在前面有多篇关于jdk1.8的ConcurrentHashMap研究是基于源代码给出的深度分析,要知道多线程环境下的ConcurrentHashMap内部运行机制是相对复杂的,好在IDEA提供的相关断点和Debug功能确实好用,使得多线程调试起来直观,通过这种方式能加深多线程操作CHM的执行流程。
前期准备
这部内容请参考文章中的小节部分,本文不再累赘。
使用埋点打印法观测
此方法相对繁琐,难度并不大,要求使用者对源代码设计足够理解,否则埋点位置不佳影响观测效果
1、测试代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| package concurrent.demo;
public class ResizeStampBugTest {
public static void main(String[] args) {
int maxThreads = 64;
ConcurrentHashMap<Long, String> map = new ConcurrentHashMap<>(8);
for (int i = 0; i < maxThreads; i++) {
Thread t = new Thread(() -> map.put(Thread.currentThread().getId(),Thread.currentThread().getName()));
t.setName("Thread-"+i);
t.start();
}
}
}
|
可以看到这里ConcurrentHashMap类用的是项目concurrent.demo包下的ConcurrentHashMap.java 源码文件
2、更改桶位分配步长,将源码的16改为4,方便观察
1
2
| private static final int MIN_TRANSFER_STRIDE = 4;
|
3、transfer方法加入打印每个线程分配的桶位区间
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| else if (U.compareAndSwapInt
(this, TRANSFERINDEX, nextIndex,
nextBound = (nextIndex > stride ?
nextIndex - stride : 0))) {
bound = nextBound;
i = nextIndex - 1;
advance = false;
String s=String.format("%s分配的捅位区间为:[%d,%d]并挂起",Thread.currentThread().getName(),bound,i);
System.out.println(s);
LockSupport.park(this);
}
|
4、其他地方需要埋入打印语句
pulVal方法:当key定位到的桶位为空,直接放入key节点。
1
2
3
4
5
6
7
8
9
10
|
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null))) {
System.out.println(Thread.currentThread().getName() + "在桶位["+i+"]put入Node节点并退出");
break;
}
}
|
addCount方法:
1
2
3
4
5
6
7
8
9
10
11
12
| if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1)){
System.out.println(Thread.currentThread().getName()+"后续进入扩容逻辑transfer方法");
transfer(tab, nt);
}
}
else if (U.compareAndSwapInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2)){
