首先介绍Java7版本的HashMap正常put和扩容过程对应的代码
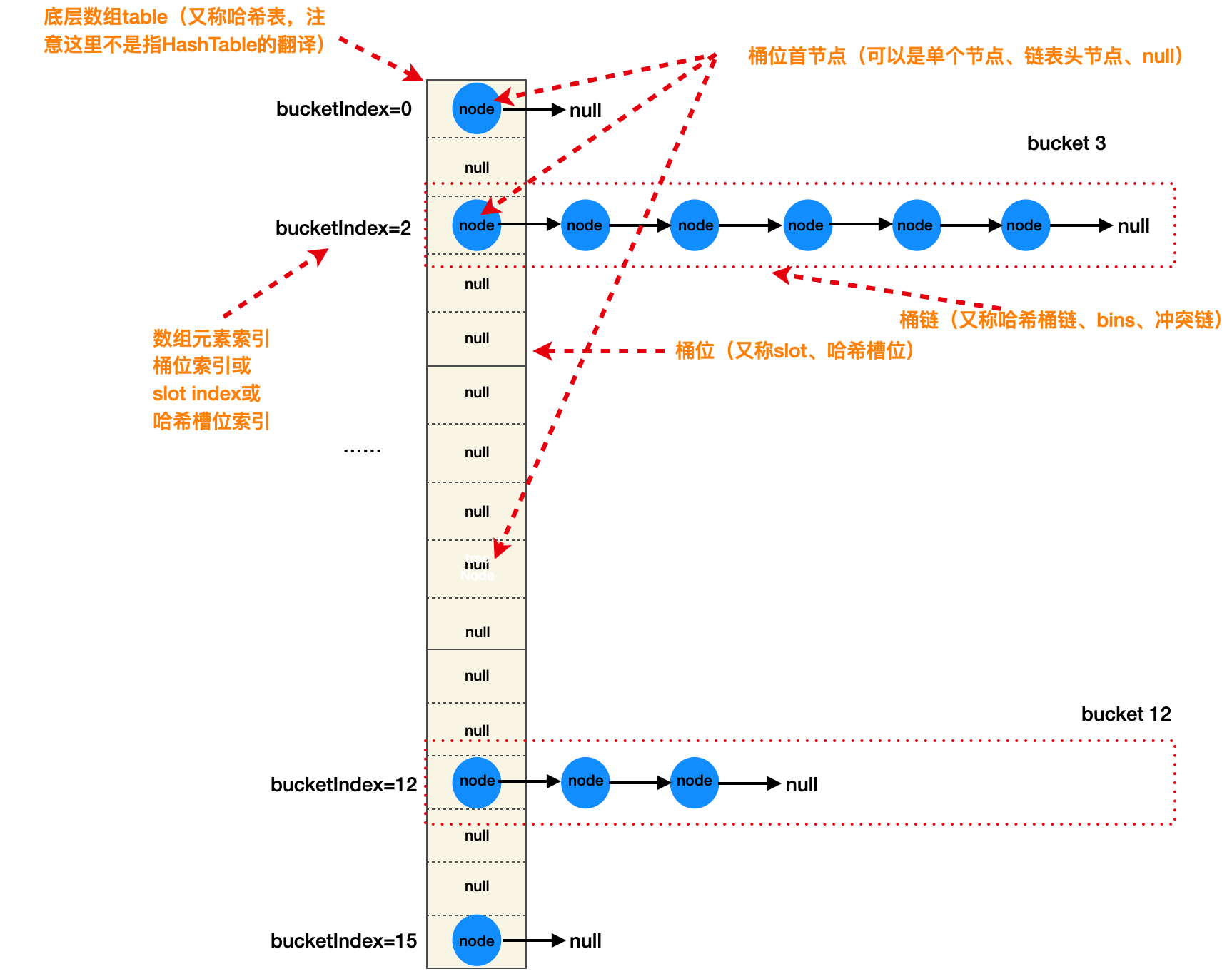
内部结构
可以清晰看到1.7版本的HashMap内部结构是数组+冲突链,HashMap里面”桶”的字眼或者说法也是来源于Java7及之前版本的说法,在Java8它被称为bins
源码说明
在源码查看方面,建议开发环境同时配置jdk7和jdk8,IDEA创建两个project,分别选择不同的jdk即可方便查阅和对比两个版本的源码。此外,如果已经深度理解了jdk8的HashMap设计原理,那么jdk7的HashMap的源码则更容易看懂。
1.1 put方法
1 | public V put(K key, V value) { |
1.2 createEntry
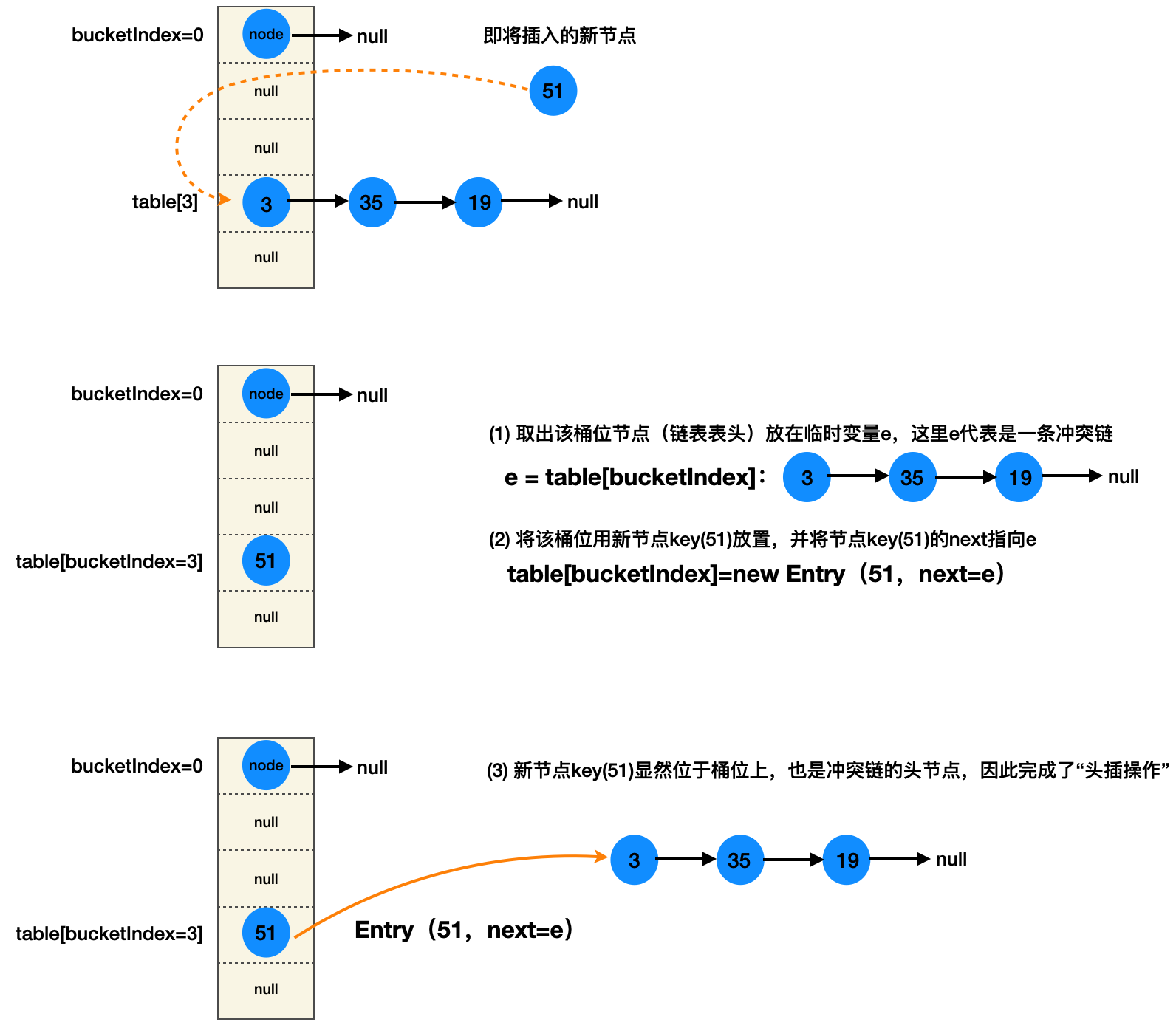
createEntry里面是一个很经典的情况:从这里可以看出java7的HashMap的冲突链每次都是链表头部插入新节点(头插法)这个设计在后面的resize也用上。而java8的是在链表使用尾插法:e.next=newNode
1 | void addEntry(int hash, K key, V value, int bucketIndex) { |
为何设计为头插法?
