本文接前面ConcurrentHashMap文章的内容,继续深入到TreeBin这个特殊节点的读写锁竞争机制。
7、TreeBin类设计原理
对TreeBin类深入分析,不仅能够理解为何CHM能支持并发读的底层实现,而且也能加深jk1.8的ConcurrentHashMap整体设计原理。本文将详细深入地解析TreeBin优秀的读写锁控制设计,此部分内容在全网的相关文章很少涉及。
7.1 保证加锁对象不改变的设计思想
首先看其源码的注释说明:
TreeNodes used at the heads of bins. TreeBins do not hold user keys or values, but instead point to list of TreeNodes and their root. They also maintain a parasitic read-write lock forcing writers (who hold bin lock) to wait for readers (who do not) to complete before tree restructuring operations.
TreeBins节点不是用于放置key和value,而是用于指向TreeNodes和TreeNodes的根节点。TreeBins内部会维护一把读写锁,用于保证在树重构前,持有锁的写线程被强制等待无锁读线程完成。
当然这注释也未能回答这样核心问题:为何对于桶位是红黑树的情况下,CHM放置的一个TreeBin节点,而不像HashMap那样放置一个TreeNode节点?
首先看看TreeBin的使用场景,在put场景下:
1 | synchronized (f) { |
当key所在桶位可以放入key时,先对头节点加锁synchronized (f),注意这是独占锁,要求头节点对象在锁期间不会改变,否则就不能锁住同一对象。
为论证f头节点是TreeNode类型不适用并发的CHM场景,不妨假设CHM使用TreeNode作为CHM桶位上红黑树的头节点,于是在put场景下:
1 | // ① 假设当前头节点f是一个TreeNode节点,则执行流会进入②分支 |
这里关键是第③步逻辑:将key和value插入到红黑树当中,会发生什么事情?
我们知道,在HashMap节点,将一个节点put入红黑树后,需要做插入平衡处理和将红黑树root节点移到双向链表的头节点位置,目的是为了保证桶位上的头节点即是红黑树的根节点也是双向链表的头结点,下面就是HashMap对应的操作
1 | final TreeNode<K,V> putTreeVal(HashMap<K,V> map, Node<K,V>[] tab, |
但对于并发CHM来说,红黑树的插入平衡处理会导致root节点发生了改变(例如插入平衡前根节点是treeNodeA,插入平衡后根节点是treeNodeB)而不是位于桶位头节点上,如果CHM桶位头节点还是TreeNode,那么就会出现以下图示的不能保证写线程独占操作的线程不安全情况。
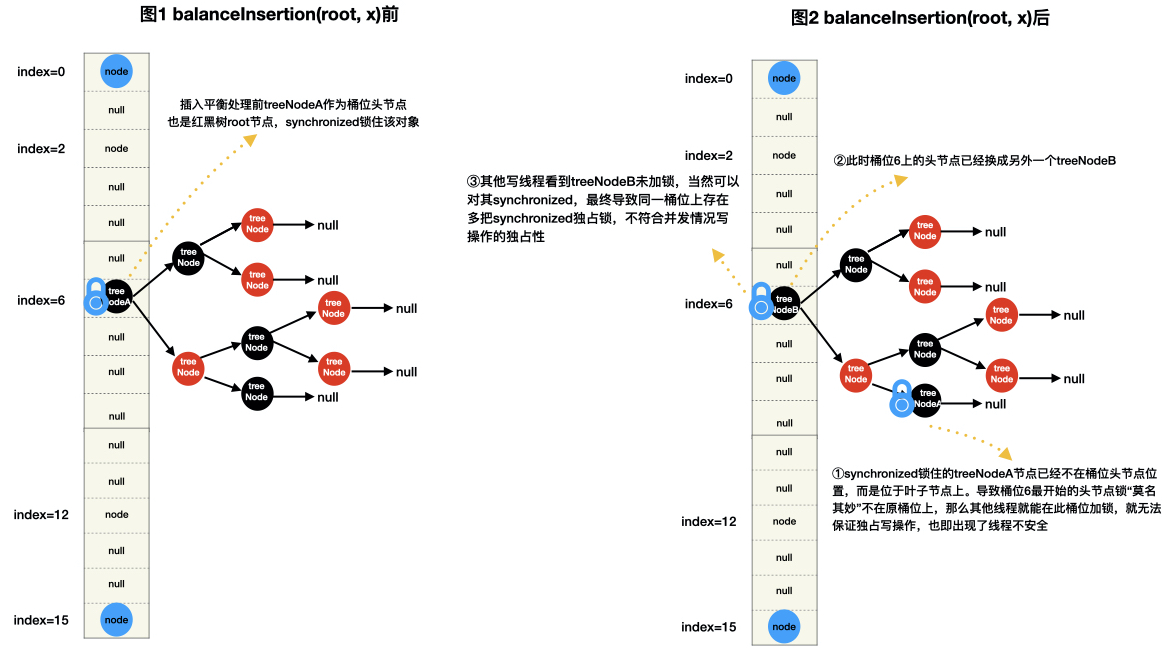
如何解决以上遇到的问题?