System.out.println(Thread.currentThread().getName()+"第1个进入扩容逻辑transfer方法");
transfer(tab, null);
}
|
5、预期执行
打印结果如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| Thread-0在桶位[9]put入Node节点并退出
Thread-1在桶位[10]put入Node节点并退出
Thread-2在桶位[11]put入Node节点并退出
Thread-3在桶位[12]put入Node节点并退出
Thread-4在桶位[13]put入Node节点并退出
Thread-5在桶位[14]put入Node节点并退出
Thread-6在桶位[15]put入Node节点并退出
Thread-7在桶位[0]put入Node节点并退出
Thread-8在桶位[1]put入Node节点并退出
Thread-9在桶位[2]put入Node节点并退出
Thread-10在桶位[3]put入Node节点并退出
Thread-11在桶位[4]put入Node节点并退出
Thread-11第1个进入扩容逻辑transfer方法 # 注意此线程
Thread-12在桶位[5]put入Node节点并退出
Thread-12进入扩容逻辑transfer方法
Thread-13在桶位[6]put入Node节点并退出
Thread-13进入扩容逻辑transfer方法
Thread-14在桶位[7]put入Node节点并退出
Thread-14进入扩容逻辑transfer方法
Thread-15在桶位[8]put入Node节点并退出
Thread-12分配的捅位区间为:[12,15]并挂起
Thread-13分配的捅位区间为:[4,7]并挂起
Thread-14分配的捅位区间为:[0,3]并挂起
Thread-11分配的捅位区间为:[8,11]并挂起
|
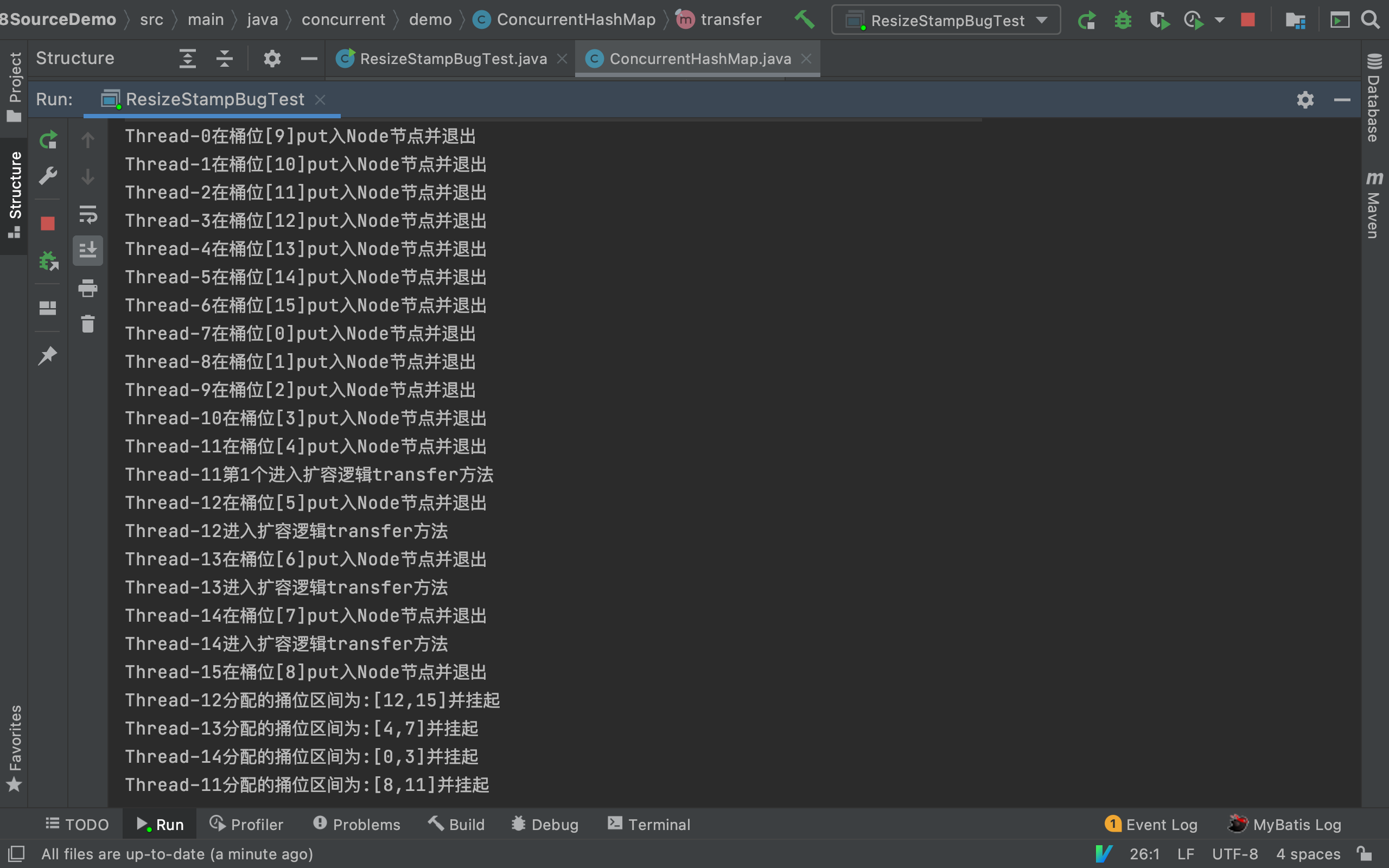
打印结果说明①
因为CHM的底层table容量为16也即有16个桶位, 此外使用线程ID作为节点的key,根据桶位定位算法i = (n - 1) & hash,前面16个线程(第0号线程到第15号线程)并发将16个key恰好能放到table16个桶位上,这也是为何将打印点放在putVal对应位置,线程put完后break退出后进入addCount,因此才有以下类似的打印:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| Thread-0在桶位[9]put入Node节点并退出
Thread-1在桶位[10]put入Node节点并退出
Thread-2在桶位[11]put入Node节点并退出
Thread-3在桶位[12]put入Node节点并退出
Thread-4在桶位[13]put入Node节点并退出
Thread-5在桶位[14]put入Node节点并退出
Thread-6在桶位[15]put入Node节点并退出
Thread-7在桶位[0]put入Node节点并退出
Thread-8在桶位[1]put入Node节点并退出
Thread-9在桶位[2]put入Node节点并退出
Thread-10在桶位[3]put入Node节点并退出
Thread-11在桶位[4]put入Node节点并退出
Thread-12在桶位[5]put入Node节点并退出
Thread-13在桶位[6]put入Node节点并退出
Thread-14在桶位[7]put入Node节点并退出
Thread-15在桶位[8]put入Node节点并退出
|
打印结果说明②
在打印结果中你会发现Thread-11的特别之处,如下:这个线程在put节点后进入addCount,此时因为前面第0号到10号线程总共put 入了11个节点,当线程Thread-11去put节点完后发现此时CHM节点数量达到扩容阈值12(16*0.75),
