前言
虽然jdk1.7的CHM能够解决非阻塞高并发的读写情况,但它仍然不够理想,例如写并发度受限于Segment数组初始大小,一旦创建就无法再扩容并发度;如果key非常多且分布不均匀,例如都落在同一个Segment位置上,相当于多个线程竞争同一把“全局锁”,CHM“仿佛”退化为HashTable。此外,因为CHM的Segment上使用jdk1.7的HashMap,它的性能显然没有jdk1.8的HashMap强,jdk1.7resize扩容处理时只能单线程完成扩容操作,jdk1.7计算size方法可能要对每个Segment加阻塞锁,基于以上jdk1.7的CHM缺点,Doug Lea重新设计新版本的CHM,其源代码行数总共6312行,性能确实高了,但代价是代码逻辑的复杂度要高出很多。
理解本文所有源码分析以及相关技术都需要读者已经掌握1.8/1.7HashMap、1.7 CHM、Unsafe、CAS这些进阶知识,否则难以消化相关知识,可以提前阅读本博客相关文章:
(以下“CHM”表示ConcurrentHashMap简写)
数据结构图示
分为普通状态下(非扩容期间)和扩容期间
(1)CHM非扩容时,也即普通正常状态下的内部数据结构图:
可以看到跟jdk1.8的HashMap数据结构不同的地方:CHM用了一个称为TreeBin的节点作为桶位头节点,不是HashMap的TreeNode:
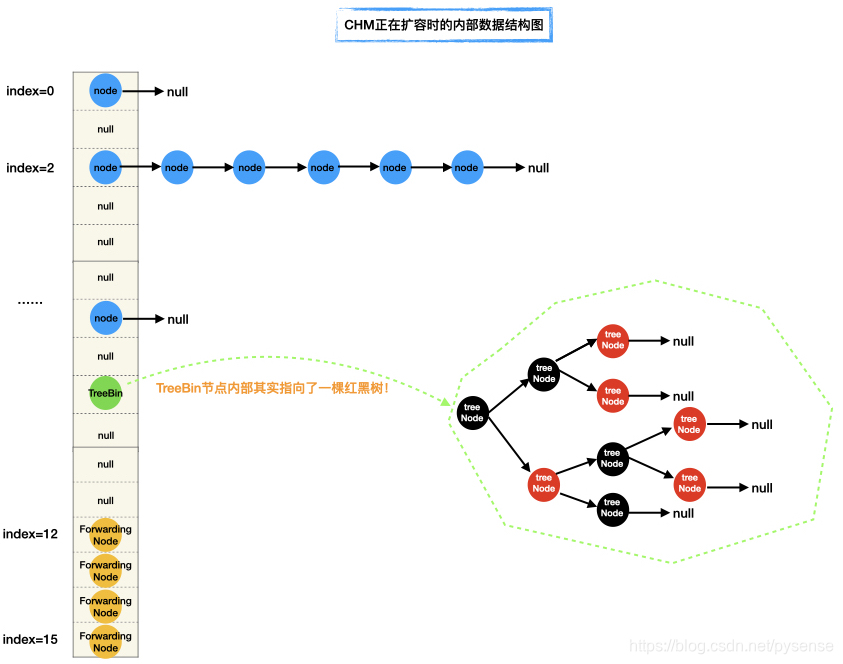
(2)CHM正在扩容时的内部数据结构图:
可以看到正在扩容时的内部节点结构,数组尾部的一些桶位头节点放入了ForwardingNode节点。
其实还有一个情况,以上两张图也没有展示出来:当CHM调用computeIfAbsent或者compute方法来插入系节点时,会在桶位上放置一个ReservationNode用于占位操作,本博客也有关于相关深度分析的文章
重要成员变量说明
CHM重要常量
1 | /* ---------------- Constants -------------- */ |
重要成员变量
1 | /* ---------------- Fields -------------- */ |
put方法
关于spread方法、tableSizeFor方法、comparableClassFor方法、compareComparables方法可以参考jdk1.8的HashMap,本文不再赘述。
put方法最适合作为源码分析入口,如下
1 | ConcurrentHashMap<Integer, String> map = new ConcurrentHashMap<>(); |
put方法内部调用的是putVal方法
1 | public V put(K key, V value) { |
对于CHM来说,put一个key到桶桶上会有以下几种情况:
1、table为空 2、桶位为空 3、桶位是一条冲突链 4、桶位是一个treeBin节点 5、桶位是一个ForwardingNode节点(表示有其他线程正在扩容) 6、桶位是一个ReservationNode节点:表示有其他线程正在调用computeIfAbsent或者compute方法来插入在该桶位插入节点,注意同一桶位的同一时刻,5和6是不会同时发生在,两个情况都是表达插入节点的逻辑。
因此put主体逻辑设计主要分为以下7个步骤:
1、如果tab为空,那么进行table初始化,该方法里面使用自旋+CAS让线程自己竞争初始化权
2、如果key所定位的桶位头节点f为空节点,线程使用CAS竞争将key节点插入到该桶位中
