本文内容第一部分给出Pyspark常见算子的用法,第二部分则参考书籍《Python spark2.0 Hadoop机器学习与大数据实战》的电影推荐章节。本文内容为大数据实时分析项目提供基本的入门知识。
1、PySpark简介
本节内容的图文一部分参考了这篇文章《PySpark 的背后原理 》,个人欣赏此博客作者,博文质量高,看完受益匪浅!Spark的内容不再累赘,可参考本博客《深入理解Spark》。PySpark的工作原理图示如下: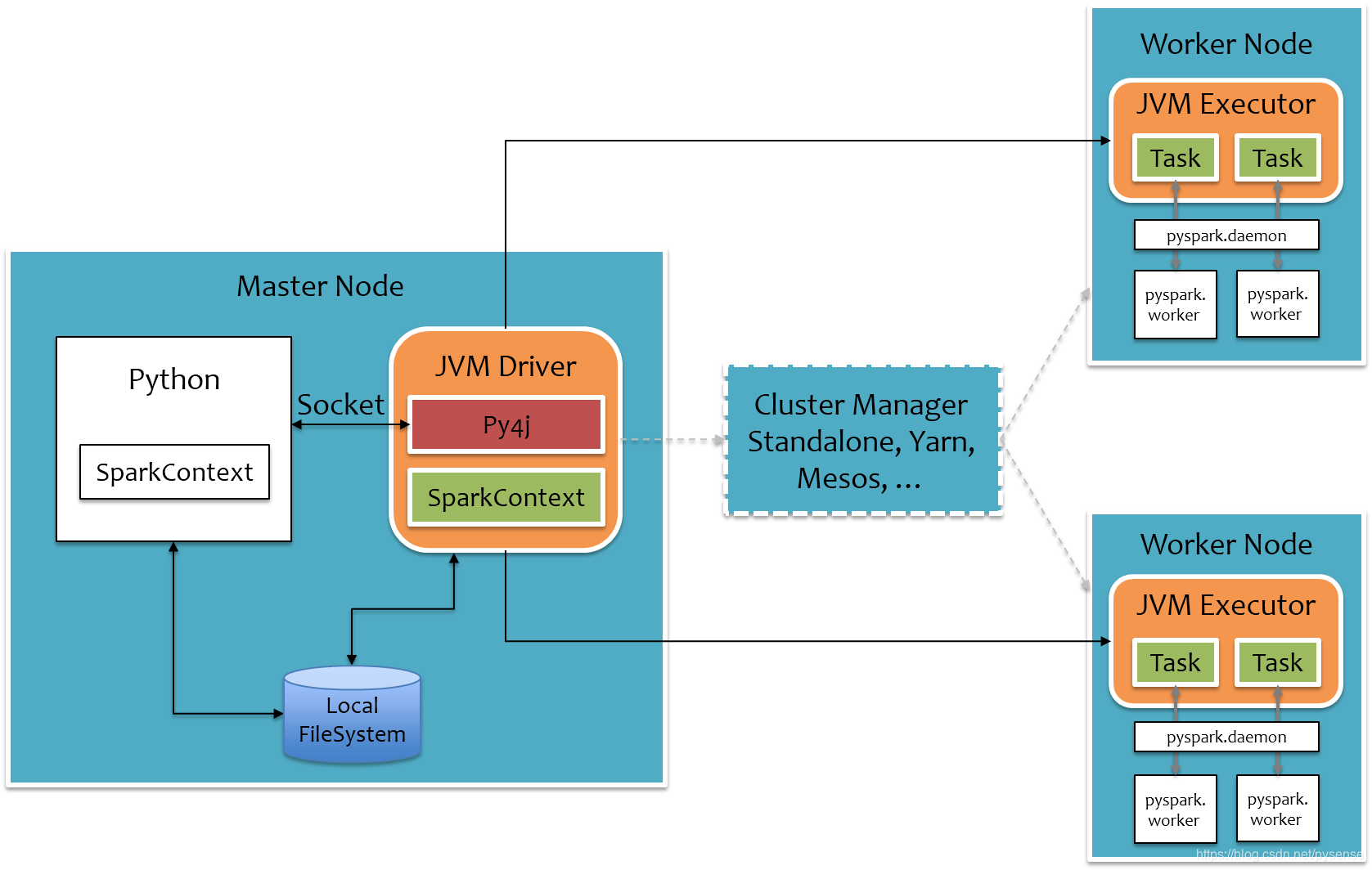
在这里,Py4J 是一个用 Python 和 Java 编写的库,它可以让Python代码实现动态访问JVM的Java对象,同时JVM也能够回调 Python对象。因此PySpark就是在Spark外围包装一层Python API,借助Py4j实现Python和Java的交互(这里的交互就是通过socket实现,传字节码),进而实现通过Python编写Spark应用程序。 在Driver端,PySparkContext通过Py4J启动一个JVM并产生一个JavaSparkContext;在Executor端,则不需要借助Py4j,因为Executor端运行的是由Driver传过来的Task业务逻辑(其实就是java的字节码)。
在Driver端,PySparkContext通过Py4J启动一个JVM并产生一个JavaSparkContext;在Executor端,则不需要借助Py4j,因为Executor端运行的是由Driver传过来的Task业务逻辑(其实就是java的字节码)。
2、Pyspark接口用法
读取数据源
PySpark支持多种数据源读取,常见接口如下:1
2
3
4sc.pickleFile() # <class 'pyspark.rdd.RDD'>
sc.textFile() # <class 'pyspark.rdd.RDD'>
spark.read.json() # <class 'pyspark.sql.dataframe.DataFrame'>
spark.read.text() # <class 'pyspark.sql.dataframe.DataFrame'>
例如读取本地要注意,格式为file://+文件绝对路径1
sc.textFile("file:///home/mparsian/dna_seq.txt")
1
2# 读取hdfs上文件数据
sc.textFile("your_hadoop/data/moves.txt")
常用算子
Spark的算子分为两类:Transformation和Action。
Transformation仅仅是定义逻辑,并不会立即执行,有lazy特性,目的是将一个RDD转为新的RDD,可以基于RDDs形成lineage(DAG图);
Action:触发Job运行,真正触发driver运行job;
第一类算子:Transformation
- map(func): 返回一个新的RDD,func会作用于每个map的key,例如在wordcount例子要
rdd.map(lambda a, (a, 1))将数据转换成(a, 1)的形式以便之后做reduce1
2
3
4
5
6
7
8word_rdd = sc.parallelize (
["foo", "bar", "foo", "pyspark", "kafka","kafka", 10,10]
)
word_map_rdd = word_rdd.map(lambda w: (w, 1))
mapping = word_map_rdd.collect()
print(mapping)
#输出
[('foo', 1), ('bar', 1), ('foo', 1), ('pyspark', 1), ('kafka', 1), ('kafka', 1), (10, 1), (10, 1)]
- mappartitions(func, partition): Return a new RDD by applying a function to each partition of this RDD.和map不同的地方在于map的func应用于每个元素,而这里的func会应用于每个分区,能够有效减少调用开销,减少func初始化次数。减少了初始化的内存开销。
