在前面文章中,addCount方法分为两部分:
第一部分是put一个节点后,需要对size加1计数,这部分交由fullAddCount完成,它的设计和逻辑可谓精妙,非常值得在实际项目参考其代码实现。
第二部分是加1计数后,需要判断是否需要对table进行扩容,扩容思想设计及其源代码实现同样非常精妙,值得多次阅读和学以致用!
本文将重点深入分析CHM核心扩容逻辑:transfer、helpTransfer、以及resizeStamp。
《gitee 博客文章封面》
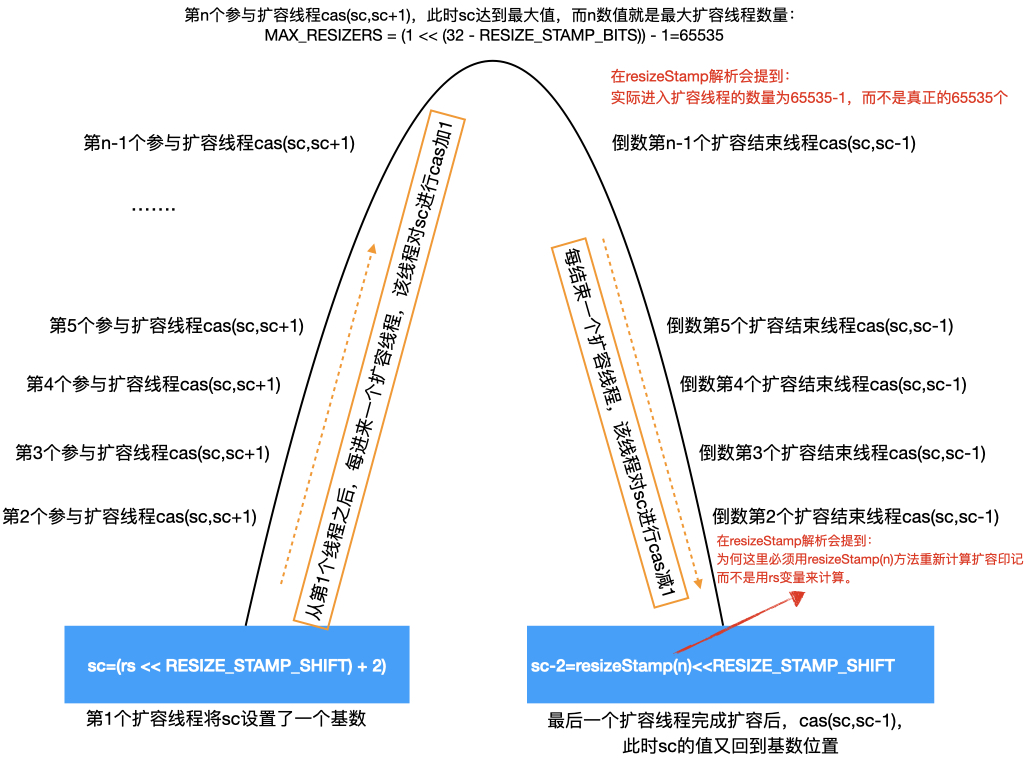
1、addCount的扩容判断设计 第1个执行扩容线程 本章节最精彩的地方:分析Doug Lea 如何安排“每个加入扩容任务线程对sc进行cas加1计数”、“每个结束自己扩容任务线程对sc进行减1”、以及“最后一个结束扩容线程要干些什么收尾工作”。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 private final void addCount (long x, int check) CounterCell[] as; long b, s; if (check >= 0 ) { Node<K,V>[] tab, nt; int n, sc; while (s >= (long )(sc = sizeCtl) && (tab = table) != null && (n = tab.length) < MAXIMUM_CAPACITY) { int rs = resizeStamp(n); if (sc < 0 ) { if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 || sc == rs + MAX_RESIZERS || (nt = nextTable) == null || transferIndex <= 0 ) break ; if (U.compareAndSwapInt(this , SIZECTL, sc, sc + 1 )) transfer(tab, nt); } else if (U.compareAndSwapInt(this , SIZECTL, sc, (rs << RESIZE_STAMP_SHIFT) + 2 )) transfer(tab, null ); s = sumCount(); } } }
对于分支2.1:因为表示有其他线程在扩容,说明是并发状态,这部分逻辑先放着,我们先考察分支2.2的逻辑。
分支2.2: 对于ConcurrentHashMap 第1个进入扩容的线程会执行此逻辑,会将sc(sizeCtl)设为一个基础负数:(rs << RESIZE_STAMP_SHIFT) + 2
“第1个执行扩容线程”:当ConcurrentHashMap首次扩容时,负责首次扩容任务的线程就是“第1个执行扩容线程”,这个概念很重要!
1 2 3 4 5 6 else if (U.compareAndSwapInt(this , SIZECTL, sc, (rs << RESIZE_STAMP_SHIFT) + 2 )) {transfer(tab, null );}
正是因为有了“第1个执行扩容线程”将sc(sizeCtl)设为一个基础负数,此时回看分支2.1即可明白其含义:
此时sc是个基础负数,因此sc<0必然成立,换句话说:只要有第2个以及后续更多的线程进入whlie,sc<0成立,表明当前CHM正在扩容状态(或者有线程正在对CHM进行扩容处理)
有了以上解析的铺垫,现在我们重新理顺以下执行流程:假设当前CHM已经达到扩容阈值时,“第1个执行扩容线程”以及“第2个以及以后更多线程加入到扩容”在进入addCount后的执行流,从序号①开始,按升序推进,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 private final void addCount (long x, int check) CounterCell[] as; long b, s; s = sumCount(); if (check >= 0 ) { Node<K,V>[] tab, nt; int n, sc; while (s >= (long )(sc = sizeCtl) && (tab = table) != null && (n = tab.length) < MAXIMUM_CAPACITY) { int rs = resizeStamp(n); if (sc < 0 ) { if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 || sc == rs + MAX_RESIZERS || (nt = nextTable) == null || transferIndex <= 0 ) break ; if (U.compareAndSwapInt(this , SIZECTL, sc, sc + 1 )) transfer(tab, nt); } else if (U.compareAndSwapInt(this , SIZECTL, sc, (rs << RESIZE_STAMP_SHIFT) + 2 )) transfer(tab, null ); s = sumCount(); } } }
sc设置为一个基础负数的实际意义 sizeCtl在CHM扩容期间的用处大有来头:如下图所示
此图可以清晰解释Doug Lea设计sc=(rs << RESIZE_STAMP_SHIFT) + 2)的意图:
第1个线程将sc设置基数值后,以后每进来一个扩容线程,该线程对sc进行cas加1(结合上图),代码实现是在上面的addCount的分支2.1.2
1 2 3 4 if (U.compareAndSwapInt(this , SIZECTL, sc, sc + 1 )) transfer(tab, nt); }
对sc加1有什么用?其实到这里应该可以理解了:Doug Lea用这种方式记录当前参与扩容线程的数量, 为何要记录参与扩容线程的数量?
两个目的,而且都是非常“聪明”的目的!