3、如果key所定位的桶位头节点hash为-1,也即表示该桶位的节点是个fwd节点,说明当前CHM正在扩容,那么当前put线程遇到这个节点会让去帮助扩容线程。
4、若不是以上1~3三种情况,那么先使用synchronized锁在该桶位,如果该桶位上一条冲突链,遍历该链插入key,如果该桶位上是一个treeBin,说明桶位已经是一棵红黑树,则按红黑树插入节点方法来插入key
5、判断key插入的链表长度是否大于等于8,来决定是否需要树化
6、将CHM的节点总数size加1(采用并发计数器累加)
7、判断节点总数是否达到扩容阈值而进行扩容
本文重点分析1-6的设计,第7点是扩容逻辑,由于扩容逻辑相对复杂、内容丰富,需要单独起一篇文章研究。
1 |
|
如果对jdk1.8 HashMap有深入研究的话,其实CHM的put本身设计逻辑并不难理解,而最复杂且精妙的设计反而是put方面里面的辅助方法:initTable方法、helpTransfer方法、transfer方法、addCount方法、fullAddCount方法,每一个方法无不体现JUC并发代码的精巧设计。
在前面的“CHM重要常量”,特意将以下三个变量放在此来说明它们的作用,分别代表三种节点的哈希值:
1 | static final int MOVED = -1;// ForwardingNode(扩容期间需要用到)的哈希值 |
在put一个节点需要判断当前桶位节点类型,其中用到以下逻辑,其中只要头节点的哈希值fh>=0,我们就可以认为它是一条链表(或者单节点),所以可以使用遍历方式去put入key
1 | synchronized (f) { |
如果头节点哈希值小于0也即:-1,-2,-3,它们代表第三种类型节点,因此还需要进一步判断f节点是否为TreeBin节点,因此有
if (f instanceof TreeBin), 为何不设计为: if(fh==TREEBIN),个人认为:
纯粹是为了源代码的可读性,因为我们put一个key到桶位前,更关心关心的是key所在桶位的“节点”是什么类型,当开发者看到if (f instanceof TreeBin),自然就会理解为:如果当前桶位头节点是一个TreeBin节点。
而如果写成if(fh==TREEBIN), 显然就没上面的理解来得更加“人性化、可读性高”
initTable方法
在重要成员变量里面,有一个叫sizeCtl的东西,在这里才能很好理解的它的作用:
initTable总体设计逻辑:例如线程A使用自旋+CAS去竞争table初始化权,CAS成功,则sizeCtl值会被改为-1表示“已成功抢到锁”,其他线程看到sizeCtl=-1就不再争抢初始化权而是让出cpu时间片。线程A接着完成new table初始化操作,并将sizeCtl设为当前table的扩容阈值:
1 | private final Node<K,V>[] initTable() { |
addCount方法
首先回想jdk1.8 HashMap的put方法:插入key后,对size自增1,如果size超过阈值则对HashMap底层table进行2倍扩容:
1 | final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) { |
那么addCount方法也是类似的设计思想:
先对size加1,然后根据size节点总数判断是否需要扩容。
但这里最复杂的地方在于:多线程并发情况下,如何正确实现对size原子加1?addCount及其内部的fullAddCount方法可以完成此任务,代价是:程序设计相对复杂(设计思路十分精巧,值得在日常项目引入),设计原理如下图所示: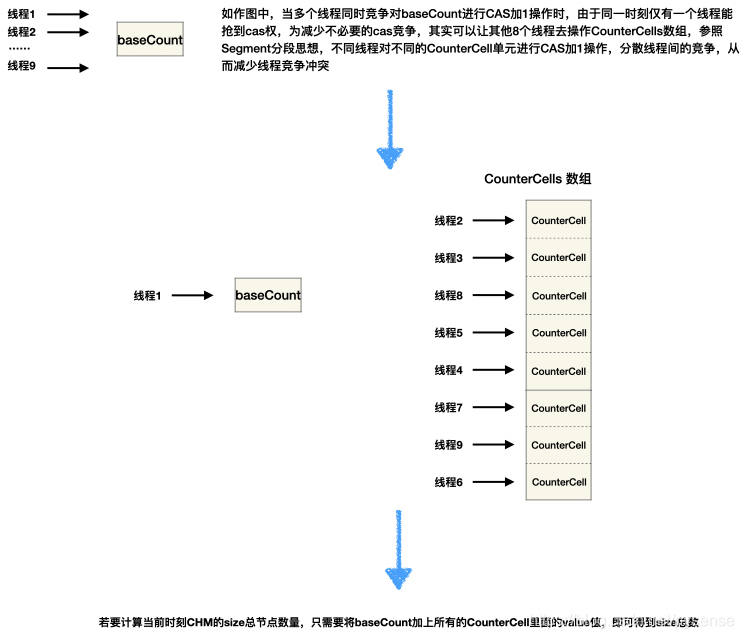