Doug Lea为此设计了TreeBin类(节点),该节点只放在桶位头节点上,它内部“包装”一棵红黑树(有些文章会跟你说TreeBin是 TreeNode的代理结点,其实意思都一样)。加锁时,对桶位头节点上TreeBin节点进行加锁,内部的红黑树根节点root在调整平衡后不管如何变化,当前桶位的加锁对象——TreeBin节点保持不变,也即保证写操作独占性,如下图所示。此外TreeBin还支持高级特性:并发环境下的读写锁控制机制。
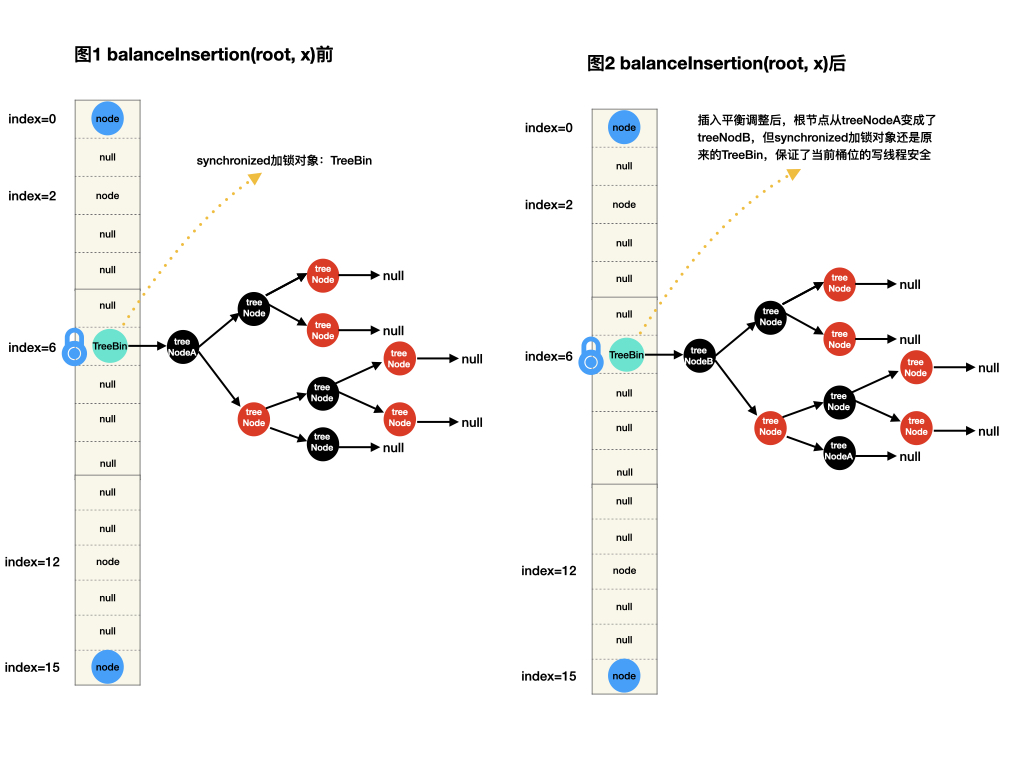
而且这样设计的TreeBin还有另外一个收益:无需进行类似HashMap的moveRootToFront 操作,因为桶头节点不再要求是
红黑树的根节点root,也不是链表的first头节点,而是一个包装了TreeNodes的TreeBin节点。
以下是HashMap的插入节点后需要做moveRootToFront 操作的源码片段:
1 | // putVal方法内部代码片段 |
以下是CHM插入新节点后的插入平衡操作:在插入平衡操作前,采用cas加锁机制,显然不同于HashMap,这个加锁机制有点复杂,目的是什么呢?在后面7.3小节会提到。
1 | else { |
此外,在源码中的lockRoot等地方的注释中,有个短语:tree restructuring,表示:红黑树重新调整结构。
而tree restructuring operations则表示:红黑树重新调整结构操作,具体来说是以下两个方法
put方面内部的putTreeVal方法以及remove方法内部的removeTreeNode方法,也即红黑树插入一个新节点需要触发tree restructuring 操作,红黑树删除一个节点需要触发tree restructuring 操作:执行tree restructuring操作前需要使用lockRoot()获取写锁,调整完后使用unlockRoot()释放写锁。
7.2 TreeBin类
TreeBin作为CHM内部类,有部分设计是新设计,用于解决高并发条件下的读写竞争问题,而另外一部分设计则沿用HashMap红黑树部分操作方法:如rotateLeft、rotateRight、balanceInsertion、balanceDeletion 等,这几个方法是在synchronized(f)独占锁条件系进行的,因此跟HashMap原来的执行机制类似,此处不再累赘。本章重点放在新的设计上。
7.2.1 基本的成员变量
基本成员变量具体使用在7.3小节的读写竞争设计给出,waiter、lockState以及lockState对应的三个标记值,再结合位运算方式,非常巧妙的实现了TreeBin读写锁竞争!
1 | static final class TreeBin<K,V> extends Node<K,V> { |