个人的思考:
1、设计者考虑到新添加的节点有可能在未来时刻会被优先读,因此每次将新节点插在链表头部,可以快速被下次访问到,避免冗余遍历链表的操作,类似局部性原理或者类比FIFO思想的设计
2、头插法避免了对冲突链表遍历,在一些场合下能提升性能。如果采用尾插法,while(e!=null)遍历链表后,找到链表尾节点,再添加新节点到链表尾部,显然遍历消耗性能。
3、头插法设计也使得代码只需要2行,逻辑直观清晰,(体现设计者高度代码洁癖?),createEntry对比java8的putVal,putVal的添加节点可不止几行代码!
头插法createEntry示意图
假设数组容量16,那么对于3、35、19,他们的桶位索引buctketIndex=key.hashCode & (16-1),在这里假设hash计算方式就是直接使用hashCode进行计算,可以推出:数字作为key对应的hashCode就是数字本身。显然计算结果buctketIndex都是3,新增的节点51也将定位到3号位
以上两个方法相对简单
1.3 resize
看看源码说明:Rehashes the contents of this map into a new array with a larger capacity. This method is called automatically when the number of keys in this map reaches its threshold.
这里提到一个Rehashes动词,也即重哈希,也即HashMap扩容
1 | void resize(int newCapacity) { |
重点在transfer方法实现上
1 |
|
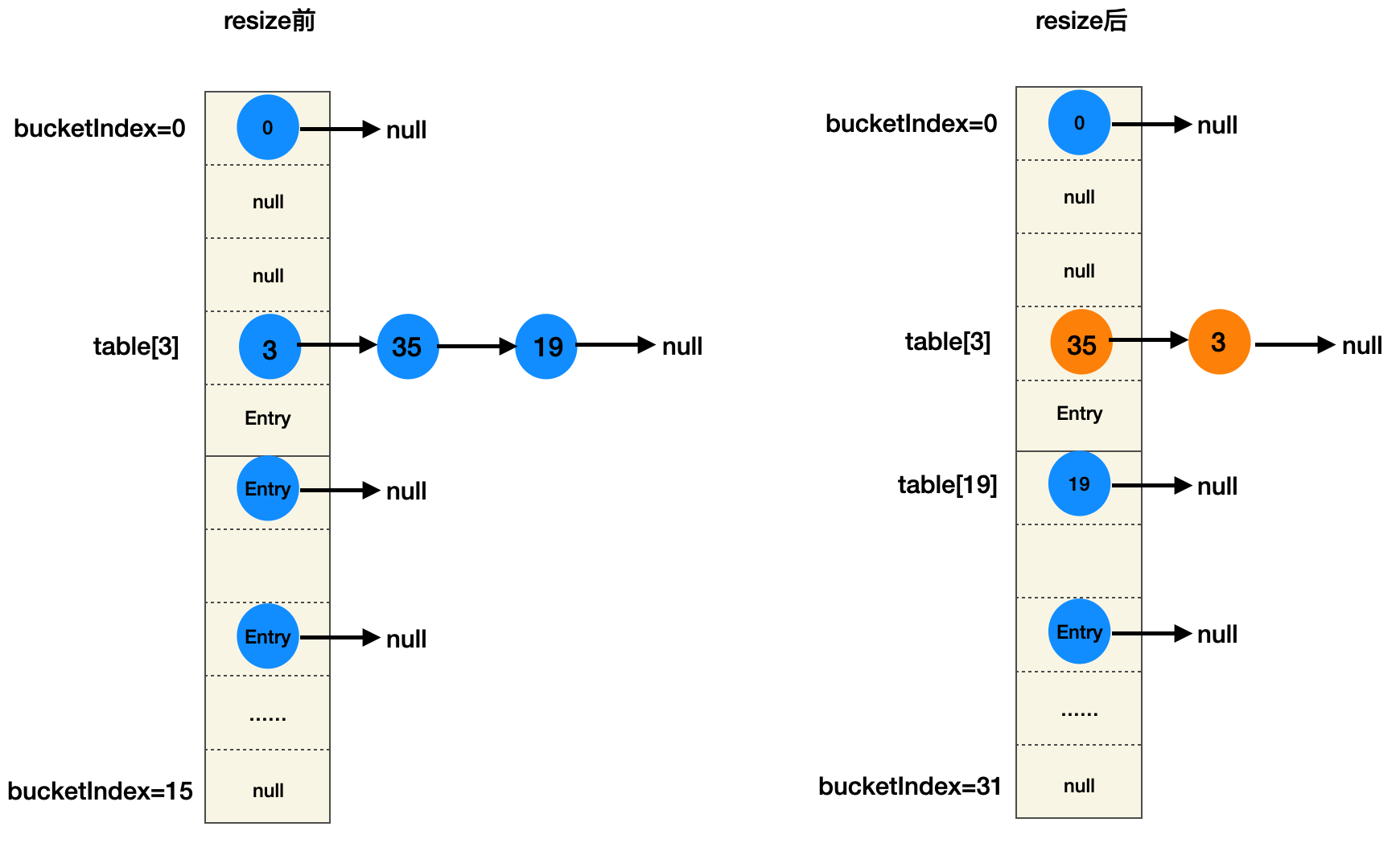
这里也做了一个假设:桶位计算buctketIndex=key.hashCode & (32-1),注意这里32是新数组容量,这不影响分析resize过程,源码的hash算法只是让key更加分散分布在数组所有位置上。
ttransfer里面采用的头插法,根据前面createEntry方法的示意图可得到以下旧表扩容前后图:
根据buctketIndex=key.hashCode & (32-1)可知,3和35这两个还是定位到3号桶位,由于头插法,因此35节点作为头结点,3作为后驱节点,而19被hash到新数组19号桶位。可以看出,Java 7没有红黑树,因此没有treerifyBin树化机制和树转链机制操作unTreeriFy等复杂的方法实现。