当线程竞争不激烈情况下,通过自旋+cas对baseCount进行加1计数
当线程竞争十分激烈的情况下,有一部分线程很幸运能够抢到cas权力成功对baseCount加1,而剩下对baseCount加1cas失败的线程,它们就会创建一个CounterCells计数的数组,然后线程给对应自己的桶位Cell对象进行cas加1操作,这样一来就实现了“线程分流”,减少竞争。
最后统计总数时,将baseCount和CounterCells数组每个桶位的计数值累加起来,就是size的大小。该原理对应的源码如下
1 | final long sumCount() { |
另外一个有类似功能的类,专门设计给高并发计数的场景:LongAdder类(java.util.concurrent.atomic.LongAdder),它比AtomicLong原子计数器性能更强,本博客也给出相关性能测试。
addCount骨架代码:
1 | private final void addCount(long x, int check) { |
完整源码分析:
1 | // 调用addCount(1L, binCount),因此以下的入参x是1,check是binCount, |
fullAddCount方法
在源码中,第2500行,有一片代码段称为“Counter support”,作者指出它是用于分布式计数,fullAddCount方法改编自LongAdder and Striped64
1 | /* ---------------- Counter support -------------- */ |
fullAddCount方法的设计和实现是复杂且有精妙的,主要分为三个逻辑:
1、如果CounterCell数组不为空且数组里面已经有Cell对象,说明CounterCell数组已经被其他线程完成了创建,那么当前线程自然无需再创建它,而是尝试在当前下线程对应的空桶位放入Cell(1),相当于对value加1操作(如果桶位已有Cell对象,就使用cas对其加1计数)
2、在条件1不满足情况下,此时CounterCell数组为空表示还未被创建,那么当前线程把cellsBusy状态改为1(相当于加锁),并把CounterCell数组创建好,默认长度2,创建好后顺便在对应的桶位放入Cell(1)
3、桶位Cell加1操作失败、又没抢到CounterCell数组的创建权,总不能白跑一趟,因此到了这一步当前线程顺便再尝试对baseCount加1,若cas成功就可以直接break。
以上三个分支逻辑对应以下骨架代码:主分支1、主分支2、主分支3,其中主分支1的逻辑设计是最复杂的,它包含6个次分支:1.1到1.6。
这里一定要有一个基本常识:首先,线程的每次循环,只能执行3个主分支中的其中1个。另外一个基本常识:如果线程进入到主分支1,那么在1.1到1.6总共6个次分支中,线程也只能进入其中一个分支
1 | for(;;) |
讲解完整源码之前,先了解cellsBusy“锁”的设计理论,cellsBusy本身只是一个volatile变量,而cellsBusy+CAS就可以用无锁方式实现“加锁功能”,线程就是用这种“轻锁机制”去完成CounterCell数组创建、将Cell对象放入桶位、CounterCell数组扩容,用法如下:
1 | // ① 尝试“加锁”:若为true就相当于加锁成功,但该锁机制很轻量! |
完整源码解析,以下for(;;)循环内部逻辑按前面提到的三个主分支进行分段解析,这是因为太多if和else if条件,需要分段解析才比较清晰其内部设计逻辑