看完后文,你可以发现为何采用1、2、4这样的值,而不是1,2,3或者0,1,2或者2,4,6等,这与读写锁竞争的算法设计有关。
7.2.2 构造方法
以下只给出部分片段代码,省略部分的源码片段,其逻辑与HashMap类似,不再给出。
TreeBin构造方法目的只有一个:基于桶位链表构建一棵红黑树,例如在treeifyBin方法内部的 setTabAt(tab, index, new TreeBin<K,V>(hd))
TreeBin构造方法在treeifyBin方法被调用,此外还有以下两种情况也会调用TreeBin的构造方法,在优先重点关注”TreeBin构造方法在treeifyBin方法被调用”的场景。
1 | /** |
当然也可以使用逆向思维去找出“TreeBin构造方法”在什么场合被调用?
什么场景下,CHM的table桶位上才能放置一个TreeBin节点?
自然是桶位上已经是一棵红黑树?
那么桶位上的红黑树是怎么来?
桶位上的冲突链表达到树化阈值后,使用treeifyBin基于链表构建了红黑树。
找到答案:treeifyBin方法内部一定有TreeBin构造方法调用,如下:
1 | private final void treeifyBin(Node<K,V>[] tab, int index) { |
有人会问,进入②逻辑开始构建红黑树,但从代码上只看到拷贝了一条hd新链表的逻辑,完全没有构建红黑树的逻辑,这是怎么回事?
这是因为真正构建红黑树的逻辑是在new TreeBin此外还有以下两种情况也会调用TreeBin的构造方法:
1、在扩容阶段transfer方法里面,转移桶位链表到新table上是有对应的new TreeBin<K,V> ,也即在新table的i位置上基于低位节点链表构建红黑树,在新table的i+n位置上基于高位节点链表构建红黑树。
1 | ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) : |
2、将文件流(本地文件或者socket流)反序列为CHM对象时,readObject也会调用TreeBin的构造方法来构建红黑树实例。
1 |
|
7.2.3 putval方面 binCount = 2的含义?
在put操作里面,我们知道底层是调用了putval方法,有一个逻辑很难理解:
为何当前桶位节点是TreeBin节点时,binCount=2,而且不需要继续累加计数? 为何不是跟链表一样从1开始计数?(binCount计算当前桶位的节点数)
或者这么提问:binCount是用于统计桶位链表节点数量以便判断是否达到树化阈值,但TreeBin里面已经是一棵红黑树了,那么binCount岂不是没有什么实际意义?为何还需要binCount = 2,用意何在?