以上即是Java7的HashMap基本源码分析,下面看看在多线程情况下resize出现循环链表导致死循环的情况是怎么发生的。
1.3 线程栈及其局部变量内存模型
假设现在两个线程共享使用一个HashMap,在resize方法里面,
1 | Entry[] newTable = new Entry[newCapacity]; |
线程1和线程2分别在自己栈里面创建newTable、e、next局部变量,两个线程的newTable引用都指向共享堆(主存)里面的table对象,如下图所示
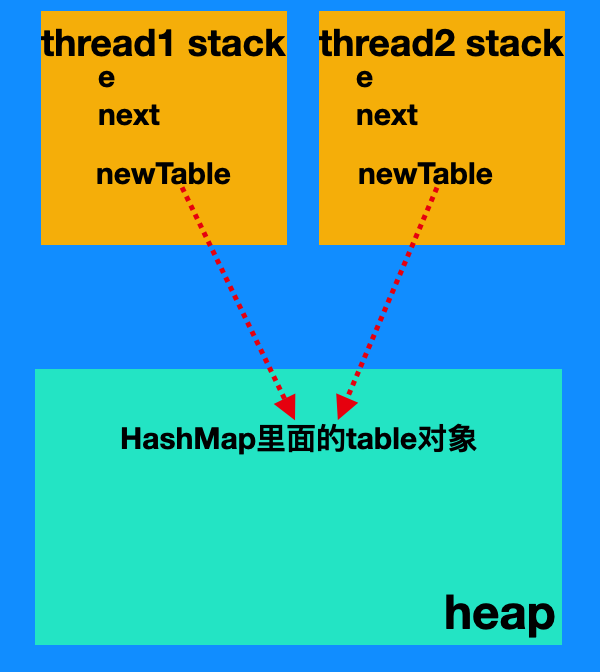
当然这里图并不是JVM内存全貌模型,图不是十分严谨,该图目的是为了下面的循环链表形成过程铺垫基本知识点。
1.4 两个线程的执行流:
以下是线程1、线程2并发扩容执行流的说明,重点在线程1执行完next=e.next之后的扩容行为分析,由于代码逻辑是动态变化,因此这部分内容相对复杂,需要有耐心的跟着线程1和线程2的扩容步骤图所表达的思路,尤其线程1从中断位置继续运行后的逻辑,否则无法理清死循环(循环链表)的形成过程。
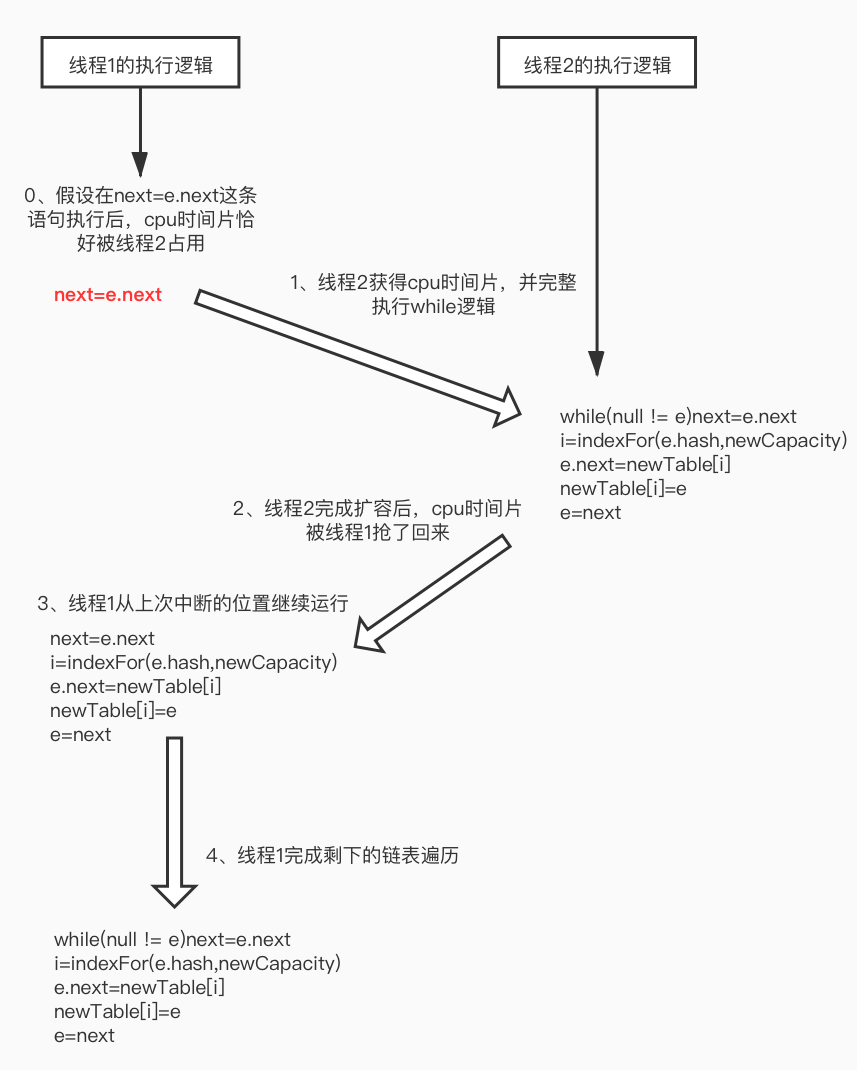
1.5 循环链表形成过程
基本条件说明:
为了易于理解和便于作图,HashMap的数组初始容量为2,key为3和7,且在桶位1已经有冲突链3->7-null,hash计算以及桶位计算采用1.2提到的方法。table扩容后,容量为4,冲突链被rehash到桶位为3,由头插法可知,新数组桶位3的冲突链一定为:7->3->null,其他细节说明,参考图中文字
务必耐心过完每一张图和以下核心逻辑:
1 | next = e.next; |
循环次数与步骤说明:
为了更加清晰理解以下循环图运行过程,在这里给出以下约定,循环次数用“循环n”表示,循环内部的代码用“步骤n”表示,如下所示:
1 | transfer内部while(null != e)循环 // 以下忽略i=indexFor(e.hash,newCapacity)代码行 |
初始table结构

准备并发扩容
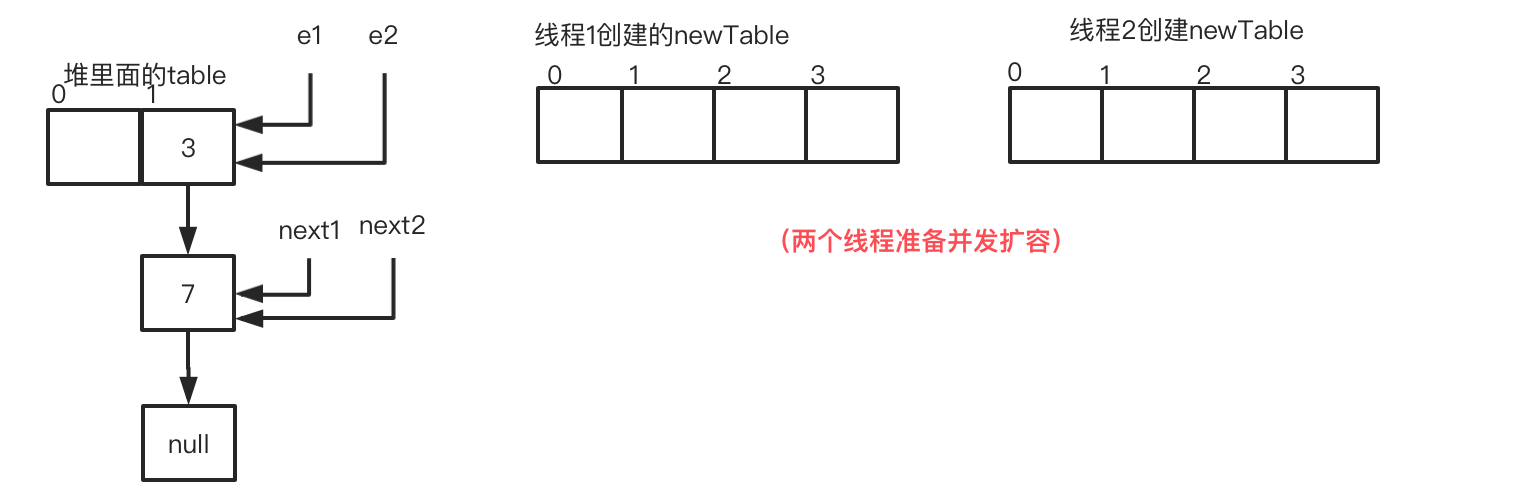
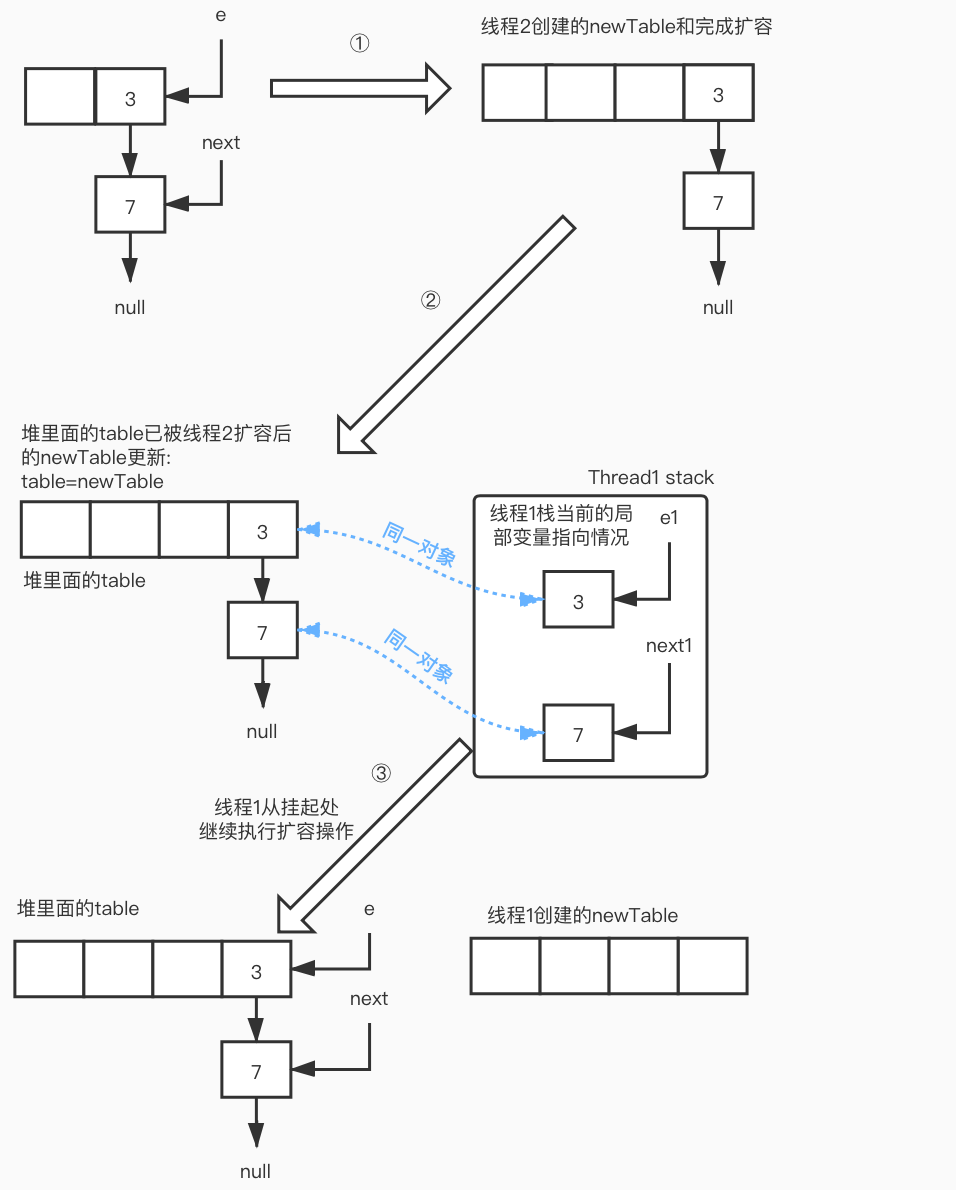
在next=e.next执行完后线程1让出cpu时间片,操作系统调度线程2执行,且线程2完成了扩容
对于线程1的循环进度:循环1-步骤1 next=e.next