因为一个JVM进程开启太过多的线程数量(例如10万个线程)参与到扩容,意味着当前OS大量线程在运行,高并发下的线程上下文切换、大量线程栈占用空间,一定程度上导致CHM性能不增加反降低,甚至影响到“系统层面的稳定性”,至于为何设计最大扩容线程数量为65535(对应二进制1111 1111 1111 1111),需从文章后面的resizeStemp解析中找到答案。
题外话:65535是不是很熟悉?windows 最大可开启的tcp端口号数量?想想为何是这个数2^16-1?或者思考:一个Java进程到底能创建多少线程,注意到最大线程理论值=进程的用户地址空间除以线程栈的大小,用户地址空间和线程栈又取决于操作系统、内存、jvm参数等,具体可参考这篇文章JVM源码分析之一个Java进程究竟能创建多少线程
JVM:Xmx,Xss,MaxPermSize,MaxDirectMemorySize,ReservedCodeCacheSize等
Kernel:max_user_processes,max_map_count,max_threads,pid_max等
如果参与扩容的线程数量达到了最大值,后面再来第65536、65537、65538个等更多线程,这些线程不会参与到扩容逻辑代码,控制实现在addCount的分支2.1.1的条件:如果sc == rs + MAX_RESIZERS,也即当前参与到扩容队伍的总线程数量达到设定的最大值,再进来的线程不再安排扩容,这些线程会直接break返回。
1 2 3 4 5 6 7 8 9 10 11 if (check >= 0 ) { Node<K,V>[] tab, nt; int n, sc; while (s >= (long )(sc = sizeCtl) && (tab = table) != null && (n = tab.length) < MAXIMUM_CAPACITY) { int rs = resizeStamp(n); if (sc < 0 ) { if ((条件1 || 条件2 ||sc == rs + MAX_RESIZERS || 条件4 || 条件5 ) break ;
第二个目的:为了确定到底哪个线程是“最后一个完成扩容的线程”?
为了确定到底哪个线程是“最后一个完成扩容的线程”,并让它来告知外界整个CHM已经完成了扩容,具体如何实现?
Doug Lea这么设计:每结束一个扩容线程,那个线程就对sc进行cas减1(结合上图理解),直到有一个线程对sc进行cas减1时恰好使得sc就是一开始设置的基础值,那么这个线程就是要找的“最后一个完成扩容的线程”,于是可以将finishing置为true,表示整个CHM的扩容已经完成,对应的源码如下,在transfer方法里面 :
1 2 3 4 5 6 7 8 9 10 11 12 for (int i = 0 , bound = 0 ;;) { Node<K,V> f; int fh; while (advance) { if (U.compareAndSwapInt(this , SIZECTL, sc = sizeCtl, sc - 1 )) { if ((sc - 2 ) != resizeStamp(n) << RESIZE_STAMP_SHIFT) return ; finishing = advance = true ; i = n; }
可把`(sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT` 改写为`sc = (resizeStamp(n) << RESIZE_STAMP_SHIFT) +2`,所以以上①逻辑可以改写下面的②和③写法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 for (int i = 0 , bound = 0 ;;) { Node<K,V> f; int fh; while (advance) { if (U.compareAndSwapInt(this , SIZECTL, sc = sizeCtl, sc - 1 )) { if (sc==(resizeStamp(n) << RESIZE_STAMP_SHIFT) +2 ){ finishing = advance = true ; i = n; }else { return ; } }
这下逻辑清晰了:
执行`finishing = advance = true;i = n `后,“最后一个完成扩容的线程”在transfer内部就会按以下执行流程走(按序号升序来看执行流,从底下的①开始)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 for (int i = 0 , bound = 0 ;;) { Node<K,V> f; int fh; while (advance) { int nextIndex, nextBound; if (--i >= bound || finishing) advance = false ; else if ((nextIndex = transferIndex) <= 0 ) { i = -1 ; advance = false ; } else if (U.compareAndSwapInt (this , TRANSFERINDEX, nextIndex, nextBound = (nextIndex > stride ? nextIndex - stride : 0 ))) { bound = nextBound; i = nextIndex - 1 ; advance = false ; } } if (i < 0 || i >= n || i + n >= nextn) { int sc; if (finishing) { nextTable = null ; table = nextTab; sizeCtl = (n << 1 ) - (n >>> 1 ); return ; } if (U.compareAndSwapInt(this , SIZECTL, sc = sizeCtl, sc - 1 )) { if ((sc - 2 ) != resizeStamp(n) << RESIZE_STAMP_SHIFT) return ; finishing = advance = true ; i = n; } }
当线程进入了transfer方法后,这些线程们是怎么知道自己负责第几号到第几号的桶位迁移呢、以及如何将自己管辖的桶位节点转移到新表中呢?这就是tranfer方法里面第二层要深入解析的内容。
#### 2、transfer内部精密的并发设计
##### 2.1 为每个扩容线程分配“桶位区间”
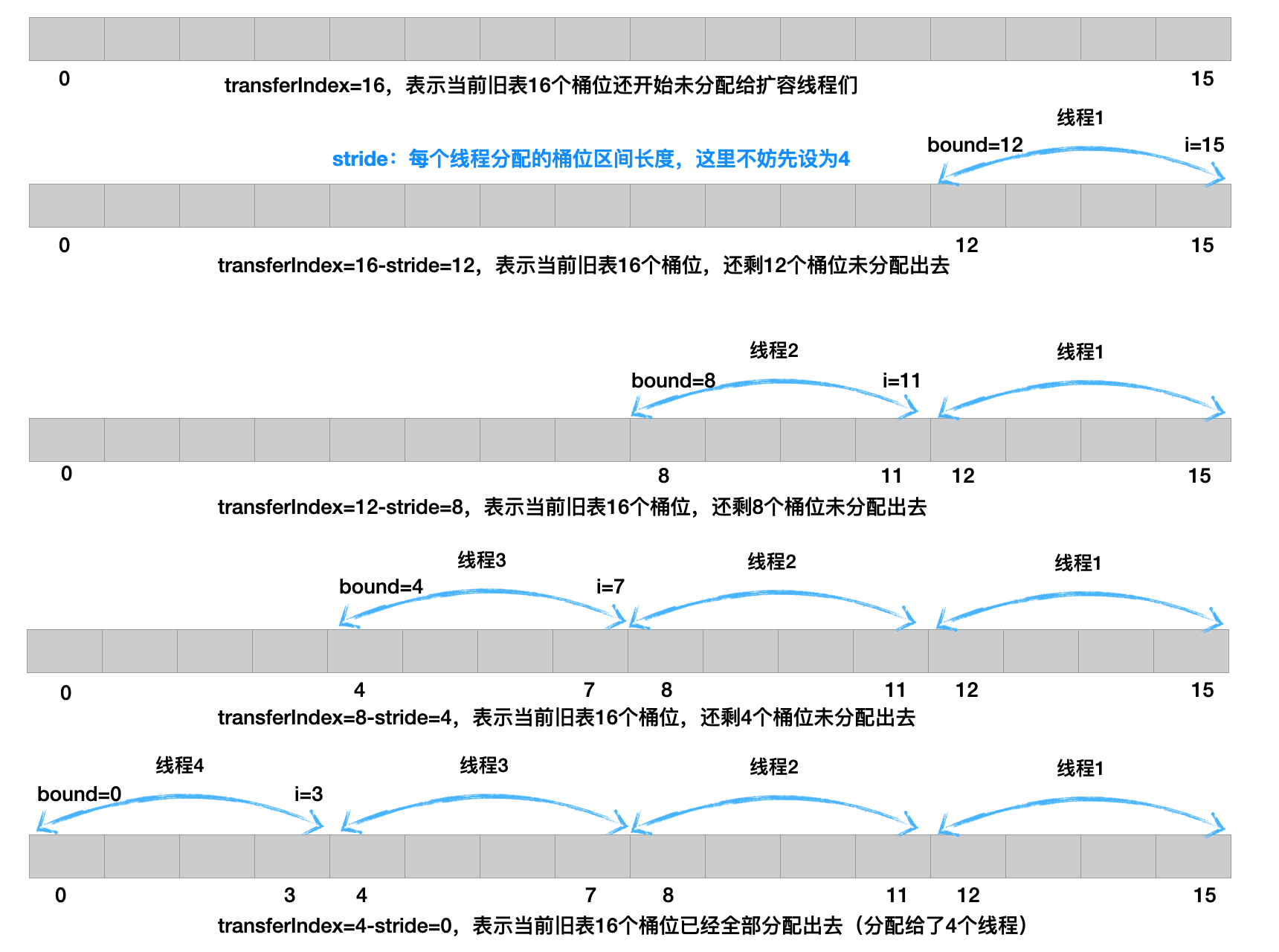
假设现有4个线程并发同一时刻进入transfer逻辑,那么每个线程如何协同转移节点呢?