例如将一个数据集合分成2个区,再对每个区进行累加,该方法适合对超大数据集合的分区累加处理,例如有1亿个item,分成100个分区,有10台服务器,那么每台服务器就可以负责自己10个分区的数据累加处理。
官方也提到mappartitions中如果一个分区太大,一次计算的话可能直接导致内存溢出。
1 | rdd = sc.parallelize([10, 22, 3, 4], 2) |
filter(func): 返回一个新的RDD,func会作用于每个map的key,用于筛选数据集
1
2
3rdd = sc.parallelize (["fooo", "bbbar", "foo", " ", "Aoo"])
rdd.filter(lambda x: 'foo' in x).collect()
# ['fooo', 'foo']
- flatMap(func): 返回一个新的RDD,func用在每个item,并把item切分为多个元素返回,例如wordcount例子的分类
1
2
3
4rdd = sc.parallelize (["this is pyspark", "this is spark"])
rdd.flatMap(lambda line:line.split(' ')).collect()
#可以看到每个item为一句话,经过func后,分解为多个单词(多个元素)
# ['this', 'is', 'pyspark', 'this', 'is', 'spark']
1 | rdd = sc.parallelize ((1,2,3)) |
- flatMapValues(func):flatMapValues类似于mapValues,不同的在于flatMapValues应用于元素为key-value对的RDD中Value。每个一kv对的Value被输入函数映射为一系列的值,然后这些值再与原RDD中的Key组成一系列新的KV对。
1 | rdd = sc.parallelize([("name", ["foo", "bar", "aoo"]), ("age", ["12", "20"])]) |
mapValues(func): 返回一个新的RDD,对RDD中的每一个value应用函数func。
1
2
3rdd = sc.parallelize([("name", ["foo", "bar", "aoo"]), ("age", ["12", "20"])])
rdd.mapValues(lambda value:len(value)).collect()
# [('name', 3), ('age', 2)]distinct(): 去除重复的元素
1
2
3rdd = sc.parallelize([("a", 1),("a", 10) ,("b", 1), ("a", 1)])
rdd.distinct().collect()
# [('a', 1), ('a', 10), ('b', 1)]subtractByKey(other): 删除在RDD1与RDD2的key相同的项
1 | rdd1 = sc.parallelize([("a", 1),("a", 10) ,("b", 1), ("a", 1)]) |
- subtract(other): 取差集
1
2
3
4rdd1 = sc.parallelize([("a", 1),("a", 10) ,("b", 1), ("a", 1)])
rdd2 = sc.parallelize([("a", 1),("a", 10) ,("c", 1), ("a", 1)])
rdd1.subtract(rdd2).collect()
# [('b', 1)]
- intersection(other): 交集运算,保留在两个RDD中都有的元素
1 | rdd1 = sc.parallelize([("a", 1),("a", 10) ,("b", 1), ("a", 1)]) |
有关key-value类型的处理
