarn HA高可用性 --> |
以上将nn和dn2作为yarn集群主备节点,对应的id为rm1、rm2
第二部分:yarn的优化配置
A、禁止检查每个任务正使用的物理内存量、虚拟内存量是否可用
若任务超出分配值,则将其杀掉。考虑到作为测试环境,希望看到每个job都能正常运行,以便记录其他观测事项,这里将其关闭。
1 | <property> |
B、配置RM针对单个Container能申请的最大资源或者RM本身能配置的最大内存
配置解释:单个容器可申请的最小与最大内存,Application在运行申请内存时不能超过最大值,小于最小值则分配最小值,例如在本文测试中,因计算任务较为简单,无需太多资源,故最小值设为512M,最大值设为1024M。注意最大最不小于1G,因为yarn给一个executor分配512M时,还需要另外动态的384M内存(Required executor memory (512), overhead (384 MB))。1
2
3
4
5
6
7
8
9<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>1024</value>
</property>
若将yarn.scheduler.maximum-allocation-mb设为例如512M,spark on yarn就会启动失败。
C、NM的内存资源配置,主要是通过下面两个参数进行的
第一个参数:每个节点可用的最大内存,默认值为-1,代表着yarn的NodeManager占总内存的80%,本文中,物理内存为1G
第二个参数:NM的虚拟内存和物理内存的比率,默认为2.1倍1
2
3
4
5
6
7
8
9
10<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>1024</value>
<description>nm向本机申请的最大物理内存,默认8G</description>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>3</value>
</property>
vmem-pmem-ratio的默认值为2.1,由于本机器中,每个节点的物理内存为1G,因此单个RM拿到最大虚拟内存为2.1G,例如在跑spark任务,会出现2.5 GB of 2.1 GB virtual memory used. Killing container的提示,Container申请的资源为2.5G,已经超过默认值2.1G,当改为3倍时,虚拟化够用,故解决可该虚拟不足的情况。
mapred-site.xml的配置文件说明
mapred-site的配置其实分为两大块:第一部分为mapreduce的基本配置,第二部分为根据现有测试服务器资源来优化mapreduce计算资源分配的优化配置。
==mapred-site.xml在三个节点上都需要配置,只需把nn主机名改为当前节点的主机名即可==
第一部分:mapreduce的基本配置
(注意这里仅给出property,若复制该配置内容,需在xml文件里面加入<configuration></configuration>)
1 | <!-- 使用yarn框架来管理MapReduce --> |
这里主要配置开启jobhistory服务以及MapReduce多种日志存放
第二部分:mapreduce的优化项1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35<property>
<name>mapreduce.map.memory.mb</name>
<value>100</value>
<description>每个mapper任务的物理内存限制</description>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>200</value>
<description>每个reducer任务的物理内存限制</description>
</property>
<property>
<name>mapreduce.map.cpu.vcores</name>
<value>1</value>
<description>每个mapper任务申请的虚拟cpu核心数,默认1</description>
</property>
<property>
<name>mapreduce.reduce.cpu.vcores</name>
<value>1</value>
<description>每个reducer任务申请的虚拟cpu核心数,默认1</description>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx100m</value>
<description>mapper阶段的JVM的堆大小</description>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx200m</value>
<description>reduce阶段的JVM的堆大小</description>
</property>
根据当前服务器物理配置资源,在内存和CPU方面给mapper和reducer任务进行调优。
yarn HA的启动
首先确保hadoop HA集群已正常启动1
2
3
4[root@nn sbin]# hdfs haadmin -getServiceState nn
active
[root@nn sbin]# hdfs haadmin -getServiceState dn2
standby
启动yarn HA服务,只需在nn节点启动yarn后,其他节点会自动启动相应服务。1
2
3
4
5[root@nn sbin]# start-yarn.sh
[root@nn sbin]# yarn rmadmin -getServiceState rm1
active
[root@nn sbin]# yarn rmadmin -getServiceState rm2
standby
以上完成yarn HA配置,因为涉及hadoop HA和调优,因此不建议刚入门的同学就按此配置继续测试,建议从最原始、最简单的非HA hadoop开始着手。
下面开始配置spark。