首先:为每个线程准确划分线程自己要管辖的“桶位区间”,既然要确定桶位区间`[left,right]`,就必然要在并发环境下计算每个线程自己区间的左边界下标和右边界下标,而右区间边界-左区间边界就是步长:stride,也即线程要完成转移的桶位个数(或者领取任务的个数/步长),如下:
1 2 3 4 5 private final void transfer (Node<K,V>[] tab, Node<K,V>[] nextTab) int n = tab.length, stride; if ((stride = (NCPU > 1 ) ? (n >>> 3 ) / NCPU : n) < MIN_TRANSFER_STRIDE) stride = MIN_TRANSFER_STRIDE;
以下以4个线程为例,table长度16,为了方便作图,本文的stride长度设为4,那么四个线程各自分配到桶位范围如下图所以

划分好每个线程自己的桶位区间有什么用?当然是各司其职,将自己管辖区间内的桶位节点迁移到新table上。
那么每个线程分配的桶位区间是如何以并发方式(无锁方式)计算出?
考察现在有线程1,2,3,4共4个线程同一时刻执行到`for (int i = 0, bound = 0;;) ` ,基于当前table=16和本文stride长度设为4。不妨假设线程1先执行,而且线程1是作为“第1个扩容线程”进入到transfer方法里面:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 if ((stride = (NCPU > 1 ) ? (n >>> 3 ) / NCPU : n) < MIN_TRANSFER_STRIDE) stride = MIN_TRANSFER_STRIDE; if (nextTab == null ) { try { @SuppressWarnings("unchecked") Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1 ]; nextTab = nt; } catch (Throwable ex) { sizeCtl = Integer.MAX_VALUE; return ; } nextTable = nextTab; transferIndex = n; }
线程1上面流程走完后有:`transferIndex=n=16,stride=4`
线程1:从for循环开始,因为i = 0,bound = 0,因此分支1条件不成立,因为nextIndex = transferIndex=16,显然分支2的条件也不成立,那么只能执行分支3,假设4个线程此时都来到分支3,不妨假设此时线程1抢到CAS,那么对于线程1就会进入分支3逻辑,其他3个线程继续`while`自旋再回到分支3的CAS。线程1执行流程如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 boolean advance = true ; boolean finishing = false ; for (int i = 0 , bound = 0 ;;) { while (advance) { int nextIndex, nextBound; if (--i >= bound || finishing) advance = false ; else if ((nextIndex = transferIndex) <= 0 ) { i = -1 ; advance = false ; } else if (U.compareAndSwapInt(this , TRANSFERINDEX, nextIndex, nextBound = (nextIndex > stride ? nextIndex - stride : 0 ))) { bound = nextBound; i = nextIndex - 1 ; advance = false ; }
线程2:线程1完成cas逻辑后退出while,其他3个线程还得继续竞争分支3的cas,不妨假设线程2成功操作cas(线程3、线程4只能继续循环cas),那么线程2会执行以下逻辑:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 for (int i = 0 , bound = 0 ;;) { while (advance) { int nextIndex, nextBound; if (--i >= bound || finishing) advance = false ; else if ((nextIndex = transferIndex) <= 0 ) { i = -1 ; advance = false ; } else if (U.compareAndSwapInt (this , TRANSFERINDEX, nextIndex, nextBound = (nextIndex > stride ? nextIndex - stride : 0 ))) { bound = nextBound; i = nextIndex - 1 ; advance = false ; }
线程3:线程2完成cas逻辑后退出while,其他2个线程还是同时竞争分支3的cas,不妨假设线程3成功操作cas(此时线程4只能继续循环cas),那么线程3会执行以下逻辑:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 for (int i = 0 , bound = 0 ;;) { while (advance) { int nextIndex, nextBound; if (--i >= bound || finishing) advance = false ; else if ((nextIndex = transferIndex) <= 0 ) { i = -1 ; advance = false ; } else if (U.compareAndSwapInt (this , TRANSFERINDEX, nextIndex, nextBound = (nextIndex > stride ? nextIndex - stride : 0 ))) { bound = nextBound; i = nextIndex - 1 ; advance = false ; }
线程4:线程3完成cas逻辑后退出while,目前只有线程4操作分支3的cas,肯定能进入cas,那么线程4会执行以下逻辑:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 for (int i = 0 , bound = 0 ;;) { while (advance) { int nextIndex, nextBound; if (--i >= bound || finishing) advance = false ; else if ((nextIndex = transferIndex) <= 0 ) { i = -1 ; advance = false ; } else if (U.compareAndSwapInt (this , TRANSFERINDEX, nextIndex, nextBound = (nextIndex > stride ? nextIndex - stride : 0 ))) { bound = nextBound; i = nextIndex - 1 ; advance = false ; }
经过以上四轮while推演,可以发现四个线程并发同一时刻进入`for (int i = 0, bound = 0;;) `并来到`whlie(advance)` 的实际目的:就是为扩容线程们分配好各自要迁移的桶位区间,分配方式是从table尾部往头部方向的倒序分配,正如上面计算的线程1=>15到12,线程2=>11到8,线程3=>7到4,线程4=>3到0,而且巧妙的是:每个线程分配的桶位区间都不会重叠,原因在于:分支3需要线程自己抢到cas权才能对transferIndex扣减步长值
在4个线程分配好桶位区间的情况下,此时若存在第5个线程、第6个线程…..它们能分配到桶位区间吗?答案是不能,可以分开两种线程时刻讨论:
不妨假设第5个线程、第6个线程…都是和线程1、线程2、线程3、线程4一起进入到for (int i = 0, bound = 0;;)并来到whlie(advance),由于前面4个线程分配好了桶位区间(但这个4个线程正准备扩容),此时考察第5个线程,不妨假设从while的①步骤开始
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 for (int i = 0 , bound = 0 ;;) { boolean advance = true ; boolean finishing = false ; while (advance) { int nextIndex, nextBound; if (--i >= bound || finishing) advance = false ; else if ((nextIndex = transferIndex) <= 0 ) { i = -1 ; advance = false ; } else if (U.compareAndSwapInt (this , TRANSFERINDEX, nextIndex, nextBound = (nextIndex > stride ? nextIndex - stride : 0 ))) { bound = nextBound; i = nextIndex - 1 ; advance = false ; } if (i < 0 || i >= n || i + n >= nextn) { int sc; if (finishing) { nextTable = null ; table = nextTab; sizeCtl = (n << 1 ) - (n >>> 1 ); return ; } if (U.compareAndSwapInt(this , SIZECTL, sc = sizeCtl, sc - 1 )) { if ((sc - 2 ) != resizeStamp(n) << RESIZE_STAMP_SHIFT) return ; finishing = advance = true ; i = n; } }