1 | rdd = sc.parallelize([("a", 1),("a", 10) ,("b", 1), ("a", 1)]) |
foldByKey(zeroValue, func, numPartitions=None)Merge the values for each key using an associative function “func” and a neutral “zeroValue” which may be added to the result an arbitrary number of times, and must not change the result (e.g., 0 for addition, or 1 for multiplication.).
其实foldByKey也像reduceBykey,对同一key中的value进行合并,例如对相同key进行value累加,zeroValue=0表示累加:1
2
3rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 1)])
rdd.foldByKey(0, lambda x,y:x+y).collect()
# [('a', 2), ('b', 1)]
1 | #对相同key进行value累乘,注意zeroValue=1代表累乘: |
- groupByKey(numPartitions=None): 将(K, V)数据集上所有Key相同的数据聚合到一起,得到的结果是(K, (V1, V2…))
1
2
3
4rdd = sc.parallelize([("a", 1),("a", 10) ,("b", 1), ("a", 1)])
sorted(rdd.groupByKey().mapValues(len).collect())
# 统计数据集每个key的个数总和
# [('a', 3), ('b', 1)]
1 | rdd = sc.parallelize([("a", 1),("a", 10) ,("b", 1), ("a", 1)]) |
- reduceByKey(func, numPartitions=None):此算子最常用, 将(K, V)数据集上所有Key相同的数据聚合到一起,func的参数即是每两个K-V中的V。可以使用这个函数来进行计数,例如reduceByKey(lambda a,b:a+b)就是将key相同数据的Value进行相加。
1 | rdd = sc.parallelize([("foo", 1), ("foo", 2), ("bar", 3)]) |
- join(other, numPartitions=None): 将(K, V)和(K, W)类型的数据进行JOIN操作,得到的结果是这样(K, (V, W))
1 | rdd1 = sc.parallelize([("bar", 10) , ("foo", 1)]) |
- union(other): 并集运算,合并两个RDD
1 | rdd1 = sc.parallelize([("a", 10) ,("b", 1), ("a", 1)]) |
还有更多的transmission算子这里不再一一列举,可以参考官网PySpark API文档。
第二类算子:Action
collect(): 以数组的形式,返回数据集中所有的元素。在数据探索阶段常用。
1
2
3
4
5
6
7
8word_rdd = sc.parallelize (
["foo", "bar", "foo", "pyspark", "kafka","kafka", 10,10]
)
word_map_rdd = word_rdd.map(lambda w: (w, 1))
word_map_rdd.collect()
# 输出
[('foo', 1), ('bar', 1), ('foo', 1), ('pyspark', 1), ('kafka', 1), ('kafka', 1), (10, 1), (10, 1)]collectAsMap将k-v数据rdd集合转为python字典类型,同一key的项,只取第一项,其他的项被忽略
1