1 | else if (f instanceof TreeBin) { |
从7.2.2的构造方法的内容可知,桶位上的TreeBin节点是用下面这样的代码构建成的,以treeifyBin为例
1 | setTabAt(tab, index, new TreeBin<K,V>(hd)); |
这里的hd是桶位链表头节点,算1个,TreeBin本身算1个,共两个,这里binCount=2不是说TreeBin只有两个节点
1 | TreeBin(TreeNode<K,V> hd) { |
binCount=2的实际用意是:能够让addCount的分支2执行判断是否需要扩容,从而TreeBin的红黑树也可以被扩容
1 | //addCount(1L, binCount=2); |
7.3 TreeBin读写锁的设计
深度分析TreeBin读写锁的设计非常有利于理解CHM在红黑树结构上并发读写机制,而且TreeBin读写锁的设计也相当优秀。
在对TreeBin进行写操作时,由于已经使用了synchronized(f)独占锁语义,表示仅有一个写线程进入写操作,此设计解决了写线程与写线程之间竞争,而读线程和写线程之间的竞争如果采用synchronized方式,在高并发条件下性能无法接受。为了达到高性能的读写锁竞争,肯定需要熟悉的lock-free技术:CAS机制。
1 | else { |
1 | /** |
1 | /** |
对于lockState为0时,这种情况很好理解:写线程直接进入分支1竞争write lock
对于lockState不为0时,流程如下:
1、写线程首次进入for循环会直接进入分支2,因为此时lockState已经被1个或多个并发读线程cas加4满足分支2条件,写线程在此分支把自己变成waiter线程。
2、第2次循环时,写线程因为在首次循环将waiting设为true,因此会进入分支3,将自己挂起
3、分支1执行时机是:当其他读线程读完后(find到key)使用unpark唤醒写线程,此时写线程从挂起处执行,回到for循环进入分支1再继续竞争write lock
1 | for(;;) |
在理解以上“基于量化的分析”后,再通过以下的“定性说明”,则能掌握contendedLock的设计用意:
1、写线程发现有读线程正在读TreeBin,那么写线程首次进入for循环后,把自己变为waiter线程(意思是:我在等读线程完成),接着进入第2轮循环。
2、写线程在第2轮循环将自己挂起,避免自旋消耗cpu时间片
3、当“最后一个读线程”找到key并在退出前将写线程唤醒。
4、写线程唤醒后,进入第3轮循环,来到分支1去竞争写锁。
7.3.2 TreeBin读线程竞争read lock的设计
1 | public V get(Object key) { |
如果eh=-2,那么e节点是一个TreeBin节点,也即e.find方法最终调用的是TreeBin内部的find方法(对读线程来说这个find方法可称为读操作)。
其find方法主要设计思想:
1、如果TreeBin节点已经有写线程正在做写操作(插入平衡)或者有处于等待状态的写线程,那么当前读线程尝试用遍历链表的方式去读取节点。
2、如果当前读线程恰能在TreeBin节点cas加锁成功,那么读线程使用红黑树树查找方法快速找到节点,完了后使用unpark将“已经挂起的写线程也即waiter线程”唤醒。
1 | /** |
到了这里,我们可以根据分支1回答以下关键问题:
为何TreeBin读写竞争机制可以实现:即使有写线程在写,读线程依然可以并发读,不是说好的读写竞争吗(写的时候不能读)
这是因为:写线程在写操作时,是对红黑树做插入平衡操作,它只是用到了TreeNode的red、parent、right、left属性,别忘了TreeNode的设计中还有next属性,也即红黑树所有节点在背后已经通过next属性链成了一条链表,当红黑树调整时不会改变next属性,因此链表结构保持不变或者说写线程写操作不会影响到TreeNode的链表节点前后指向,那么就可以安排读线程用遍历链表的方式去读链表节点,所以才有了TreeBin以下的设计1 | // 写线程写时 或者写线程是waiter线程时,可使用TreeNode的next属性去遍历链表,实现读线程并发读也不会被写线程阻塞。 |
7.3.3 图示理解lockState如何控制读写线程
7.3.1和7.3.2给出非常详细解释了lockState位运算满足的条件及其设计目的,在此基础上结合以下图可深入掌握TreeBin设计的读写锁竞争机制,它是一个非常优秀的并发设计!