由上面的①到⑨执行流,可以看出,由于transferIndex已经被线程4设置为0后(表示16个桶位都分配给前面4个线程),第5个线程就会进入③代码片区,最终从⑨结束并返回到外部addCount方法,可以清楚看到线程5在整个过程即没有“分配到桶位区间”也没有参与“桶位节点迁移工作”就直接返回了,继续看线程5返回点,从⑪开始:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 private final void addCount (long x, int check) CounterCell[] as; long b, s; if (check >= 0 ) { Node<K,V>[] tab, nt; int n, sc; while (s >= (long )(sc = sizeCtl) && (tab = table) != null && (n = tab.length) < MAXIMUM_CAPACITY) { int rs = resizeStamp(n); if (sc < 0 ) { if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 || sc == rs + MAX_RESIZERS || (nt = nextTable) == null || transferIndex <= 0 ) break ; if (U.compareAndSwapInt(this , SIZECTL, sc, sc + 1 )) transfer(tab, nt); } else if (U.compareAndSwapInt(this , SIZECTL, sc, (rs << RESIZE_STAMP_SHIFT) + 2 )) transfer(tab, null ); s = sumCount(); } } }
在这里⑭步骤可以知道,线程5就退出了。
由此,我们终于搞清楚这样的扩容安排:对于旧表16开始扩容时,已经有4个线程分配好各自待迁移桶位区间后,如果此时后续再来第5个线程、第6个线程等更多线程进入到扩容逻辑transfer方法,这些后来者线程(或者在分配桶位区间竞争失败的线程)最终即没有“分配到桶位区间”也没有参与“桶位节点迁移工作”,直接结束addCount方法调用。
假设线程1、线程2、线程3、线程4已经分配好了桶位区间,并假设此时第5个线程、第6个线程等其他线程开始进入AddCount方法内部的while位置:此时考察第5个线程,由于transferIndex已经等于0可知,其实此时线程5(线程6等)就会回到上面第一种情况分析的⑭步骤:1 2 3 4 5 6 7 if (sc < 0 ) { if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 || sc == rs + MAX_RESIZERS || (nt = nextTable) == null || transferIndex <= 0 ) break ;
关于以上四个线程并发分配桶位区间的计算过程,总结如下图
2.2 桶位区间迁移节点的设计 前面给4个线程分配好各自的桶位区间后,接下来四个线程要完成自己管辖的桶位区间节点迁移任务。
不妨以线程1作为考察:线程1管辖的桶位区间是[12,15],从第i=15号桶位开始进行节点迁移,直到4个桶位节点都迁移完毕的图示流程:
图中的fwd节点:线程每完成一个节点迁移,就在旧表桶位放置一个fwd节点
以下的桶位区间节点迁移过程是基于i=15桶位开始:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab); boolean advance = true ; boolean finishing = false ; for (int i = 0 , bound = 0 ;;) { Node<K,V> f; int fh; while (advance) { int nextIndex, nextBound; if (--i >= bound || finishing) advance = false ; else if ((nextIndex = transferIndex) <= 0 ) { i = -1 ; advance = false ; } else if (U.compareAndSwapInt (this , TRANSFERINDEX, nextIndex, nextBound = (nextIndex > stride ? nextIndex - stride : 0 ))) { bound = nextBound; i = nextIndex - 1 ; advance = false ; } } if (i < 0 || i >= n || i + n >= nextn) { int sc; if (finishing) { nextTable = null ; table = nextTab; sizeCtl = (n << 1 ) - (n >>> 1 ); return ; } if (U.compareAndSwapInt(this , SIZECTL, sc = sizeCtl, sc - 1 )) { if ((sc - 2 ) != resizeStamp(n) << RESIZE_STAMP_SHIFT) return ; finishing = advance = true ; i = n; } } else if ((f = tabAt(tab, i)) == null ) advance = casTabAt(tab, i, null , fwd); else if ((fh = f.hash) == MOVED) advance = true ; else { synchronized (f) setTabAt(nextTab, i, ln); setTabAt(nextTab, i + n, hn); setTabAt(tab, i, fwd); advance = true ; }
有了以上扩容线程1对i=15桶节点迁移流程的说明后,那么接下里继续讨论线程1如何知道已经完成[bound=12,i=15]桶位区间所有节点迁移且退出for循环的流程。
不妨考察线程1当前迁移的桶位是第i=13桶号,之后的执行流程按以下序列号进行,从底部的①开始按升序知道第⑰步的return,以下逻辑一定耐心看完,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 private final void transfer (Node<K,V>[] tab, Node<K,V>[] nextTab) for (int i = 0 , bound = 0 ;;) { Node<K,V> f; int fh; while (advance) { int nextIndex, nextBound; if (--i >= bound || finishing) advance = false ; else if ((nextIndex = transferIndex) <= 0 ) { i = -1 ; advance = false ; } else if (U.compareAndSwapInt (this , TRANSFERINDEX, nextIndex, nextBound = (nextIndex > stride ? nextIndex - stride : 0 ))) { bound = nextBound; i = nextIndex - 1 ; advance = false ; } } if (i < 0 || i >= n || i + n >= nextn) { int sc; if (finishing) { nextTable = null ; table = nextTab; sizeCtl = (n << 1 ) - (n >>> 1 ); return ; } if (U.compareAndSwapInt(this , SIZECTL, sc = sizeCtl, sc - 1 )) { if ((sc - 2 ) != resizeStamp(n) << RESIZE_STAMP_SHIFT) return ; finishing = advance = true ; i = n; } } else if ((f = tabAt(tab, i)) == null ) advance = casTabAt(tab, i, null , fwd); else if ((fh = f.hash) == MOVED) advance = true ; else { synchronized (f) { if (tabAt(tab, i) == f) { setTabAt(nextTab, i, ln); setTabAt(nextTab, i + n, hn); setTabAt(tab, i, fwd); advance = true ; } else if (f instanceof TreeBin) { setTabAt(nextTab, i, ln); setTabAt(nextTab, i + n, hn); setTabAt(tab, i, fwd); advance = true ; } } } } } }