2rdd = sc.parallelize([("a", 1),("a", 10) ,("b", 1), ("a", 1)])
rdd.collectAsMap() # {'a': 1, 'b': 1}- count(): 返回数据集中元素的个数
1 | word_rdd = sc.parallelize ( |
- take(n): 返回数据集的前N个元素
1 | word_rdd = sc.parallelize ( |
- takeOrdered(n): 升序排列,取出前N个元素
1
2
3
4
5word_rdd = sc.parallelize (
["foo", "bar", "foo", "zoo", "aoo"]
)
word_rdd.takeOrdered(3) # ['aoo', 'bar', 'foo']
- takeOrdered(n, key=lambda num: -num): 降序排列,取出前N个元素
key=lambda num: -num只适用数值型的rdd,其实就将每项数值变为负数再排列
1 | rdd=sc.parallelize([10, 1, 2, 9, 3, 4, 5, 6, 7], 2).takeOrdered(3,key=lambda num:-num) |
字符串的rdd排序,如下:1
2
3
4
5
6
7
8
9
10
11word_rdd = sc.parallelize (
["fooo", "bbbar", "ffoo", "zoo", "aoo"]
)
# 按字符长度降序排序再取前3项
word_rdd.takeOrdered(3,key=lambda item:-len(item))
# 按字符长度升序排序再取前3项
word_rdd.takeOrdered(3,key=len)
#按字母升序排序再取前3项
word_rdd.takeOrdered(3)
countByKey(): 对同一key值累计其计数,例如wordcount
1
2
3
4rdd = sc.parallelize([("foo", 1), ("bar", 1), ("foo", 1)])
rdd.countByKey().items()
# dict_items([('foo', 2), ('bar', 1)])以元组的方式返回countByValue():对值分组统计
1
2
3rdd=sc.parallelize([9, 9, 10, 10, 10])
rdd.countByValue().items()
# dict_items([(9, 2), (10, 3)])
- Persistence(持久化)
persist(): 将数据按默认的方式进行持久化
unpersist(): 取消持久化
saveAsTextFile(path): 将数据集保存至文件
- 创建rdd对象时指定分区,
parallelize(c, numSlices=None)
对每个元素都分区1
2sc.parallelize([0, 2, 3, 4, 6], 5).glom().collect()
# [[0], [2], [3], [4], [6]]
glom方法:Return an RDD created by coalescing all elements within each partition into a list
指定两个分区1
2
3rdd=sc.parallelize([10, 1, 2, 9, 3, 4, 5, 6, 7], 2)
rdd.glom().collect()
[[10, 1, 2, 9], [3, 4, 5, 6, 7]]
- 广播rdd
给定一个key为id的字段数据集合,给定其id,求字段对应的value
非广播方式:
1 | apples = sc.parallelize([(1, 'iPhone X'),(2, 'iPhone 8'),(5, 'iPhone 11')]) |
将该数据集合转为字典
1 | apples_dict=apples.collectAsMap() |
给定id集合
1 | ids = sc.parallelize([2,1,5]) |
通过map方法取出ids对应的value