图1:仅有写线程情况下,逻辑简单不再给出图示。
假设TreeBin节点仅关联一个写线程,那么s的状态值变化很简单,0变为1,再从1变为0:
① 写线程进入lockRoot:cas(lockState,0,1),此时lockState从0变为1,表示写线程获得写锁
② 写线程完成写操作后调用unlockRoot:lockState = 0,此时lockState 从1变为0,表示写线程释放了写锁
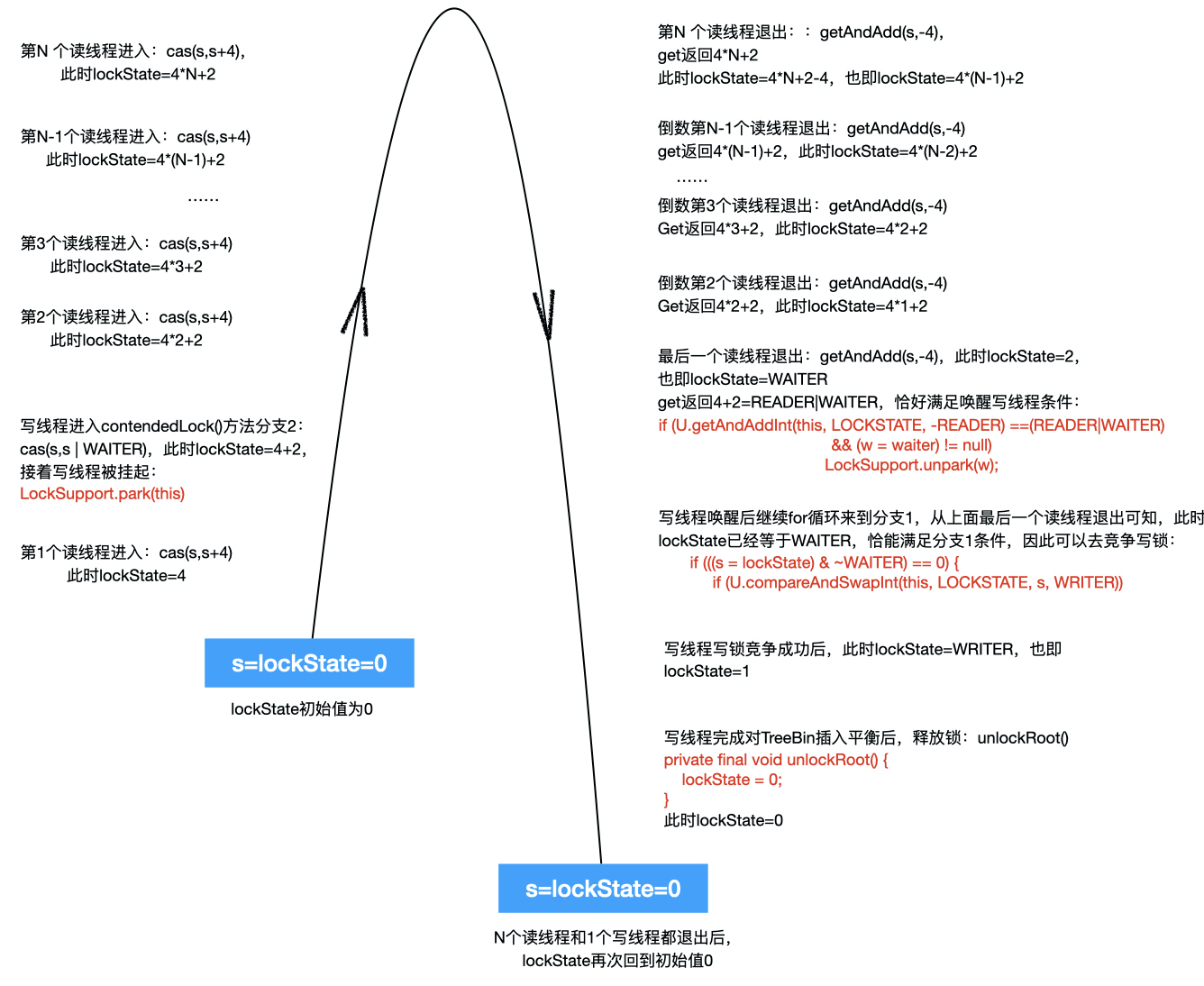
图2:假设当前有N个读线程且无写线程的情况下并发读TreeBin节点,不妨假设它们都是同一时刻进入find方法,完成读后,也是同一时刻退出find方法,那么lockState值变化如下图所示:
(此设计很像transfer方法里面扩容线程计数设计:扩容线程进入扩容操作时sc+1、退出扩容操作时sc-1。)
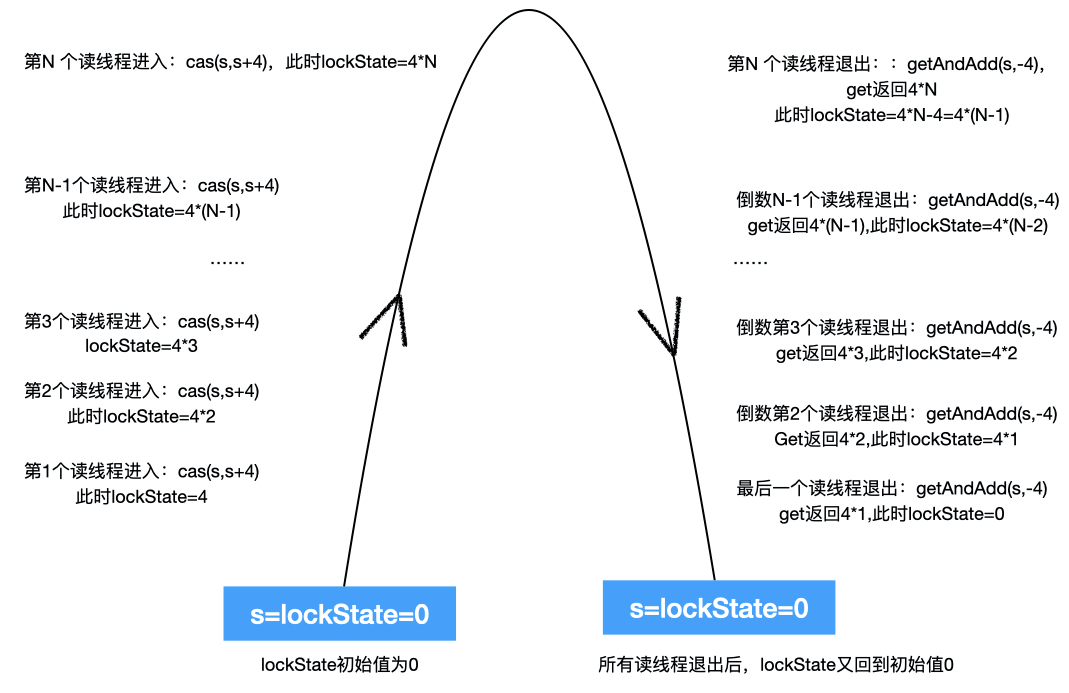