现在考察线程1执行完⑰的return后,它会在回到⑲while处,然后流程如下:最后发现线程1完成自己桶位区间节点迁移后,会在以下的㉑步骤退出while循环结束addCount方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 private final void addCount (long x, int check) if (check >= 0 ) { Node<K,V>[] tab, nt; int n, sc; while (s >= (long )(sc = sizeCtl) && (tab = table) != null && (n = tab.length) < MAXIMUM_CAPACITY) { int rs = resizeStamp(n); if (sc < 0 ) { if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 || sc == rs + MAX_RESIZERS || (nt = nextTable) == null || transferIndex <= 0 ) break ; if (U.compareAndSwapInt(this , SIZECTL, sc, sc + 1 )) transfer(tab, nt); } else if (U.compareAndSwapInt(this , SIZECTL, sc, (rs << RESIZE_STAMP_SHIFT) + 2 )) transfer(tab, null ); s = sumCount(); } } }
2.3 桶位节点转移到新表 2.1关注的是线程自己如何一个桶位一个桶位迁移的控制逻辑,那么接下来就要解释扩容线程如何将旧表桶位节点转移到新表中的过程,其实只要掌握jdk1.8的HashMap双向链表到树和jdk1.7的ConcurrentHashMap链表转移设计思想,以下逻辑则很好理解:
针对两种数据节点类型对应两种迁移设计:
1、synchronized锁住当前桶位头节点f,保证当前线程独占操作。换句话说:只能有1个线程负责迁移当前桶位节点到新数组,请别误解为:jdk1.8多线程并发协同扩容是指多个线程一起在同一个桶位上“并发协同”迁移桶位节点。
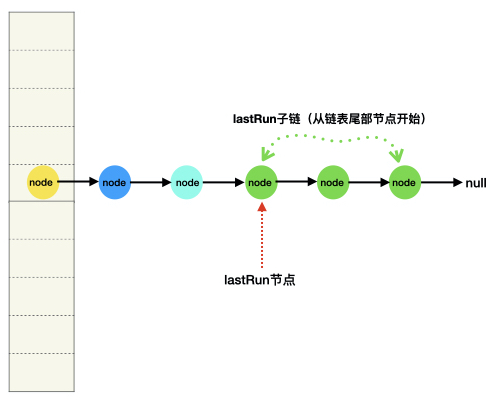
2、如果桶位头节点是一条链表,先找出lastRun节点为首的子链,然后根据高位节点(p.hash & n 不等于0)和低位节点特征(p.hash & n等于0)分别构建一条低位节点链ln和一条高位节点链hn
(如果你已经掌握jdk1.7CHM的Segment数组扩容算法,你会发现jdk1.8的处理方式比1.7更优,因为jdk1.8引入了低位节点链和高位节点链作为迁移前的中间容器,而这里的低位链和高位链的设计需要你掌握jdk1.8HashMap的数组扩容算法)
3、链表除去lastRun子链,还剩下位于lsatRun节点前面的节点,将这些节点使用头插法插入到ln或者hn中
4、此时冲突链被完整的拆开成低位链和高位链,接下来就好办了:使用cas方式,低位链放在新表的第i位置,高位链放在新表的第i+n位置
5、第4点迁移完后,线程在当前桶位放置一个fwd,表示当前桶位已迁移完。
6、线程将advance设为true,回到while继续处理“桶位区间”的下一个待迁移桶位
1 2 3 4 while (advance) { int nextIndex, nextBound; if (--i >= bound || finishing) advance = false ;
这里再次提醒:“桶位区间”的迁移顺序是倒序的,例如当前线程负责的桶位区间为[12,15],当第15号桶位迁移完后,—i继续处理下一个第14号桶位节点,以此类推,直到—i等于11越过左边界12,说明此时桶位区间包含的4个桶位节点全部被当前线程迁移到新表里面。
lastRun子链是什么?
就是从链表的尾部节点开始,找到具有相同的(e.hash & n)值的连续最大子链,图示如下:
其中e.hash & n的计算公式可找出低位节点和高位节点。
因为TreeBin持有红黑树的root节点,关于红黑树扩容的分析在在jdk1.8的HashMap文章有详细的过程,CHM也类似逻辑,这里不再累赘。
以上两种迁移思路就是下面transfer方面里面:synchronized (f)代码片段要实现的逻辑
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 private final void transfer (Node<K,V>[] tab, Node<K,V>[] nextTab) else if ((f = tabAt(tab, i)) == null ) advance = casTabAt(tab, i, null , fwd); else if ((fh = f.hash) == MOVED) advance = true ; else { synchronized (f) { if (tabAt(tab, i) == f) { Node<K,V> ln, hn; if (fh >= 0 ) { int runBit = fh & n; Node<K,V> lastRun = f; for (Node<K,V> p = f.next; p != null ; p = p.next) { int b = p.hash & n; if (b != runBit) { runBit = b; lastRun = p; } } if (runBit == 0 ) { ln = lastRun; hn = null ; } else { hn = lastRun; ln = null ; } for (Node<K,V> p = f; p != lastRun; p = p.next) { int ph = p.hash; K pk = p.key; V pv = p.val; if ((ph & n) == 0 ) ln = new Node<K,V>(ph, pk, pv, ln); else hn = new Node<K,V>(ph, pk, pv, hn); } setTabAt(nextTab, i, ln); setTabAt(nextTab, i + n, hn); setTabAt(tab, i, fwd); advance = true ; } else if (f instanceof TreeBin) { TreeBin<K,V> t = (TreeBin<K,V>)f; TreeNode<K,V> lo = null , loTail = null ; TreeNode<K,V> hi = null , hiTail = null ; int lc = 0 , hc = 0 ; for (Node<K,V> e = t.first; e != null ; e = e.next) { int h = e.hash; TreeNode<K,V> p = new TreeNode<K,V> (h, e.key, e.val, null , null ); if ((h & n) == 0 ) { if ((p.prev = loTail) == null ) lo = p; else loTail.next = p; loTail = p; ++lc; } else { if ((p.prev = hiTail) == null ) hi = p; else hiTail.next = p; hiTail = p; ++hc; } } ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) : (hc != 0 ) ? new TreeBin<K,V>(lo) : t; hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) : (lc != 0 ) ? new TreeBin<K,V>(hi) : t; setTabAt(nextTab, i, ln); setTabAt(nextTab, i + n, hn); setTabAt(tab, i, fwd); advance = true ; } } } } } }
2.4 transfer扩容并发度讨论 在jdk1.7的CHM中,它的并发度设计是相对受限的,在创建CHM中,可以指定CONCURRENCY_LEVEL的值来设并发度,遗憾的是:一旦创建好,CHM支持的并发度就不能更改。并且在jdk1.7的CHM中,指定的并发度设计的太大或者太小也会有问题:
并发太小时,多个线程都在竞争数量不多的segment加剧竞争,可谓“僧多粥少”
并发度设为太大时(例如segment并发度设为65535最大值),使得key原本可定位在同一个segment的读、写操作就会被分配到不同的segment中,结果是cpu cache命中率会下降,会在一定程度上降低CHM性能
而在jdk1.8创建CHM中,它不会限制并行度:
考察put/transfer方法,内部在桶位迁移用时synchronized锁住桶位头节点f的设计,也即锁粒度为桶位,那么随着transfer方法扩容CHM使得底层table更大后,因为锁粒度为桶位,因此并发度也随着变大,换句话说,jdk1.8的CHM的并发度是动态变化:并发度大小等于底层数组长度,底层数组每扩容1次,并发度就变大1倍,而不是像jdk1.7那样再创建期间并发度就被限制死了。
当然jdk1.8CHM的并发度因为是动态变大,当table容量太大时,也会面临cpu cache命中率会下降的性能问题。
2.5 CHM扩容时,可以同时支持读取get节点吗? 答案是支持的,CHM扩容完全不影响其他读线程读取key,为何?在“transfer方法桶位节点转移的处理逻辑”小节可以得到答案:
例如桶位的冲突链正在扩容,你发现它扩容时只是复制该链表的节点(ln = lastRun),也就是原链表还在桶位上,
1 2 3 4 5 6 7 8 9 10 11 if (runBit == 0 ) { ln = lastRun; hn = null ; } else { hn = lastRun; ln = null ; }
从红黑树的迁移更容易找到答案:
迁移线程将红黑树的节点复制到一条(lo—->loTail或者hi—->hiTail)或者两条新链表上(lo—->loTail以及hi—->hiTail),桶位上原链表结构(TreeNode的next属性构成)未发生任何改变,因此若此时有“读线程”来读桶位上key是完全OK的,不受扩容线程影响。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 else if (f instanceof TreeBin) { TreeBin<K,V> t = (TreeBin<K,V>)f; TreeNode<K,V> lo = null , loTail = null ; TreeNode<K,V> hi = null , hiTail = null ; int lc = 0 , hc = 0 ; for (Node<K,V> e = t.first; e != null ; e = e.next) { int h = e.hash; TreeNode<K,V> p = new TreeNode<K,V> (h, e.key, e.val, null , null ); if ((h & n) == 0 ) { if ((p.prev = loTail) == null ) lo = p; else loTail.next = p; loTail = p; ++lc; }
3、helpTransfer方法解析 有了上面transfer详细的多线程协同扩容细节铺垫后,那么helpTransfer方法则相当好理解:
该方法在CHM的相关“写操作”方法被调用,如:put、remove、replace、clear、compute、computeIfAbsent、merge,实际含义为:
当一个线程去对CHM进行写操作时(put、remove、replace、clear、compute、computeIfAbsent、merge)”,如果恰好遇到桶位节点是一个ForwardingNode节点,那么这个线程先转而去帮助当前CHM扩容。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 final Node<K,V>[] helpTransfer(Node<K,V>[] tab, Node<K,V> f) { Node<K,V>[] nextTab; int sc; if (tab != null && (f instanceof ForwardingNode) && (nextTab = ((ForwardingNode<K,V>)f).nextTable) != null ) { int rs = resizeStamp(tab.length); while (nextTab == nextTable && table == tab && (sc = sizeCtl) < 0 ) { if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 || sc == rs + MAX_RESIZERS || transferIndex <= 0 ) break ; if (U.compareAndSwapInt(this , SIZECTL, sc, sc + 1 )) { transfer(tab, nextTab); break ; } } return nextTab; } return table; }
4、addCount主分支2为何使用while循环 4.1 背景 只要CHM节点数量size达到扩容阈值且数组长度还未到最大值MAXIMUM_CAPACITY就可以进行扩容操作,这一点其实跟HashMap的扩容判断是一致的。
主分支2里面为何使用while 循环判断是否需要扩容呢? 就不能用if来取代吗?答案:不能,因为CHM是并发扩容,不是单线程的HashMap扩容操作,如果将主分支2的while改为if:
1 2 3 4 5 6 7 8 9 10 11 if (check >= 0 ) { Node<K,V>[] tab, nt; int n, sc; if (s >= (long )(sc = sizeCtl) && (tab = table) != null && (n = tab.length) < MAXIMUM_CAPACITY) { s = sumCount(); } } }
考察并发量高两种情形:
情况1:使得扩容完成的线程能继续加入未完成的扩容任务
在原table还有桶位未分配出去时,也即transferIndex>0,那么某线程A完成自己的桶位区间的节点迁移后,主分支2使用while语义就可以保证线程A继续加入到还未完成的扩容任务,而不是退出,显然线程A得到复用,而不需要创建新的线程,提高cpu效率。若使用if语义,当线程A完成自己的桶位区间的节点迁移后会直接退出,未充分利用已在执行态的线程A。
情况2:上一阶段刚扩容完因并发量高导致节点数量立即达到下一阶段扩容阈值
在CHM容量n0扩容到容量n1,有一扩容线程A完成扩容后退出,并发的其他线程很快把线程A扩容的容量n1的table写满,此时需要继续将容量n1的table扩容到容量n2(但线程A已经退出扩容处理),结果容量n2的新表很快又被并发的其他线程put满,此时急需第3次扩容(但线程A已经退出扩容处理),结果容量n3的新表很快又被并发的其他线程put满,以此类推…
所以你会发现:既然线程第1次扩容的n1很快会被并发的其他线程put满,那么可以这么设计:线程完成扩容transfer逻辑后先不结束线程,而是使用`while`强制安排线程继续判断CHM是否需要下一阶段扩容,如果需要下一阶段扩容,线程立即设置基础值然后进入transfer开始下一阶段扩容,复用已经处在执行态的线程,而不是去创建新线程。
4.2 线程会不会无限次扩容 按情况2的解释,线程岂不是无限次扩容?这就是次分支1要解决的情况,里面有一个break,显然这就是while循环结束点,所以线程不会无限扩容下去,那么满足什么条件线程才会break,这里就需要第5节的resizeStamp 技术点来解释,请参考之。
1 2 3 4 5 6 7 if (sc < 0 ) { if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 || sc == rs + MAX_RESIZERS || (nt = nextTable) == null || transferIndex <= 0 ) break ;
5、resizeStamp(n)以及sc变量的解析(CHM最关键的设计之一) 5.1 rs设计意图? resizeStamp方法和sc变量在transfer方法里面给我们造成很大困扰,它们的设计意图不好理解,resizeStamp是CHM的最关键设计之一,因此需要一步一步用位运算去探索和推演Doug Lea为何采用二进制的角度来实现sizeCtl支持多种状态标记以及rs扩容印记的设计,具体如下:
首先,使用场景肯定是用于扩容,不管从其方法命名还是从下面源码官方注释:
1 2 3 4 5 6 7 8 static final int resizeStamp (int n) return Integer.numberOfLeadingZeros(n) | (1 << (RESIZE_STAMP_BITS - 1 ));
第二点,可以用resizeStamp的值和sc变量来判断整个CHM扩容是否结束:
1 2 3 4 5 if (sc < 0 ) { if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 || sc == rs + MAX_RESIZERS || (nt = nextTable) == null || transferIndex <= 0 ) break ;
第三点,sc变量可以记录进入扩容逻辑的线程数量
1 2 if (U.compareAndSwapInt(this , SIZECTL, sc, sc + 1 )) transfer(tab, nt);
还可以实现对退出扩容逻辑线程的计数以及找出最后一个完成扩容的线程
1 2 3 4 5 if (U.compareAndSwapInt(this , SIZECTL, sc = sizeCtl, sc - 1 )) { if ((sc - 2 ) != resizeStamp(n) << RESIZE_STAMP_SHIFT) return ; finishing = advance = true ; i = n;
带着以上思路,现在以table长度n=16需要扩容进行逐步深入分析,以下全部计算过程采用位计算方式,Int类型为32位,分为高16位和低16位,第32位是符号位。
对于resizeStamp(16)有以下计算结果,其中Integer.numberOfLeadingZeros(n) 返回n对应的二进制高位0的个数,例如n=16,其高位0个数为32-5=27,假设现有一个线程A作为首个扩容线程,开始执行AddCount分支2流程:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 if (check >= 0 ) { Node<K,V>[] tab, nt; int n, sc; while (s >= (long )(sc = sizeCtl) && (tab = table) != null && (n = tab.length) < MAXIMUM_CAPACITY) { int rs = resizeStamp(n); if (sc < 0 ) { if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 || sc == rs + MAX_RESIZERS || (nt = nextTable) == null || transferIndex <= 0 ) break ; if (U.compareAndSwapInt(this , SIZECTL, sc, sc + 1 )) transfer(tab, nt); } else if (U.compareAndSwapInt(this , SIZECTL, sc, (rs << RESIZE_STAMP_SHIFT) + 2 )) transfer(tab, null ); s = sumCount(); } } }
计算int rs = resizeStamp(n=16);
1 2 3 4 5 0000 0000 0000 0000 0000 0000 0001 1011 # 27 0000 0000 0000 0000 1000 0000 0000 0000 # 1<<15 或运算结果如下,得到容量16的rs: 0000 0000 0000 0000 1000 0000 0001 1011 # 32795
可以看出:rs的低16位记录了“table长度16信息”,其设计意图是?