1 | ids.map(lambda x:apples_dict[x]).collect() |
这种方式,在ids与apples_dict之间的映射转换,每一个id查找映射,都需要将ids和apples_dict传到worker节点上计算,如果有100万个id,而且apples_dict是个超大字典,那么就需要进行100万次上传worker再计算结果,显然效率极低,也不合理。
使用广播方式可避免这种情况
将apples_dict转为广播变量
1 | apples_dict_bc=sc.broadcast(apples_dict) |
给定id集合1
ids = sc.parallelize([2,1,5])
id对应的value,使用apples_dict_bc.value[x]这个广播变量,获取id对应的value
1 | ids.map(lambda x:apples_dict_bc.value[x]).collect() |
在开始计算时,apples_dict_bc会传到worker node的内存上(如果数据集合太大,有部分数据则存在磁盘)。之后worker 可以一直使用这个“常驻内存广播变量”处理映射任务,即使有100万个id,客户端只需要把id传到worker即可,这个大apples_dict_bc数据集合则无需再传送到worker,大大减少时间。
- 累加器accumulator:
创建测试数据集
1 | rdd = sc.parallelize([2,3,1,4,5]) |
创建accumulator累加器total,用于累加数集合
1 | total=sc.accumulator(0) |
创建accumulator累加器counter,用于计数
1 | counter=sc.accumulator(0) |
使用foreach,对每一项都使用total累计该元素的值,counter累加已处理的元素个数,注意:counter这个accumulator变量是自增1
1 | rdd.foreach(lambda item:[total.add(item),counter.add(1)]) |
输出:1
2total.value # 15.0
counter.value 5
完整的wordcount示例
1 | import pyspark |
查看存放的输出结果,计算结果的输出文件放在part-00000这个文件,而_SUCCESS文件是无内容的。
1 | [root@nn opt]# ls word_count_output/ |
3、基于PySpark和ALS的电影推荐流程
本节内容参考书籍pdf版本《Python spark2.0 Hadoop机器学习与大数据实战》的电影推荐章节。
(有一点需要指出的是:该书的作者似乎为出书而出书,在前面十来章内容,冗长且基础,大量截图以及table,其实大部分内容可言简意赅。但他们似乎为了出书为了销量,需把这本书打造“很厚,页数多,专业技术书籍”的印象,但其精华只有后面关于pyspark.mllib机器学习示例的内容。)
数据集背景
数据源:https://grouplens.org/datasets/movielens/
这里有非常详细的电影训练数据,适合项目练手
数据信息:
MovieLens 100K
movie ratings.
Stable benchmark dataset. 100,000 ratings from 1000 users on 1700 movies
数据样例结构:1
2
3
4[root@nn ml-100k]# ls
allbut.pl u1.base u2.test u4.base u5.test ub.base u.genre u.occupation
mku.sh u1.test u3.base u4.test ua.base ub.test u.info u.user
README u2.base u3.test u5.base ua.test u.data u.item
有关数据结构的说明,可以查看README文件,例如u.data:4个字段,user id | item id | rating | timestamp.