1
2
3
4
5
6
| ...
Thread-10在桶位[3]put入Node节点并退出
Thread-11在桶位[4]put入Node节点并退出
# Thread-11 写入节点后发现s达到扩容阈值
Thread-11第1个进入扩容逻辑transfer方法
...
|
因此线程Thread-11进入addCount方法的分支2且进入了扩容逻辑transfer,而且是作为第1个线程进入扩容逻辑
这就是为何要在addCount以下位置埋入打印点,捕获第1个进入扩容逻辑transfer方法的线程:线程Thread-11
1
2
3
4
5
| else if (U.compareAndSwapInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2)){
System.out.println(Thread.currentThread().getName()+"第1个进入扩容逻辑transfer方法");
transfer(tab, null);
|
打印结果说明③
因为继线程Thread-11put节点后使得s=12达到扩容阈值,因此后来的线程Thread-12、Thread-13、Thread-14在它们put完节点也发现需要扩容,因此也都进入的transfer方法,显然它们分别作为第2个、第3个、第4个进入transfer的线程。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| ...
Thread-11在桶位[4]put入Node节点并退出
Thread-11第1个进入扩容逻辑transfer方法
Thread-12在桶位[5]put入Node节点并退出
Thread-12进入扩容逻辑transfer方法
Thread-13在桶位[6]put入Node节点并退出
Thread-13进入扩容逻辑transfer方法
Thread-14在桶位[7]put入Node节点并退出
Thread-14进入扩容逻辑transfer方法
Thread-15在桶位[8]put入Node节点并退出
# 线程Thread-15没能进入扩容逻辑transfer方法
Thread-12分配的捅位区间为:[12,15]并挂起
Thread-13分配的捅位区间为:[4,7]并挂起
Thread-14分配的捅位区间为:[0,3]并挂起
Thread-11分配的捅位区间为:[8,11]并挂起
|
这里为何线程Thread-15没能进入transfer方法?还记得上面将桶位分配步长设为4的说明吗
1
2
| private static final int MIN_TRANSFER_STRIDE = 4;
|
因为一开始CHM容量为16,也即16个桶位,又因为桶位步长设定为4,因此只能有4个线程能成功cas分配到桶位区间。由于线程Thread-11第1个先进入transfer方法、线程Thread-12第2个进入、线程Thread-13第3个进入、线程Thread-14第4个进入,这4个线程恰好“瓜分”完16个桶位
1
2
3
4
| Thread-12分配的捅位区间为:[12,15]并挂起
Thread-13分配的捅位区间为:[4,7]并挂起
Thread-14分配的捅位区间为:[0,3]并挂起
Thread-11分配的捅位区间为:[8,11]并挂起
|
之后transferIndex=0,表示全部桶位已经分配出去,那么再来的线程Thread-15,恰好满足下面条件transferIndex <= 0) ,因此Thread-15不能进入transfer并break结束
1
2
3
4
5
| if (sc < 0) {
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0){
break;
|
为什么线程Thread-11、Thread-12、Thread-13、Thread-14在transfer方法分配完桶位区间后没有退出?