fullAddCount主分支1
线程从addCount首次进入到fullAddCount时,假设先进入到分支1
1 | // fullAddCount(x=1, uncontended=false) |
次分支1.2的设计目的:
1 | // 1.2 // fullAddCount(long x=1, boolean wasUncontended=false) |
当前线程第1次遇到CounterCell数组不为空的情况下,且线程定位到的桶位不是空,并不急着安排线程对桶位上Cell对象进行cas加1计数。由于addCount方法调用fullAddCount入参wasUncontended时被设为false,因此线程会进入分支1.2,此时wasUncontended设为true表示当前线程暂时还没有遇到竞争,更新hash值(h = ThreadLocalRandom.advanceProbe(h)),再直接回到for进行第2次遍历重试。
这里为何设计2次遍历? 因为CounterCell首次被创建时容量为2,也即有
rs[0],rs[1]两个空桶位,假设线程第1次定位到rs[0]不为空(此时不能认为存在线程竞争导致的,只是rs[0]里面已经有Cell对象,这也是wasUncontende设为true的原因)接下来当然是再换线程的hash看看能不能定位到rs[1]桶位,如果恰好定位到rsp[1]是空桶位,那么线程就可以放入Cell对象。如果2次重试线程定位到的桶位都不为空,线程第3次遍历重试就会进入下文的次分支1.3(当然换完hash值也有可能又定位到rs[0]桶位)
次分支1.3的设计目的:
如果第2次遍历时,线程所定位的桶位又不为空,由于wasUncontended是true,因此会跳过次分支1.2,尝试去对桶位上Cell对象直接cas加1操作,如果加1成功,线程就可以退出for循环了,如果失败就来到次分支1.4
1 | // 1.3 |
次分支1.5以及1.6的设计目的:
不妨先考察次分支1.4两个条件都不成立时的执行流:
这时线程就会跳过分支1.4去执行次分支1.5(因为collide默认为false,此时线程会进入分支1.5),将collide设为true,更新hash值,再直接回到for进行第3次遍历:
**实际含义为:我(当前线程)第1次循环定位桶位不为空,第2次循环定位桶位也不为空,且对桶位上Cell对象cas加1失败,说明出现了明显线程竞争,那么第3次循环重试我就选择去扩容CounterCell数组** 此时线程进行第3次循环时,因为collide已经在上一轮设为true,所以线程在第3次重试时会跳过次分支1.5,来到次分支1.6代码区,此时线程会将CounterCell数组做2倍扩容,然后将collide设为false,表示:既然都扩容了,说明有新空桶位可供操作,线程间的冲突得以解决,当前线程只需直接continue回到for重试,也即源码注释提到的: Retry with expanded table1 | // 1.4 |
次分支1.4的设计目的(最难理解的次分支)
该分支必须结合分支1.5和分支1.6的设计意义来理解:
分支1.6说明:线程一旦遇到明显的冲突,也即多次for循环定位到桶位不为空且对非空桶位的Cell对象cas加1失败(collide=true),那它会执行分支1.6逻辑:对CounterCell数组进行2倍扩容。那么会不会出现这样的情况:如果不断有后续更多线程也遭遇“冲突”,那么就有线程会无休止对CounterCell数组进行2倍扩容,有无停止扩容的条件?
当然是有的,这就是次分支1.4的设计目的:防止CounterCell数组无限被扩容,如何实现?