目的就是为了给table等于16这一容量值打上一个“戳(印记)”,或者称为”table长度为16的扩容印记”,简称“扩容印记”。
作为对比,假设table容量32需要扩容处理,那么table此时对应的“扩容印记”rs:
1 2 3 4 0000 0000 0000 0000 0000 0000 0001 1010 # 26 0000 0000 0000 0000 1000 0000 0000 0000 # 32768 或运算结果如下,得到容量32的rs: 0000 0000 0000 0000 1000 0000 0001 1010 # 32794
通过对比容量16和容量32的table扩容印记可知,不同容量下的扩容阶段都有其唯一“扩容印记”rs,那么只要线程在扩容时发现:前后读取的rs值不同,说明整个CHM已经完成上一阶段的扩容且正在进行下一阶段扩容,那么线程就可以直接退出,无需进入transfer方法,对应下面的代码片段的条件1用法:
1 2 3 4 5 6 7 8 9 10 11 12 13 if (check >= 0 ) { Node<K,V>[] tab, nt; int n, sc; while (s >= (long )(sc = sizeCtl) && (tab = table) != null && (n = tab.length) < MAXIMUM_CAPACITY) { int rs = resizeStamp(n); if (sc < 0 ) { if ((sc >>> RESIZE_STAMP_SHIFT) != rs || 其他4 个条件) break ;
因此(sc >>> RESIZE_STAMP_SHIFT) != rs 是表达这种场景:线程进入CHM扩容任务发现CHM已经结束了本阶段的扩容,因此线程无需参与到扩容任务中,退出即可。
5.2 sc相关位运算的设计意图? 条件1:sc >>> RESIZE_STAMP_SHIFT) != rs 已经由上面的小节详细分析,此小节尝试回答条件2:sc == rs + 1 和条件3:sc == rs + MAX_RESIZERS 设计目的?
不妨做个猜测:通过对比条件2和条件3发现,条件2像是sc变量的最小值,条件3像是sc变量允许的最大值,从最大值的MAX_RESIZERS含义可推出:扩容线程数量最大值,说明条件3可用于限制同时参与扩容线程的最大数量。根据条件3设计了扩容线程的上限,我们可以大胆推理出:条件2指的是当前CHM已经没有扩容线程在扩容了,也即所有扩容线程已经退出扩容任务,此时再来新的线程即可break
1 2 3 4 5 6 7 if (sc < 0 ) { if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 || sc == rs + MAX_RESIZERS || (nt = nextTable) == null || transferIndex <= 0 ) break ;
将上面基本猜测进行以下位计算的原理论证:
在第1节addCount给出的重要设计点“第一个执行扩容的线程”,它进入transfer方法前,将sc设为一个值:sc=(rs << RESIZE_STAMP_SHIFT) + 2,下面看看这个二进制串隐藏了什么“隐秘信息”,以容量16的戳印记rs为例
1 2 3 0000 0000 0000 0000 1000 0000 0001 1011 # 右移RESIZE_STAMP_SHIFT=16位后如下: 1000 0000 0001 1011 0000 0000 0000 0000 # 第32位是符号位,1表示负值
先看高16的含义:对比原来rs二进制串可知,“容量16的扩容印记”放在sc的高16位上。
再看低16位的含义:
第1个进入扩容的线程执行:sc=(rs << RESIZE_STAMP_SHIFT) + 2,对应二进制串:
1 1000 0000 0001 1011 0000 0000 0000 0010 # 低16位+2
第2个进入扩容transfer方法前,线程都会对sc加1操作
1 1000 0000 0001 1011 0000 0000 0000 0011 # 低16位+3
第3个进入扩容transfer方法前,线程都会对sc加1操作
1 1000 0000 0001 1011 0000 0000 0000 0100 # 低16位+4
易归纳:
1 1000 0000 0001 1011 1111 1111 1111 1111 # 低16位=65535
此时,低16位的值65535不就是Doug Lea设计的最大扩容线程数量:MAX_RESIZERS = (1 << (32 - RESIZE_STAMP_BITS)) - 1的值吗
以上流程可以得出这样一个规则:同一阶段扩容期,sc的高16位保持不变,对于sc低16位,除去第1个线程,后续每进一个扩容线程,低16位加1计数
综上,可以得出这样的结论:
① sc高16位是存放当前table容量的印记(扩容戳)信息,目的:只要是同一容量下CHM扩容,那么高16位的值固定不变
② sc低16位用于对参与扩容线程的计数。计数范围为: 0000 0000 0000 0010到1111 1111 1111 1111
在CHM还是扩容状态时,由高16位扩容印记的第32位1符号位可知,不管低16位现在记录了多少个扩容下线程,sc一定是负数,
因此在源码设计才有以下if (sc < 0) 成立就能判断出CHM还在扩容状态中。
1 2 3 4 5 6 7 8 9 10 11 int rs = resizeStamp(n); if (sc < 0 ) { if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 || sc == rs + MAX_RESIZERS || (nt = nextTable) == null || transferIndex <= 0 ) break ; else if (U.compareAndSwapInt(this , SIZECTL, sc, (rs << RESIZE_STAMP_SHIFT) + 2 ))
5.3 解析sc == rs + 1的真实含义(这是官方bug) 这个条件很诡异,首先线程进入if (sc < 0) 分支,说明sc是负数,在此之前rs = resizeStamp(n)扩容印记的计算结果是正值,那么sc == rs+1 以及sc == rs + MAX_RESIZERS (负数==正数)永远都不会成立,这个正是open jdk1.8的CHM出现一个重点bug。
本人一开始对此条件成立情况很是费解,但因为一直认为Doug Lea以及JSR-166 expert group在JUC造诣很深,因此还不曾怀疑此处设计有逻辑问题,接着出于要对resizeStamp方法和sc移位计算的设计彻底掌握的要求,去查阅了相关文章,恰好找到一篇高质量文章,它提到了这其实一个官方的bug:文章连接 ,到此本人才真正对sc == rs + 1诡异设计得到最官方的解决方案!! 这是官方bug描述的链接 ,bug已经java 12版本得到修复。本人在另外一篇文章中也详细给出了官方对这个bug的处理过程。
( [这篇关于CHM源码研究的文章](https://mp.weixin.qq.com/s/6HWJDKnNaceIEZQMOLZkog),作者水平确实不错,解析也足够细腻,但本人还是建议那些想要彻底掌握或者提升高级技术的人,切勿抄袭别人文章,务必独立完成相关源码的核心设计分析才能真正提升个人能力)
在去查阅了resizeStamp讨论的相关文章的过程中,你发下绝大部分的文章给出有效讨论真的很少,而且你会发现以下现象:
当前CSDN大量文章、微信公众号文章、以及所谓的JAVA进阶培训班绝大部分是基于针对jdk1.8CHM的源码解析,而且他们也不能解释`sc == rs + 1`的上下文计算过程及其设计目的,他们无法发现或者感知如此隐秘而有意义的bug,所以他们一般都会停留在表面类似这样源码解释:当前已经没有扩容线程在扩容或者参与扩容线程总数量达到最大值”