spark HA 集群及其基本测试
修改spark配置
经历第1章节繁琐的yarn HA配置后, 当资源管理问题得到妥善解决,那么接下的计算任务将实现的非常流畅。
spark HA集群详细的部署和测试,请参考《基于hadoop3.1.2分布式平台上部署spark HA集群》的第8章节,本文不再累赘。
把spark 的任务交给yarn管理还需要在HA集群上再加入部分配置,改动也简单 ,只需在spark-defaults.conf和spark-env.sh改动。1
2
3
4
5
6
7
8
9
10
11
12
13
14[root@nn conf]# pwd
/opt/spark-2.4.4-bin-hadoop2.7/conf
[root@nn conf]# vi spark-defaults.conf
#spark.master spark://nn:7077
spark.eventLog.enabled true
# spark.eventLog.dir hdfs://nn:9000/directory
spark.eventLog.dir hdfs://hdapp/directory
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.driver.memory 512m
spark.driver.cores 1
spark.yarn.jars hdfs://hdapp/spark_jars/*
spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"
重点配置项目说明:
原standalone模式下:spark.master设为 spark://nn:7077
因为spark已经配成HA模式,因此无需指定master是谁,交由zookeeper管理。
spark.eventLog.dir hdfs://hdapp/directory
这里hdfs路径从nn:9000改为hdapp,是因为hadoop已经配置为HA模式,注意集群模式下是不需要加上端口: hdfs://hdapp:9000/directory,这会导致NameNode无法解析host部分。
spark.yarn.jars hdfs://hdapp/spark_jars/*
这里需要将spark跟目录下的jar包都上传到hdfs指定的spark_jars目录下,若不这么处理,每次提交spark job时,客户端每次得先上传这些jar包到hdfs,然后再分发到每个NodeManager,导致任务启动很慢。而且启动spark也会提示:
==WARN yarn.Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.==
解决办法:1
2
3
4[root@nn spark-2.4.4-bin-hadoop2.7]# pwd
/opt/spark-2.4.4-bin-hadoop2.7
[root@nn spark-2.4.4-bin-hadoop2.7]# hdfs dfs -mkdir /spark_jars
[root@nn spark-2.4.4-bin-hadoop2.7]# hdfs dfs -put jars/* /spark_jars
spark-defaults.conf在三个节点上使用相同配置。
spark-env.sh的配置:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28[root@nn conf]# pwd
/opt/spark-2.4.4-bin-hadoop2.7/conf
[root@nn conf]# vi spark-env.sh
# 基本集群配置
export SCALA_HOME=/opt/scala-2.12.8
export JAVA_HOME=/opt/jdk1.8.0_161
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=nn:2181,dn1:2181,dn2:2181 -Dspark.deploy.zookeeper.dir=/spark"
export HADOOP_CONF_DIR=/opt/hadoop-3.1.2/etc/hadoop
# yarn模式下的调优配置
# Options read in YARN client/cluster mode
export SPARK_WORKER_MEMORY=512M
# - SPARK_CONF_DIR, Alternate conf dir. (Default: ${SPARK_HOME}/conf) 无需设置,使用默认值
# - HADOOP_CONF_DIR, to point Spark towards Hadoop configuration files
export HADOOP_CONF_DIR=/opt/hadoop-3.1.2/etc/hadoop
# - YARN_CONF_DIR, to point Spark towards YARN configuration files when you use YARN 上面HADOOP_CONF_DIR以已设置即可
# - SPARK_EXECUTOR_CORES, Number of cores for the executors (Default: 1). 无需设置,默认使用1个vcpu
# - SPARK_EXECUTOR_MEMORY, Memory per Executor (e.g. 1000M, 2G) (Default: 1G)
export SPARK_EXECUTOR_MEMORY=512M
# - SPARK_DRIVER_MEMORY, Memory for Driver (e.g. 1000M, 2G) (Default: 1G)
export SPARK_EXECUTOR_MEMORY=512M
# 存放计算过程的日志
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=9001
-Dspark.history.retainedApplications=5
-Dspark.history.fs.logDirectory=hdfs://hdapp/directory"