这里需要重点观察:线程1栈空间的 e1指向3节点、next1指向7节点的情况,对比线程2的newTable的7 节点和3节点
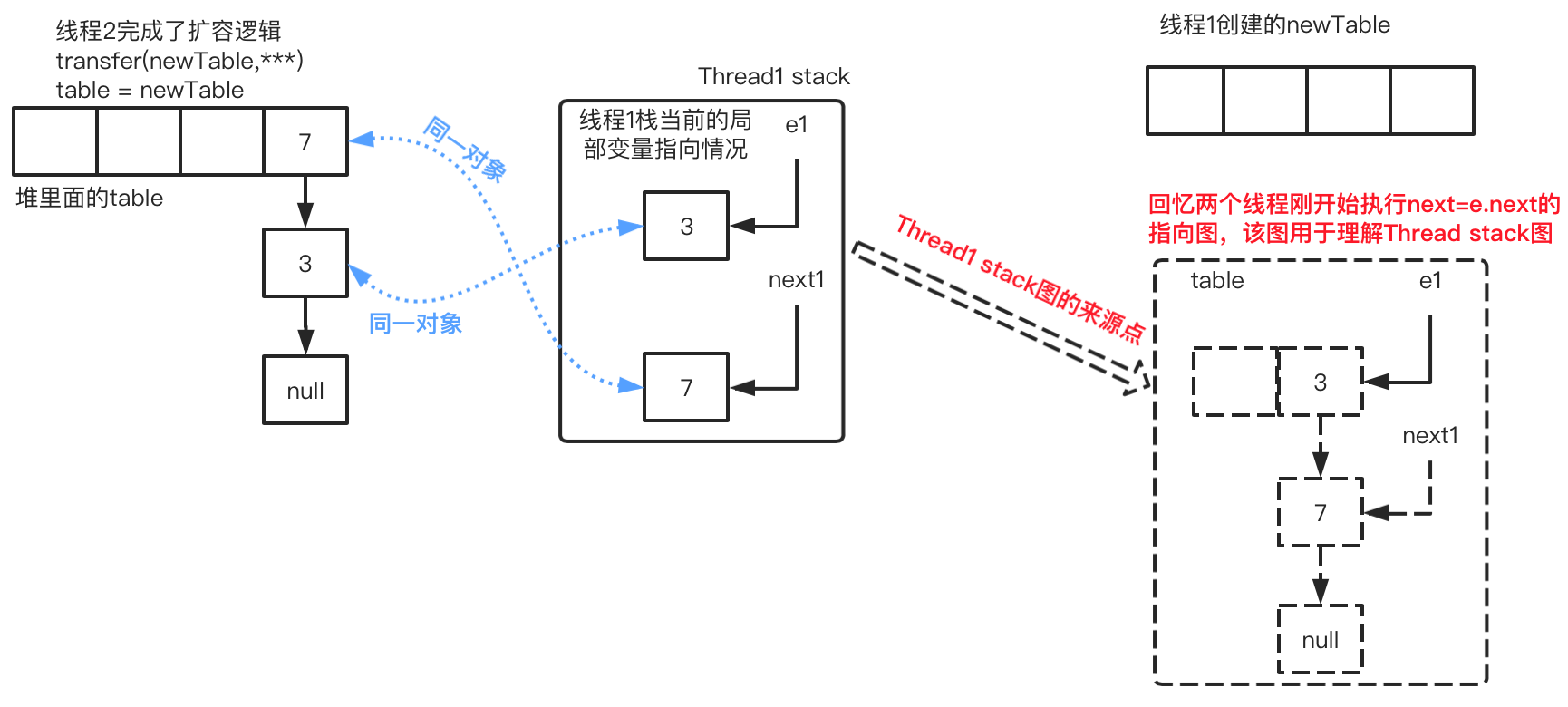
线程2运行结束后,线程1得到cpu时间片接着从上次挂起的地方运行:
(利用线程控制块TCB恢复cpu现场,cpu程序计时器:存放cpu下一条运行的指令,在这里就是指:
i = indexFor(e.hash, newCapacity)。这里更想强调的是后面这行语句:e.next = newTable[i]
此时线程1的循环进度:循环1-步骤2 e.next = newTable[i]
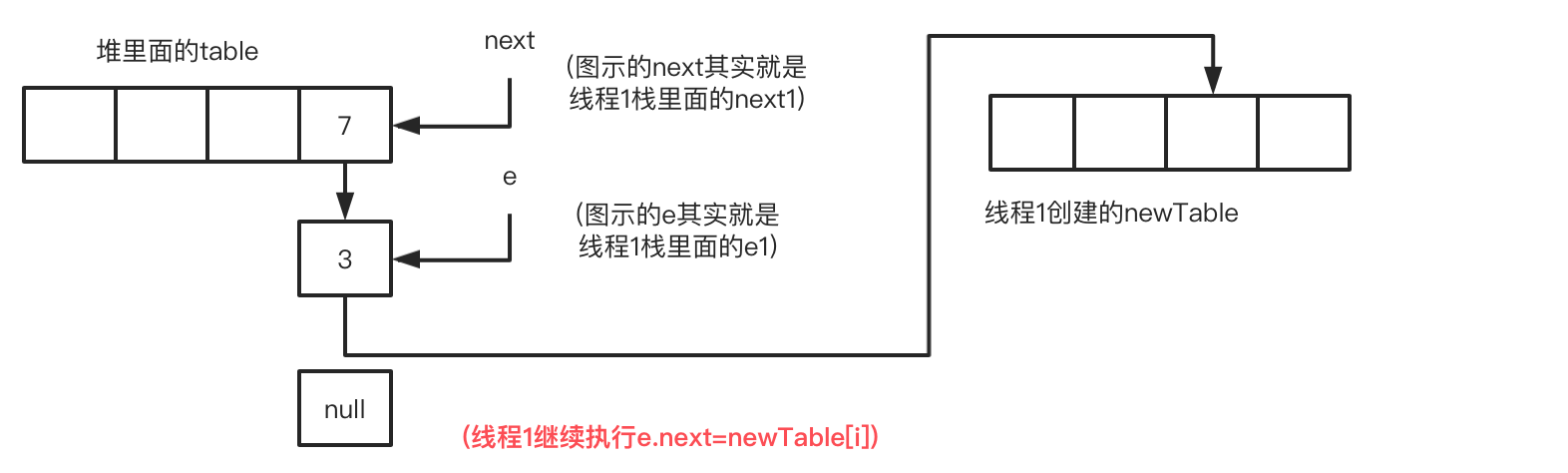
此时线程1的循环进度:循环1-步骤3 newTable[i]=e
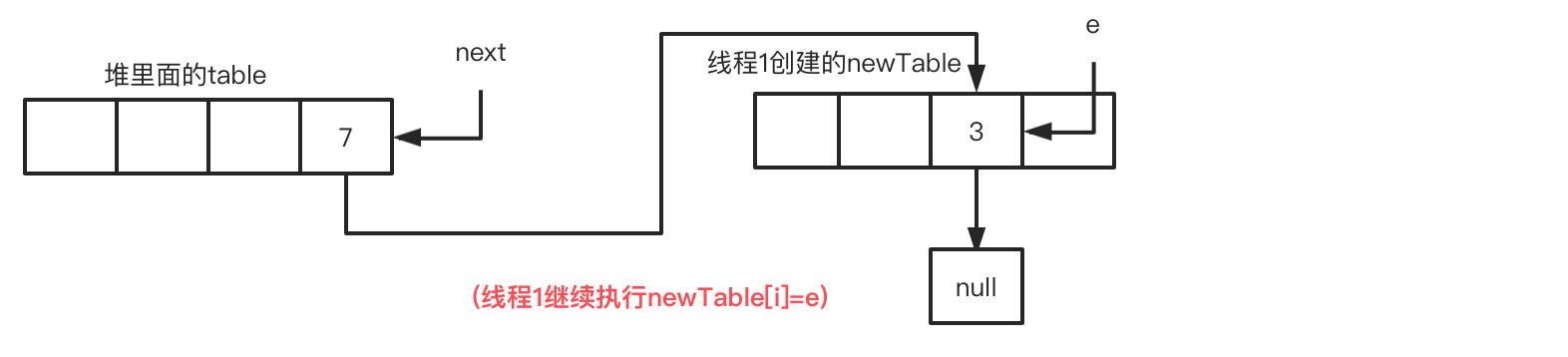
此时线程1的循环进度:循环1-步骤4 e=next,请注意这里next指针指向是table的7,而不是3在newTable指向的null,为何?就是因为循环1-步骤2 图出现的情况。
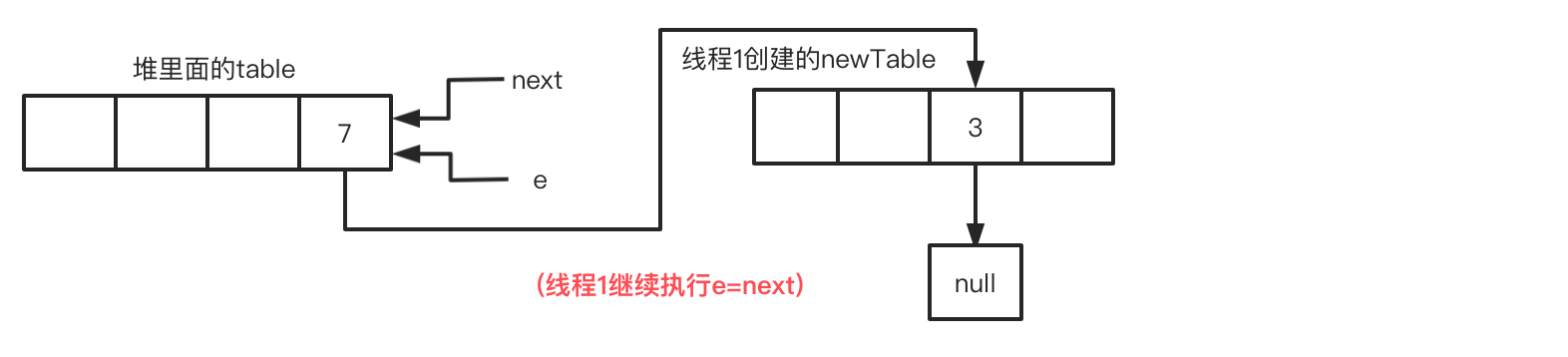
此时线程1的循环进度:循环2-步骤1 next=e.next