如果你已经吃透本文的所有分析,那么你应该可以猜出Doug Lea写这两行代码的含义如下:
sc=rs+1 其实是想表达sc=(resizeStamp(n)<<RESIZE_STAMP_SHIFT)+1,
而sc=rs+MAX_RESIZERS 其实是想表达sc=(resizeStamp(n)<<RESIZE_STAMP_SHIFT)+MAX_RESIZERS
用代码来表示其真正的写法如下所示
1 2 3 4 int rs = resizeStamp(n) << RESIZE_STAMP_SHIFT;if (sc<0 ) if (条件1 ||sc == rs + 1 || sc == rs + MAX_RESIZERS)
所以rs其实应该是这样的二进制串,显然是一个负数,这样才能使得sc == rs + 1在某个时刻成立
1 1000 0000 0001 1011 0000 0000 0000 0000
此外,因为rs已经是负值,那么在transfer有个地方不能直接用一开始计算的rs值,如下:
1 2 3 4 5 6 if (U.compareAndSwapInt(this , SIZECTL, sc = sizeCtl, sc - 1 )) { if ((sc - 2 ) != resizeStamp(n) << RESIZE_STAMP_SHIFT) return ;
因为transfer方法执行过程中,表示扩容状态下,rs的值已经是rs=resizeStamp(16) << RESIZE_STAMP_SHIFT ,也即rs位于sc的高16位上了:
1 1000 0000 0001 1011 0000 0000 0000 0000
如果使用((sc - 2) != rs << RESIZE_STAMP_SHIFT) 来判断,rs右移16位后,就变成0,此时sc没有实际含义:
1 0000 0000 0000 0000 0000 0000 0000 0000
因此这里不能用原来的rs值来判断条件,而是使用resizeStamp(n)重新计算rs值得出sc值是否等于原始基数,以此判断当前线程是否是最后一个退出扩容的线程
1 2 3 if ((sc - 2 ) != resizeStamp(n) << RESIZE_STAMP_SHIFT)等价于 if (sc != (resizeStamp(n) << RESIZE_STAMP_SHIFT) +2 )
基于以上详实的分析,才能真正从背后移位设计的原理去理解sc==rs+1含义:表示当前CHM已经没有扩容线程在扩容了,也即所有扩容线程已经退出扩容任务,此时再来新的线程即可break。
5.4 为何用sc=rs+1来判断所有扩容线程已经退出而不是用sc=rs+0或者sc=rs+2呢? 假设当前有1个线程是最后一个完成扩容的线程,它在transfer方法中准备执行以下逻辑:
1 2 3 4 5 6 7 8 if (U.compareAndSwapInt(this , SIZECTL, sc = sizeCtl, sc - 1 )) { if ((sc - 2 ) != resizeStamp(n) << RESIZE_STAMP_SHIFT) return ; finishing = advance = true ; i = n; }
以上逻辑等价于1 2 3 4 int sc=getAndAddInt(this ,sizeCtl,-1 )
因此如果当前线程最后一个完成扩容的线程,那么它执行完以上逻辑后,主存中sizeCtl的值为rs+1,因此之后的线程读取sc的值并来到以下逻辑就会发现② 位置的sc == rs + 1成立,说明“当前CHM所有扩容线程已经退出,本阶段的CHM扩容已完成,因此可直接break退出transfer” 1 2 3 4 5 6 7 8 9 10 int rs = resizeStamp(n); if (sc < 0 ) { if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 || sc == rs + MAX_RESIZERS || (nt = nextTable) == null || transferIndex <= 0 ) break ; else if (U.compareAndSwapInt(this , SIZECTL, sc, (rs << RESIZE_STAMP_SHIFT) + 2 ))
5.5 首次扩容时sc的基础值为何不是加1而是加2? 刚开始解析addCount源码时,让人无法理解的为何首个扩容线程进入扩容逻辑时是加2开始而不是加1开始计算呢,有点反正常思维。
1 2 3 4 else if (U.compareAndSwapInt(this , SIZECTL, sc, (rs << RESIZE_STAMP_SHIFT) + 2 )) transfer(tab, null );
考察sizeCtl=-1 这个特殊的-1,换成有符号的二进制串:
1 1000 0000 0000 0000 0000 0000 0000 0001 // ①低16位的最低位为1
对比容量16且从加1开始线程计数:
第1个扩容线程进入transfer时:sc=rs << RESIZE_STAMP_SHIFT) + 1
1 1000 0000 0001 1011 0000 0000 0000 0001 // ②低16位的最低位为1
第2个扩容线程进入transfer时:sc+1
1 1000 0000 0001 1011 0000 0000 0000 0002
对比①sizeCtl=-1和②的二进制串可知,两者低16位的最低位都是1,状态标记冲突了:
1 xxxx xxxx xxxx xxxx 0000 0000 0000 0001
考虑到:sc是用来扩容状态标记、sizeCtl也是用在initTable对sizeClt cas置-1的初始化标记,如果两者都取-1,就不好判断当前CHM的状态,因此Doug Lea为避免这种状态位的冲突,因此将扩容线程计数从加2开始计数。
虽然本文给出这样相对”牵强“的解释,但无法理解为何Doug Lea不在源码中给大家注释清楚?
6、sizeCtl状态小结 有了以上第4节和第5节深入的细节分析,现在可以总结sizeCtl也即sc取不同值的实际含义
sizeCtl为正值部分好理解:
① sizeCtl=0,默认值,在反序列化CHM对象时,如果CHM的size为0,那么此时sizeCtl设为0
② 当new CHM阶段,sizeCtl=table的初始默认容量或者指定的容量(会被修正为2的整数幂)
③ 当CHM扩容结束后,sizeCtl=下一次扩容阈值
对于负值部分的理解需要结合resizeStamp章节内容:
以table容量等于16作为分析,sizeCtl主要是以下四种特殊情况的负值:
① sizeCtl=-1。在new CHM后,第一次put入key,table为null,需要使用tab = initTable()方法初始化,多线程环境下,线程使用cas将 sizeCtl设为-1加锁做初始化工作。
② 第一个进入扩容线程将sizeCtl设为一个基础值:
1 1000 0000 0001 1011 0000 0000 0000 0010 // 最高位1,所以此值为负值
③ 达到最大扩容线程数量sizeCtl的值为:
1 1000 0000 0001 1011 1111 1111 1111 1111 // 最高位1,所以此值为负值
也即当CHM处于并发线程扩容时,sizeCtl的取值范围为:[rs+2,rs+65535]
④ 所有扩容线程退出扩容时,对应sc=rs+1:
1 1000 0000 0001 1011 0000 0000 0000 0001 // 最高位1,所以此值为负值
以上sizeCtl用于管理多线程并发操作与状态标记的背后原理。
小节 本文研究的重点放在CHM扩容设计逻辑上,不得不说,其并发源码写的确实高级,尤其是关于sizeCtl移位计数的逻辑设计让人佩服,也值得在项目尝试应用相关并发控制思想!