1 | 196 242 3 881250949 |
读取用户数据
探索基本数据
1 | user_rdd=sc.textFile("file:///opt/ml-100k/u.data") |
因ALS入参为3个字段,故只需取出user_rdd前3个字段的:用户id,产品id以及评分:1
2
3
4raw_rating_rdd=user_rdd.map(lambda line:line.split('\t')[:3]) # 每行分割后为一个包含4个元素的列表,取前3项即可
raw_rating_rdd.take(2)
输出:
[['196', '242', '3'],['186', '302', '3']] # 注意,每个item是列表
ALS训练数据格式的入参为一组元组类型的数据:Rating(user,product,rating),过还需做以下转换1
2
3
4rating_rdd=raw_rating_rdd.map(lambda x:(x[0],x[1],x[2]))# x[0],x[1],x[2]对应用户id,电影id,评分
rating_rdd.take(2)
输出:
[('196', '242', '3'), ('186', '302', '3')]# rdd的每个item为元组类型
查看不重复的用户总量:
1 | total_users=rating_rdd.map(lambda x:x[0]).distinct().count() |
查看不重复的电影总量(同上):
1 | total_moves=rating_rdd.map(lambda x:x[1]).distinct().count() |
训练模型
大致处理流程:读取文件=>user_rdd=>raw_rating_rdd=>rating_rdd,这里rating_rdd的格式就是ALS训练数据的格式Rating(user,product,rating),然后再用ALS.train,训练结束后,就会创建模型对象MatrixFactorizationModel
这里简单介绍ALS算法:Alternating Least Squares matrix factorization,其实就是(交替)最小二乘法,这里为何使用ALS?因为它同时考虑了User和Item两个方面,即即可基于用户进行推荐又可基于物品,所以适合推荐型的场景,模型一般如下: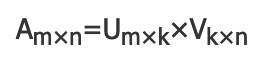
原始协同矩阵是一个m*n的矩阵,是由mk和kn两个矩阵相乘得到的,其中k<<m,n,U表示用户矩阵,V表示商品矩阵,k为U、V矩阵的的秩。学过线性代数应该知道A*B=C,两个矩阵相乘的结果,这就是所谓协同矩阵。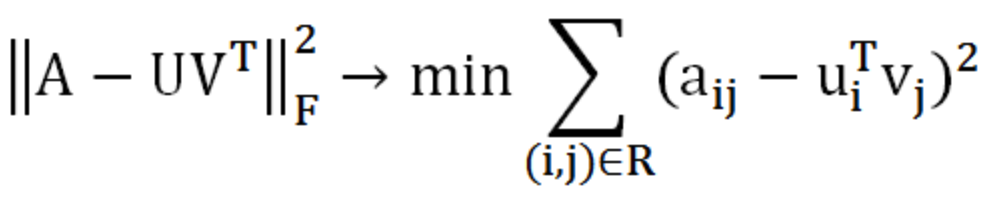
协同推荐就等同于C=A*B矩阵分解,矩阵分解(协同推荐矩阵是一个稀疏矩阵,因为不是所有的用户都对产品评分)最终又可以转换成了一个优化问题。将用户u对商品V的评分矩阵分解为两个矩阵:一个是用户对商品隐含特征的偏好矩阵,另一个是商品所包含的隐含特征的矩阵。在这个矩阵分解的训练过程中,评分缺失项得到了填充,那么这个填充的项就可以根据用户ID进行推荐。
更详细内容可以参考这两篇文章:文章1、文章2
1 | from pyspark.mllib.recommendation import ALS |
ALS.train(ratings,rank,iterations=5,lambda_=0.01)
ratings:训练数据集合,就是上面提到的Rating(user,product,rating),也即是rating_rdd这个经过预处理的数据集
一句完成训练:1
2model=ALS.train(rating_rdd,10,10,0.01)
model# <pyspark.mllib.recommendation.MatrixFactorizationModel at 0x7f3159bc8048>
该模型对象有几个属性:
model.rank # 10 分解为稀疏矩阵的秩
userFeatures 为分解后的用户矩阵
1 | model.userFeatures().take(2) |
productFeatures为分解后的电影(产品)矩阵
1 | model.productFeatures().take(2) |
调用已训练的模型
model已经封装好几个常用的方法,api使用简便1
2
3
4
5Signature: model.recommendProducts(user, num)
Docstring:
Recommends the top "num" number of products for a given user and
returns a list of Rating objects sorted by the predicted rating in
descending order.