以上的driver和executor的可用内存设为512M,考虑到测试服务器内存有限的调优。若生产服务器,一般32G或者更大的内存,则可以任性设置。
启动spark集群
在nn节点上,启动wokers: start-slaves.sh,该命令自动启动其他节点的worker
在nn节点和dn2节点启动master进程:start-master.sh
查看nn:8080和dn2:8080的spark web UI是否有active以及standby模式。
跑一个wordcount例子,测试spark集群能否正常计算结果。
创建一个本地文件1
2
3
4[root@nn spark-2.4.4-bin-hadoop2.7]# vi /opt/foo.txt
spark on yarn
yarn
spark HA
启动pyspark,连接到spark集群1
2
3
4
5
6
7
8
9
10
11[root@nn spark-2.4.4-bin-hadoop2.7]# ./bin/pyspark --name bar --driver-memory 512M --master spark://nn:7077
# 读取本地文件/opt/foo.txt
>>> df=sc.textFile("file:///opt/foo.txt")
# 切分单词,过滤空值
>>> words = df.flatMap(lambda line: line.split(' ')).filter(lambda x: x !="")
>>> words.collect()
[u'spark', u'on', u'yarn', u'yarn',u'spark', u'HA']
# 将个word映射为(word,1)这样的元组,在reduce汇总。
>>> counts = words.map(lambda word: (word, 1)).reduceByKey(lambda a, b: a + b)
>>> counts.collect()
[(u'spark', 2), (u'yarn', 2), (u'on', 1), (u'HA', 1)]
以上完成spark HA集群和测试。
spark on yarn
spark on yarn意思是将spark计算人任务提交到yarn集群上运行。
spark集群跑在yarn上的两种方式
根据spark官网的文档说明,这里引用其内容:
There are two deploy modes that can be used to launch Spark applications on YARN. In cluster mode, the Spark driver runs inside an application master process which is managed by YARN on the cluster, and the client can go away after initiating the application. In client mode, the driver runs in the client process, and the application master is only used for requesting resources from YARN.
cluster模式下,spark driver 在 AM里运行,客户端(或者应用程序)在提交完任务(初始化)后可直接退出,作业会继续在 YARN 上运行。显然cluster 模式不适合交互式操作。cluster模式的spark计算结果可以保持到
外部数据库,例如hbase。这部分内容将是spark streaming可以完成的环境,spark streaming以yarn cluster模式运行,实时将处理结果存到hbase里,web BI 应用再从hbase取数据。
client模式下,spark driver是在本地环境运行,AM仅负责向yarn请求计算资源(Executor 容器),例如交互式运行基本的操作。
在前面第2节的word count例子里,用下面的启动命令:1
[root@nn spark-2.4.4-bin-hadoop2.7]# pyspark --name bar --driver-memory 512M --master spark://nn:7077
该命令启动是一个spark shell进程,没有引入yarn管理其资源,因此在yarn集群的管理页面http://nn:8088/cluster/apps/RUNNING,将不会 bar这个application。
测试spark on yarn
只需在启动spark shell时,将--master spark://nn:7077 改为--master yarn --deploy-mode cluster或者--master yarn --deploy-mode client,那么spark提交的任务就会交由yarn集群管理
还是以word count为例,使用yarn client模式启动spark
创建测试文件:1
2
3
4vi /opt/yarn-word-count.txt
spark on yarn
spark HA
yarn HA
启动driver1
2
3
4
5
6
7
8
9
10
11
12
13
14[root@nn spark-2.4.4-bin-hadoop2.7]# pyspark --name client_app --driver-memory 512M --executor-memory 512M --master yarn --deploy-mode client
Python 2.7.5 (default, Oct 30 2018, 23:45:53)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-36)] on linux2
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 2.4.4
/_/
Using Python version 2.7.5 (default, Oct 30 2018 23:45:53)
SparkSession available as 'spark'.