(此设计很像transfer方法里面的cas设计:扩容线程进入扩容时sc+1、退出扩容时sc-1,而且这里有个特殊点:lockState=4*N+2中的“+2”,从图中可以知道这个“+2”表示:目前还存在与TreeBin节点关联的唯一一个waiter线程。)
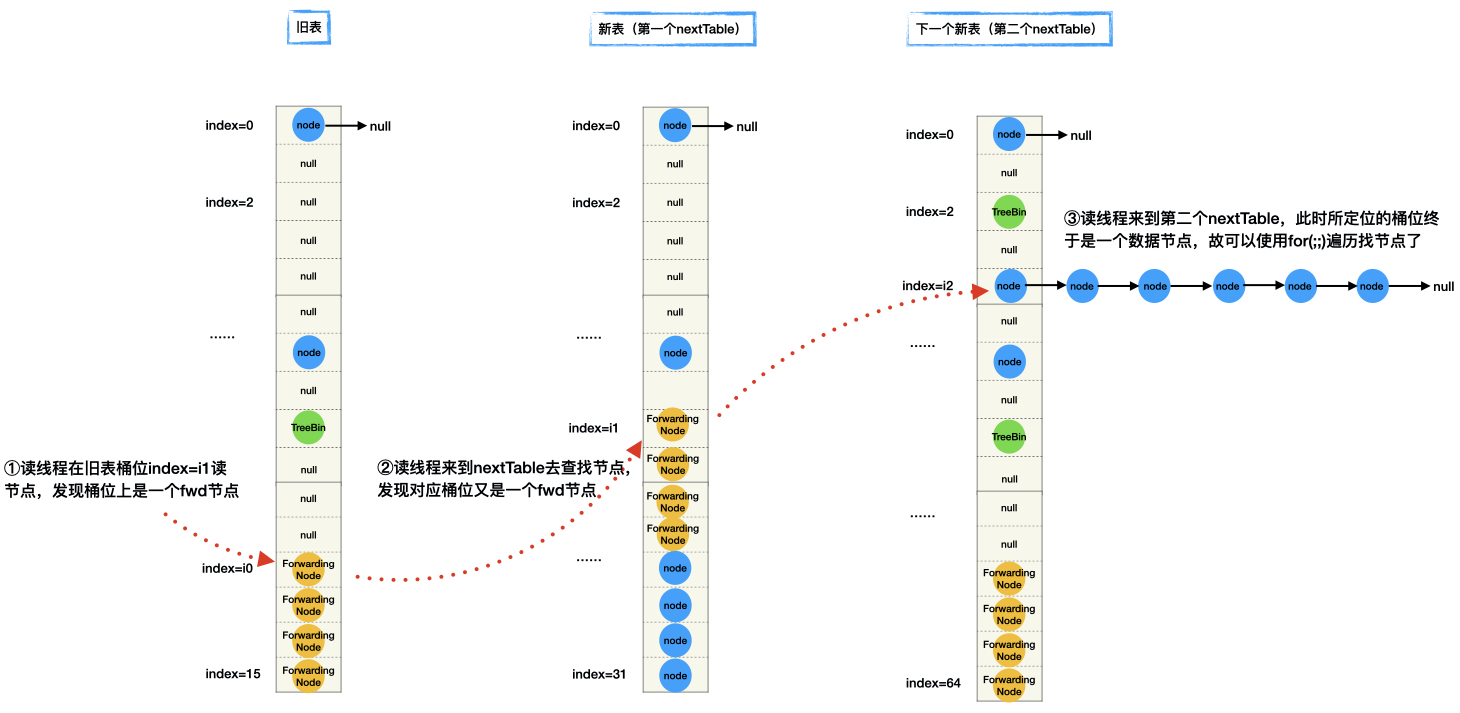
8、ForwardingNode节点分析
这个节点的设计相对简单:在扩容阶段,transfer方法中转移节点的那片逻辑里,当旧表桶位节点迁移到新表中后,会在旧表桶位上放置一个ForwardingNode节点,该节点的hash值为MOVED=-1,不存放key以及value。
还有一个nextTable属性以及内置一个读方法find,它们的设计意图是?解释如下:
在扩容阶段:对于桶位i,当旧表桶位节点迁移到新表中后,会在旧表桶位i上放置一个ForwardingNode节点
1 | setTabAt(nextTab, i, ln); |
当有读线程定位桶位i发现是一个fwd节点,就会调用其内部方法find去找key,但是当前桶位只是一个fwd节点,它没有key和value,那么读线程去哪里找key呢?
这就是nextTable属性的用意:读线程会去新表nextTable相应的桶位去找节点,这一点可以在以下源码的①位置得到证明。
1 | /* ---------------- Special Nodes -------------- */ |
在这片源码有个地方的写法比较陌生outer语法:也即 ①位置和③位置,它所要表达的逻辑如下图所示
1 | outer: for (Node<K,V>[] tab = nextTable;;) { |
用于解决这样的场景:
1、首先读线程在旧表读桶位i0时发现是一个fwd节点,读线程会转去新表(第一个nextTable)去读节点
2、接着读线程发现新表对应桶位i1又是一个fwd节点,说明新表(第一个nextTable)已经进入扩容期。
3、读线程只能继续转去下一个新表(第二个nextTable)找,发现对应桶位i2是正常的数据节点,那么就可以使用for(;;)读取数据节点。
可以看出outer设计目的是避免无限递归查找:新表的e.find ->递归>回到新表自己的e.find->…-> 无限递归