例如给用户199推荐前5部电影
1 | model.recommendProducts(199,5) |
这个结果表示,rating值越大,越排在越前面,代表更为优先推荐,首先推荐给用户199的为854这部电影
根据用户ID:199和电影ID:854,查询预测评分:
1 | model.predict(199,854) # 10.774026140227157 |
使用用得更多的场合是:将某部电影推荐给感兴趣的用户,可通过model.recommendUsers得出这些用户,例如,将电影ID为154,推荐给前10个用户
1 | model.recommendUsers(154,10) |
可以快速得出对电影ID为154最感兴趣的前10个用户,不过在推荐的信息里面,看不到电影名称,还需关联电影名的数据,从而形成完整的推荐信息。
加载电影详情数据:
1 | move_info_rdd=sc.textFile("file:///opt/ml-100k/u.item") |
查看u.item电影详情表的字段说明,总共有19个字段:
1 | u.item -- Information about the items (movies); this is a tab separated |
作为测试,无需使用全部字段,只需挑出感兴趣的字段即可:电影id,电影名,url
1 | move_splited_rdd=move_info_rdd.map(lambda line:line.split("|")) |
move_map_info_rdd的key就是电影ID,因此只需要关联model.recommendUsers(154,10)输出的Rating(user=133, product=154, rating=6.346890714591231), product id,即可输出完整的推荐信息如下:
给用户id为199的用户推荐3部电影
1 | result=model.recommendProducts(199,5) |
输出:
1 | user:199,moveid:854,move_info:name:Bad Taste (1987) url:http://us.imdb.com/M/title-exact?Bad%20Taste%20(1987),rating:10.774026140227157 |
将model持久化到本地后,再封装为完整的逻辑,方便重新使用
1 | model.save(sc,'/opt/ml-100k/asl_model') # sc为spark程序开头的spark context |
model以一个目录的形式保存,而且还保存了user和product的数据。
1 | [root@nn ml-100k]# tree asl_model/ |
如何加载已训练好的本地模型?使用load方法即可
1 | model.load(sc,'/opt/ml-100k/asl_model') # path为 |
完整代码
将以上的处理流程封装类,便于调用。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71import pyspark
from pyspark import SparkContext as sc
from pyspark import SparkConf
from pyspark.mllib.recommendation import ALS
import os,datetime
class MoveRecommend(object):
def __init__(self,model_path,user_path,move_path,app_name="move_recommend",master="local[*]"):
self.app_name=app_name
self.master=master
self.sc=self.create_spark_context()
self.train_rank=10 # 稀疏矩阵分解的秩
self.train_iter=10 # 迭代次数
self.train_lambda=0.01 # 正则化参数(惩罚因子)
self.user_path=user_path
self.move_path=move_path
self.model_path=model_path
self.model=self.get_model()
def get_time():
d=datetime.datetime.now()
return d.strftime('%M:%S')
def create_spark_context(self):
conf=SparkConf().setAppName(self.app_name).setMaster(self.master)
spark_context=sc.getOrCreate(conf)
return spark_context
def get_model(self):
"""如果给定的目录没有model,则重新训练model,如果已有model,则直接加载使用"""
if not os.path.isdir(self.model_path):
print(f'model not found,start traing at {self.get_time()}')
return self.train_and_save()
return model.load(self.sc,self.model_path)
def train_and_save(self):
"""只用训练集,训练model并持久化到本地目录"""
user_rdd=self.sc.textFile("file://"+self.user_path)
raw_rating_rdd=user_rdd.map(lambda line:line.split('\t')[:3]) # 每行分割后为一个包含4个元素的列表,取前3项即可