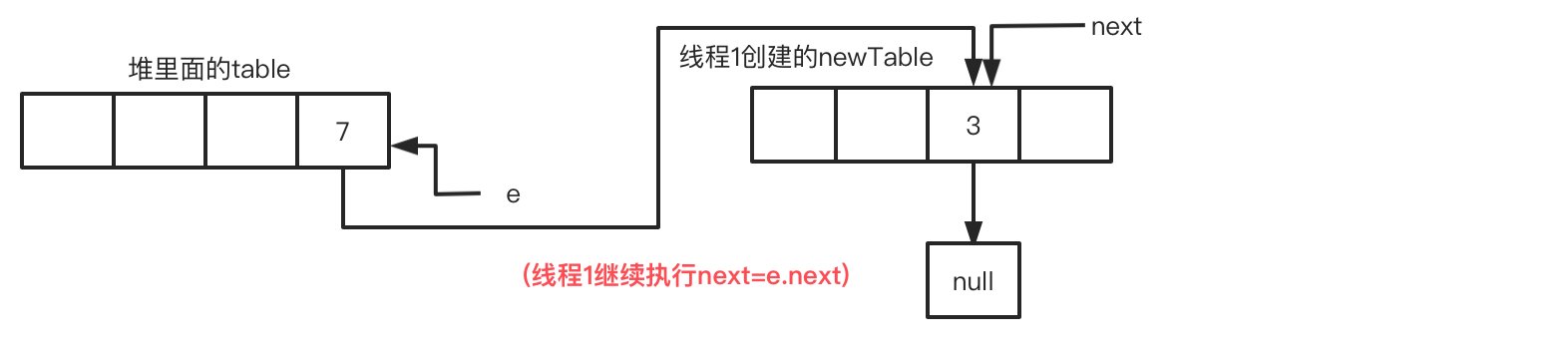
此时线程1的循环进度:循环2-步骤2 e.next=newTable[i],这里很特殊:因为上图已经是7指向newTable[i],
在由于e当前就是7,因此执行e.next=newTable[i]后,还是7指向newTable[i]
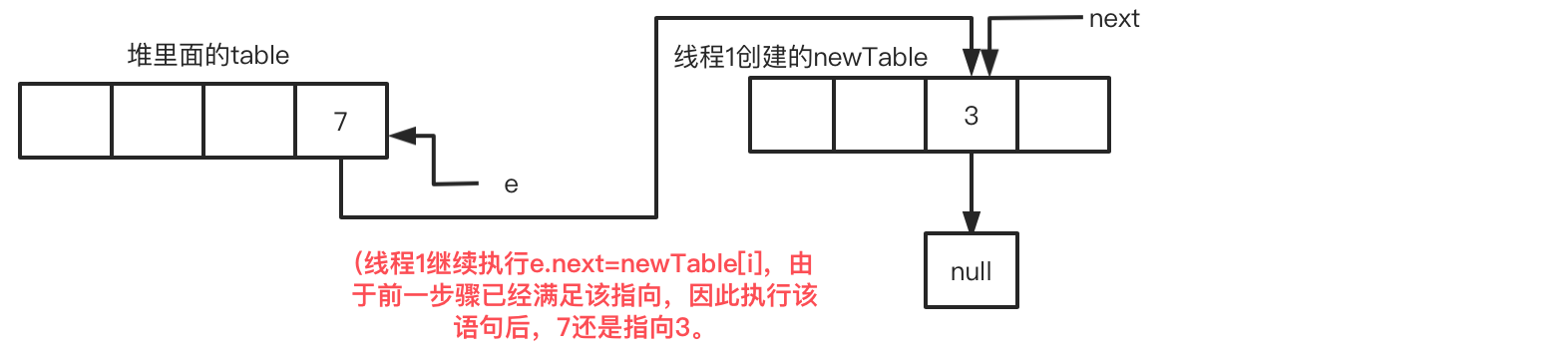
此时线程1的循环进度:循环2-步骤3 newTable[i]=e
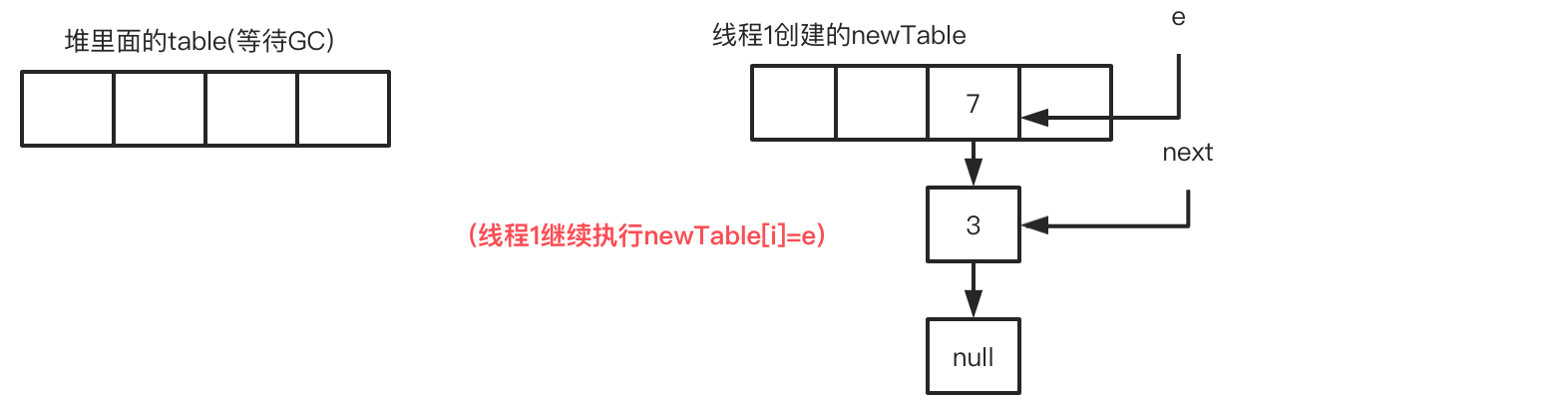
此时线程1的循环进度:循环2-步骤4 e=next
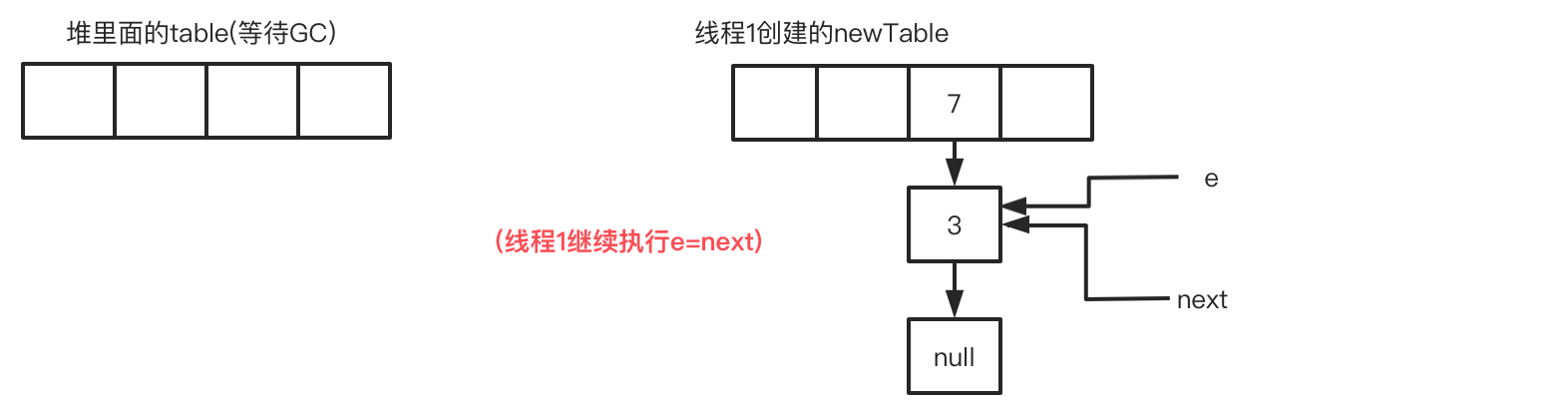
此时线程1的循环进度:循环3-步骤1 next=e.next
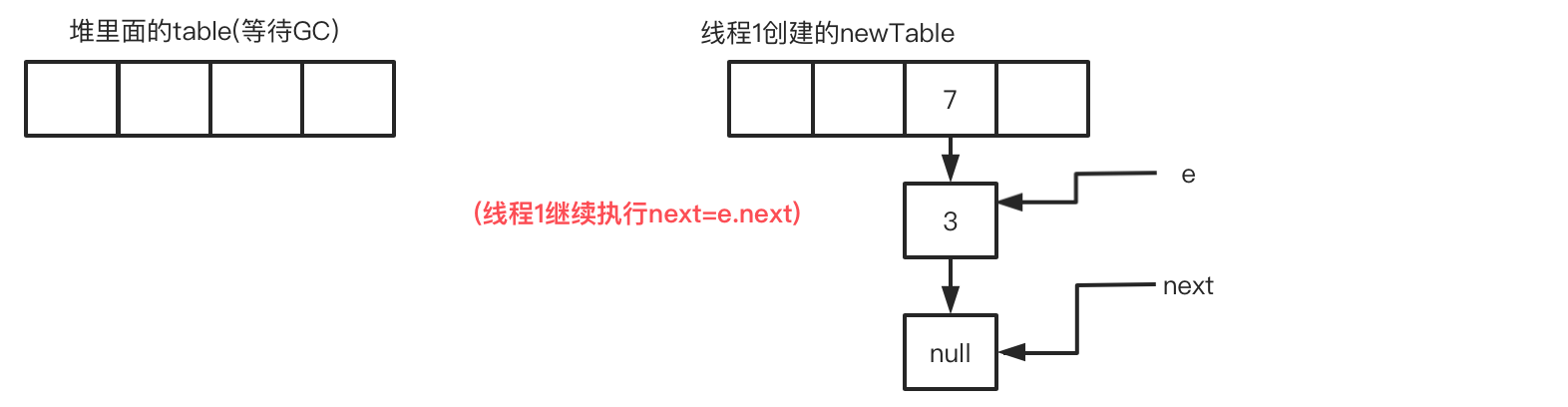
此时线程1的循环进度:循环3-步骤2 e.next=newTable[i],有内味了!在这里开始出现节点间循环指向!
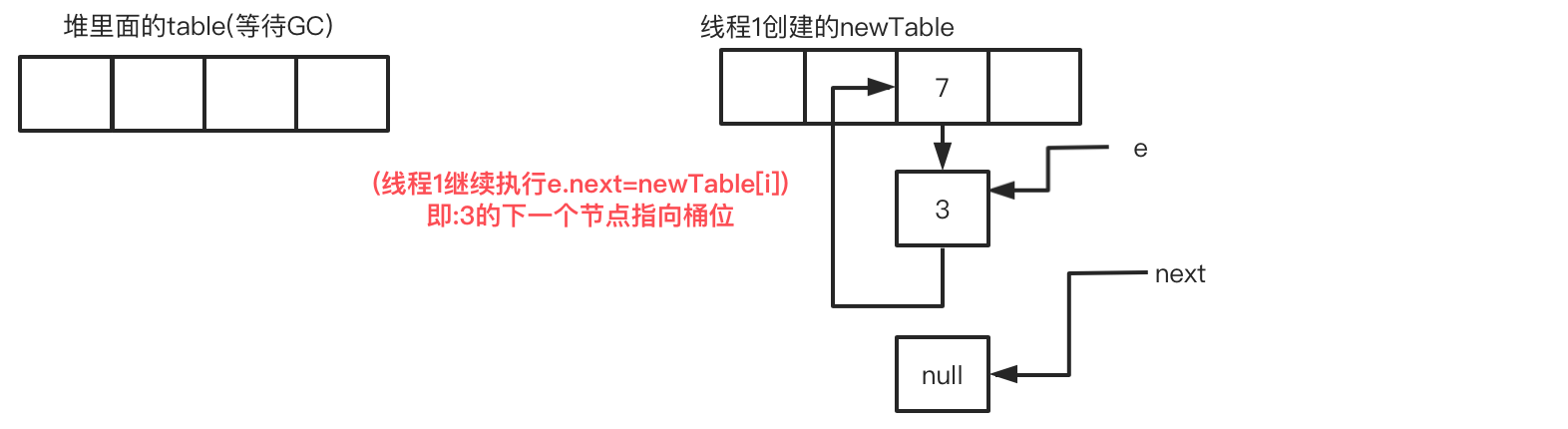
此时线程1的循环进度:循环3-步骤3 newTable[i]=e,循环指向还在!