次分支1.4有2个判断条件:
先看条件2:n >= NCPU,也即CounterCell数组长度达到cpu个数时,就将collide 改为false,更新hash值,再直接回到for重试
而分支1.5、1.6逻辑都被会跳过不执行,下一次循环如果又来到分支1.4,因为n >= NCPU成立,所以分支1.5、1.6逻辑再次被跳过不执行,之后的循环也类似处理。
所以:CounterCell数组停止的条件是,只要它的长度达到cpu个数,当前线程就不会再执行次分支1.6扩容的代码,而是从分支1.4将collide改为false,然后直接回到for循环、
当CounterCell数组不再扩容时,这些线程该如何执行多个分支代码呢
显然,当CounterCell数组不再扩容时,那么空桶位很快会被线程们放满Cell对象,也即CounterCell数组数组没有空桶位,之后线程是这么执行的:
次分支1.1 if ((a = as[(n - 1) & h]) == null)不再成立,所以会跳到次分支1.2,由于wasUncontended早已被设为true(请回去看次分支1.2的设计目的),次分支1.2也会被跳过,线程继续来到次分支1.3,此时线程会使用cas对Cell对象加1操作,若加成功就可以break,否则就来到次分支1.4,因为n=>NCPU一直为true,将collide改为false,更新hash值,再直接回到for重试。
简单总结:当CounterCell数组不再扩容时,且没有空桶位时,这些更新线程其实就会简化成以下的执行逻辑:
1 | for(;;) |
从以上简化代码可以看出,线程一定能在某个时刻在对应桶位的Cell对象上加1成功,然后退出循环,这也是fullAddCOunt设计真实目的:保证每个线程进入到fullAddCount到离开fullAddCount之前一定能够cas加1成功
此时,我们再来考察次分支1.4的条件1:
有了条件2的铺垫,其他条件1很好理解:counterCells != as,表明恰好有其他线程正在扩容CounterCell数组(导致as指向新的CounterCells数组对象),接下来可能在扩容后的CounterCell数组有更多的空桶位,那么当前线程就没必要去竞争扩容了,只需将collide 改为false,更新自己hash值,然后直接回到for循环重试看看能否运气好拿到新的空桶位。
fullAddCount主分支2:
若CounterCell数组为空时(还未被创建),也即fullAddCount的主分支1会被跳过,当前线程会进入主分支2代码区,那么当前线程把cellsBusy状态改为1(相当于加锁),创建好一个默认长度为2的CounterCell数组,并顺便在对应的桶位放入Cell(1)完成加1计数
1 |
|
fullAddCount主分支3:
主分支3:线程执行fullAddCount的主分支1桶位Cell加1操作失败,接着执行fullAddCount主分支2时又没抢到CounterCell数组的创建权,
那么当前线程总不能白跑一趟,因此到了这一步当前线程顺便尝试对baseCount做加加1计数(或者加x计数,x代表正负数都可以),若成功就退出,失败就回到for循环重试
1 |
|
小结:从三个主分支的设计来看,主分支1无疑是最复杂的,因为判断多,条件多,理解起来象比较绕,需要用全局、逆向思维去分析,最好是先找到一个容易理解的分支,然后根据这个分支的实际含义来顺藤摸瓜再找到其他分支的实际含义
从for循环退出的条件也可理解fullAddCount的内在设计逻辑
有以上详细的源码解释后,考察线程for自旋退出的条件(成功计数加1的条件),其实就是对应前面提到的3个主分支。
1、第2552行,主分支1-次分支1.1,当前线程对应的桶位为null然后成功放入Cell对象时可退出for自旋
1 | if (created) |
2、第2561行,主分支1-次分支1.3,进入CounterCell数组的操作逻辑,当前线程对非空桶位的Cell对象,使用CAS加1成功时可退出for自旋
1 | else if (U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x)) |
3、第2597行,主分支2:当前线程创建默认长度2的CounterCell数组并选其中一个桶位放入Cell对象后可退出for自旋
1 | if (init) |
4、第2600行,主分支3:当前线程以上尝试三种逻辑都失败时,总不能白跑一趟,再尝试去CAS对baseCount加1,成功时可退出for循环
1 | else if (U.compareAndSwapLong(this, BASECOUNT, v = baseCount, v + x)) |
关于addcount完成计数加1后的CHM扩容逻辑分析,则单独在另外一篇博客给出,因为它的设计相对复杂,需要分析的内容较多。