rating_rdd=raw_rating_rdd.map(lambda x:(x[0],x[1],x[2]))# x[0],x[1],x[2]对应用户id,电影id,评分
model=ALS.train(rating_rdd,self.train_rank,self.train_iter,self.train_lambda)
model.save(self.sc,self.model_path)
print(f'model training done at {self.get_time()}')
return model
def get_move_dict(self):
"""返回一个字典列表,每个字典存放3个电影详情字段"""
move_info_rdd=self.sc.textFile("file://"+self.move_path)
move_splited_rdd=move_info_rdd.map(lambda line:line.split("|"))
# 提取3个字段,将转为map类型,name:电影名,url:电影ur
func=lambda a_list:(int(a_list[0]),'name:%s,url:%s'%(a_list[1],a_list[4]))
move_map_info_rdd=move_splited_rdd.map(func).collectAsMap() #move_map_info_rdd 已经是字典类
return move_map_info_rdd
def recommend_product_by_userid(self,user_id,num=5):
"""根据给定用户id,向其推荐top N部电影"""
result= self.model.recommendProducts(user_id,num)
move_dict=self.get_move_dict()
return [(r.user,r.product,move_dict[r.product],r.rating) for r in result]
def recommend_user_by_moveid(self,move_id,num=5):
"""根据给定电影ID,推荐对该电影感兴趣的top N 个用户"""
result=self.model.recommendUsers(move_id,num)
move_dict=self.get_move_dict()
return [(r.user,r.product,move_dict[r.product],r.rating) for r in result]
调用:1
m=MoveRecom(model_path='/opt/ml-100k/costom_model',user_path='/opt/ml-100k/u.data',move_path='/opt/ml-100k/u.item')
输出训练时间:
model not found,start traing at 26:45
model training done at 27:06
项目难点说明
上面的例子只是给出demo流程,而且数据已准备,但如果针对实际项目,则需要你处理以下两个主要难点:
(1) 训练数据的获取、整理和加工,并将这一流程自动化。
(2)模型的训练,以及根据新数据重新训练模型,以保证模型推荐效果最优,并将这一流程自动化。
至于其他工作,例如web 层面的开发,以及Apps或者说底层数据的存储,对于全栈开发者来说,并无大碍,只是需要耗费更多精力而已。
小结
本文给出了较为入门的基于PySpark实现的推荐类的业务流程,该逻辑其实是离线的模式:训练数据已经加工好,模型训练也没有进行深度调优。事实上,如果将其作为一个生产可用项目来实施,需将大数据生态圈相关技术栈以及web 开发进行整合,此类项目的架构设计一般有下面三部分:
- 需推荐的业务数据(包括训练集和测试集)收集、计算、存储:大数据生态圈相关技术栈实现
- 模型训练方面:离线存储PySpark计算后生成的训练模型,而且需要定时训练和更新该模型文件,以便保持最优模型。
- 以web api的方式提供推荐数据:为BI或者其他应用以get、post的方式提供推荐数据,例如post一个用户ID,返回相应的推荐条目
以下简要说明两种基本架构图:
第一种:适合数据量不大,几个节点组成的小型“大数据”服务 这种架构较为简单,数据源本身已经存储在各个业务的原有数据库中或者日志文件,开发者无需借助hadoop存储组件,自行实现数据源抽取模块,接着只需PySpark读取这些数据并训练成模型文件即可,模型文件管理可以通过定时训练更新,最后通过web API的形式为上层应用提供推荐或者匹配记录。
这种架构较为简单,数据源本身已经存储在各个业务的原有数据库中或者日志文件,开发者无需借助hadoop存储组件,自行实现数据源抽取模块,接着只需PySpark读取这些数据并训练成模型文件即可,模型文件管理可以通过定时训练更新,最后通过web API的形式为上层应用提供推荐或者匹配记录。
需要注意的是:构建web API方式这里用了Python栈,当然可用Java栈或者Go栈
第二种:适合数据量大的中大型大数据服务 此类架构适合那些几十GB到几百GB级别甚至是TB级别的分布式大数据节点集群,此类场景需引入hadoop相关生态圈的技术栈,用于处理大量属鸡的存储和计算:Flume、Kafka、HBase、Hive,在计算层提供分布式的Spark组件支撑离线模型计算。
此类架构适合那些几十GB到几百GB级别甚至是TB级别的分布式大数据节点集群,此类场景需引入hadoop相关生态圈的技术栈,用于处理大量属鸡的存储和计算:Flume、Kafka、HBase、Hive,在计算层提供分布式的Spark组件支撑离线模型计算。