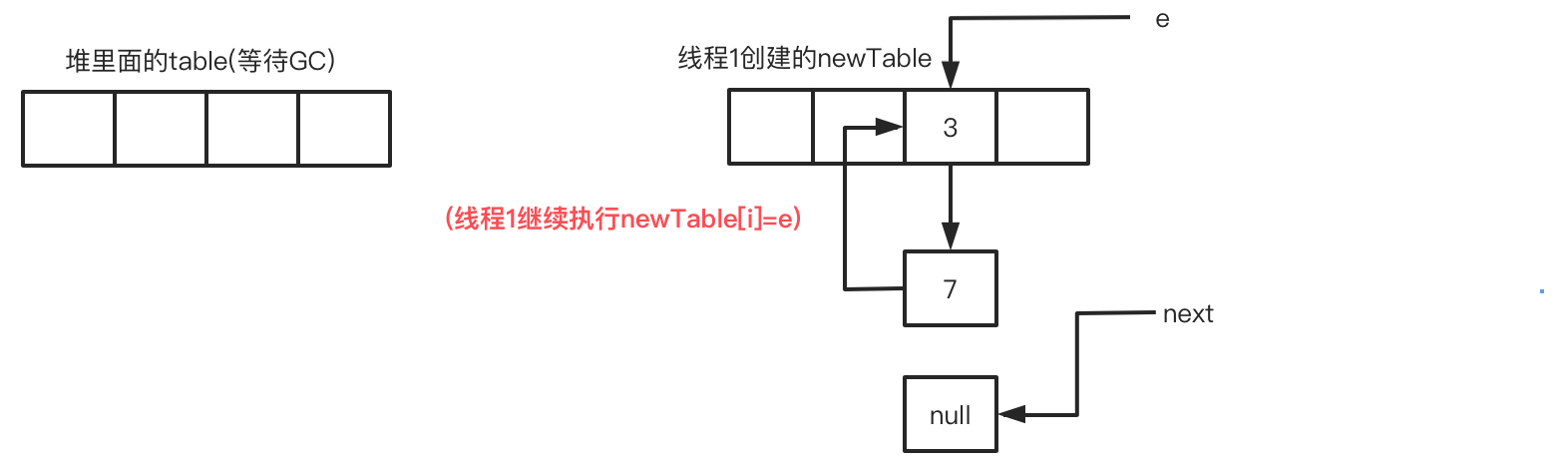
此时线程1的循环进度:循环3-步骤4 e=next
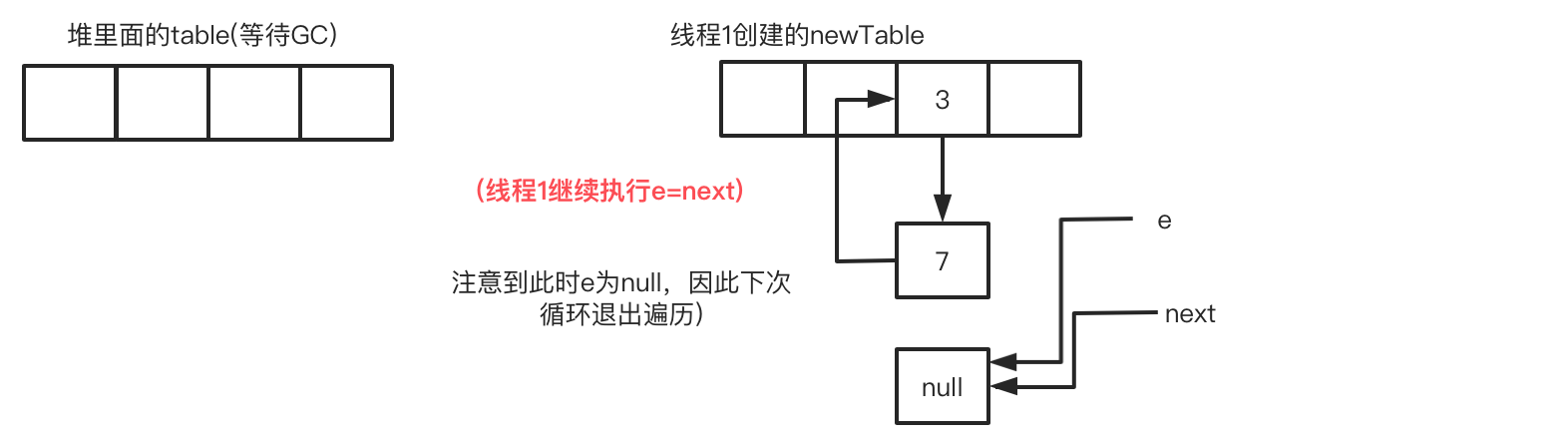
之后循环结束,形成环链总共用了3轮循环,线程1运行结束后,HashMap内部的table已经存在循环链表,此时还不会发生死循环。当下次使用map.get(key),例如15这个key,该循环链表无法找到15这个key,由于链表是循环结构,恰好触发死循环遍历,cpu使用率飙高或者线程退出,查看堆栈可以看到死循环出现在调用方法:transfer
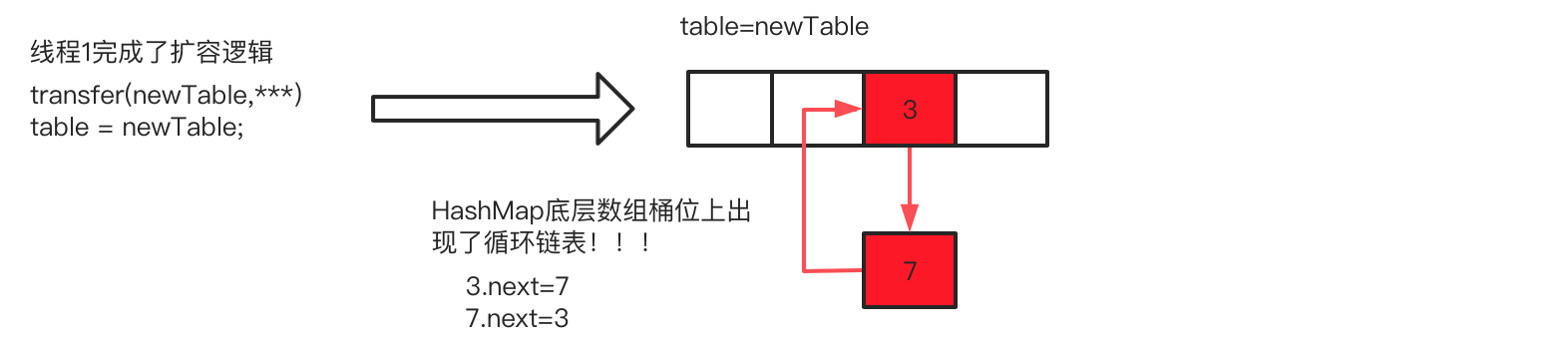
1.6 诱发形成循环列表的根源点分析
从1.5的3次循环(共1+11次步骤)过程可以总结出导致循环链表的关键诱因:
1、头插法会使得扩容后链表顺序相反
2、在1的“助攻”下,线程1执行next=e.next并挂起后,当线程1再次恢复CPU线程执行时,e的指向和next的指向出现了“梦幻的倒换”:
这也反向证明Java8的尾插法链表扩容前后节点顺序保持一致则一定不会出现循环链表,因为对于Java8的HashMap尾插法逻辑:
线程1执行next=e.next并挂起后,当线程1再次恢复CPU线程执行时:如下图所示,可以清楚观察到
1)扩容前后链表的节点顺序保持不变
2) 线程1在挂起处继续执行时,e和next的指向保持不变
小结
从1.6小节的多张图可知,Java7的HashMap形成循环链表的过程需要3次循环共12个步骤,因此如果想直接在大脑中想象环链的构建过程,这当然是困难,其实可通过作图的方式,可以帮助大脑形成“记忆”快照,最终能将这个过程还原出来。(若还不能理解循环链表的形成过程,建议自行作图解析)。