>>> sc
<SparkContext master=yarn appName=client_app >
这里driver和executor都是以最小可用内存512来启动spark-shell
因为该spark 任务是提交到yarn 上运行,所以在spark web ui后台:http://nn:8080,running application 为0 这是需要去yarn后台入口:
这是需要去yarn后台入口:http://nn:8088,可以看到刚提交的计算任务: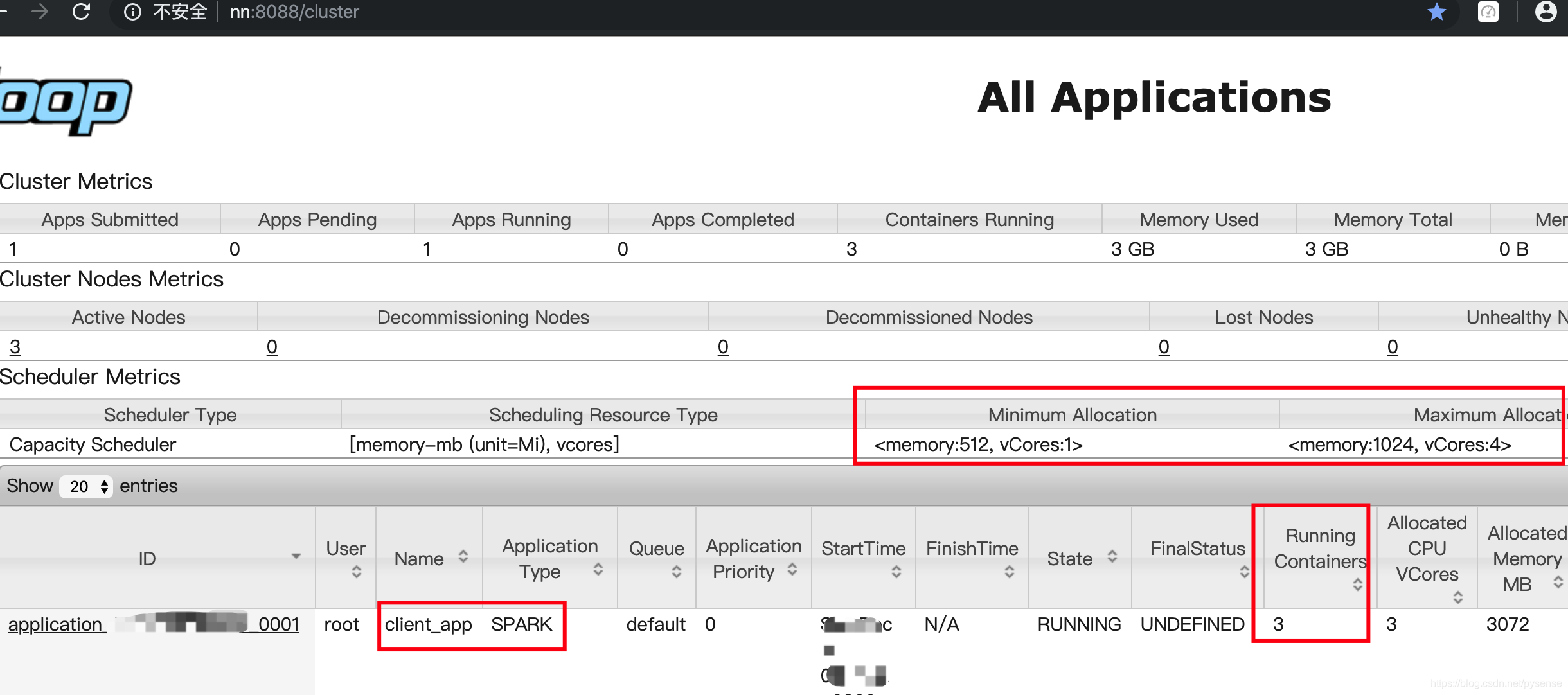 可以看到该application(计算任务)分配了3个Container
可以看到该application(计算任务)分配了3个Container 通过查看该applicationMaster管理页面,可以看到client-yarn这个app更为详细的计算过程,例如该wordcount在reduceByKey DAG可视化过程。
通过查看该applicationMaster管理页面,可以看到client-yarn这个app更为详细的计算过程,例如该wordcount在reduceByKey DAG可视化过程。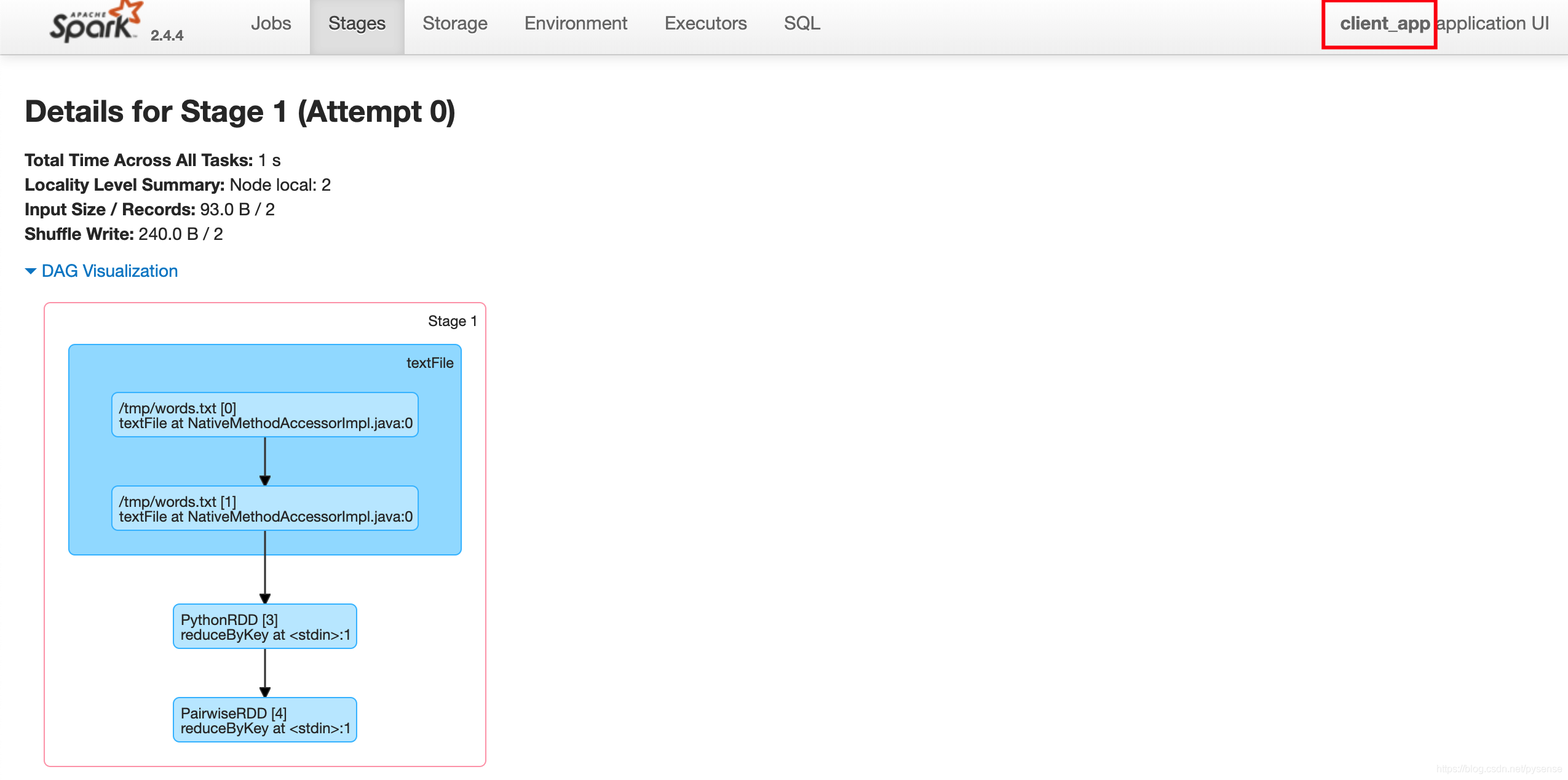
yarn cluster模式下,因为它不是打开一个spark shell让你交互式输入数据处理逻辑,所以需先把处理逻辑封装成一个py模块。
以上面的word count为例:
word_count.py
1 | from pyspark import SparkConf, SparkContext |
需要使用spark-submit 提交到yarn1
[root@dn2 spark-2.4.4-bin-hadoop2.7]# ./bin/spark-submit --driver-memory 512M --executor-memory 512M --master yarn --deploy-mode cluster --py-files word_count.py
在yarn管理也可以看到该app,application的命名好像直接用脚本名字,而不是指定的cluster-yarn 关于如何提交py文件,官方也给出指引:
关于如何提交py文件,官方也给出指引:
For Python, you can use the —py-files argument of spark-submit to add .py, .zip or .egg files to be distributed with your application. If you depend on multiple Python files we recommend packaging them into a .zip or .egg.
如有多个py文件(例如1.py依赖2.py和3.py),需要通过将其打包为.zip或者.egg包: —py-files tasks.zip
提交spark application的多种方式
spark运行有standalone模式(分local、cluster)、on yarn模式(分client、cluster)还有on k8s,而且可以附带jar包或者py包,多种提交的方式的命令模板怎么写?网上其实很多类似文章,但都是给的某个模式的某种文件的提交方式,其实在spark官网的submitting-applications章节给出详细的多种相关命令模板。这里统一汇总:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68 Run application locally on 8 cores 本地模式
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[8] \
/path/to/examples.jar \
100
standalone 集群下的client模式
Run on a Spark standalone cluster in client deploy mode
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://207.184.161.138:7077 \
--executor-memory 20G \
--total-executor-cores 100 \
/path/to/examples.jar \
1000
standalone 集群下的cluster模式
Run on a Spark standalone cluster in cluster deploy mode with supervise
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://207.184.161.138:7077 \
--deploy-mode cluster \
--supervise \
--executor-memory 20G \
--total-executor-cores 100 \
/path/to/examples.jar \
1000
on yarn 集群,且用的class文件和jar包
Run on a YARN cluster
export HADOOP_CONF_DIR=XXX
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \ # can be client for client mode
--executor-memory 20G \
--num-executors 50 \
/path/to/examples.jar \
1000
这里给出如何传入py文件,可以不写 --py-files 选项
Run a Python application on a Spark standalone cluster
./bin/spark-submit \
--master spark://207.184.161.138:7077 \
examples/src/main/python/pi.py \
1000
Run on a Mesos cluster in cluster deploy mode with supervise
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master mesos://207.184.161.138:7077 \
--deploy-mode cluster \
--supervise \
--executor-memory 20G \
--total-executor-cores 100 \
http://path/to/examples.jar \
1000
Run on a Kubernetes cluster in cluster deploy mode
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master k8s://xx.yy.zz.ww:443 \
--deploy-mode cluster \
--executor-memory 20G \
--num-executors 50 \
http://path/to/examples.jar \
1000
小结
本文内容主要为后面的文章——spark streaming 与kafka集群的实时数据计算做铺垫,考虑到测试环境环境资源有限,在做spark streaming的时候,将不会以spark HA模式运行,也不会将任务提交到yarn集群上,而是用一节点作为spark streaming计算节点,具体规划参考该文。