这就是为何使用LockSupport.park(this)将线程挂起的原因,以便持续观察CHM的桶位分配机制,同时也能将CHM容量16扩容到32的过程暂停,使得CHM停留在第一轮扩容的过程中,而且暂停在桶位分配完之后,节点迁移之前。
“使得CHM扩容处理流程暂停在第一轮扩容的过程中”,这有什么用处呢,请看下面:
打印结果说明④
在AddCount方法下面位置埋入打印语句:
1
2
3
4
5
6
| if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0){
System.out.println(Thread.currentThread().getName()+"因无桶位可分配,此线程直接退出");
break;
}
|
目的就是考察线程Thread-11、Thread-12、Thread-13、Thread-14在transfer方法分配完桶位区间后并挂起,后续的Thread-15到Thread-63是如何安排的
打印如下:其实无需打印也能知道,因为Thread-15进入AddCount分支2后,transferIndex已经是0,也即无桶位可分配,只好break退出,后面来更多的其他线程也同理。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
| Thread-15在桶位[8]put入Node节点并退出
Thread-15因无桶位可分配,此线程直接退出
Thread-16因无桶位可分配,此线程直接退出
Thread-17因无桶位可分配,此线程直接退出
Thread-18因无桶位可分配,此线程直接退出
Thread-19因无桶位可分配,此线程直接退出
Thread-20因无桶位可分配,此线程直接退出
Thread-21因无桶位可分配,此线程直接退出
Thread-22因无桶位可分配,此线程直接退出
Thread-23因无桶位可分配,此线程直接退出
Thread-24因无桶位可分配,此线程直接退出
Thread-25因无桶位可分配,此线程直接退出
Thread-26因无桶位可分配,此线程直接退出
Thread-27因无桶位可分配,此线程直接退出
Thread-28因无桶位可分配,此线程直接退出
Thread-11分配的捅位区间为:[12,15]并挂起
Thread-13分配的捅位区间为:[4,7]并挂起
Thread-14分配的捅位区间为:[0,3]并挂起
Thread-12分配的捅位区间为:[8,11]并挂起
Thread-29因无桶位可分配,此线程直接退出
Thread-30因无桶位可分配,此线程直接退出
Thread-31因无桶位可分配,此线程直接退出
Thread-32因无桶位可分配,此线程直接退出
Thread-33因无桶位可分配,此线程直接退出
Thread-34因无桶位可分配,此线程直接退出
Thread-35因无桶位可分配,此线程直接退出
Thread-36因无桶位可分配,此线程直接退出
Thread-37因无桶位可分配,此线程直接退出
Thread-38因无桶位可分配,此线程直接退出
Thread-39因无桶位可分配,此线程直接退出
Thread-40因无桶位可分配,此线程直接退出
Thread-41因无桶位可分配,此线程直接退出
Thread-42因无桶位可分配,此线程直接退出
Thread-43因无桶位可分配,此线程直接退出
Thread-44因无桶位可分配,此线程直接退出
Thread-45因无桶位可分配,此线程直接退出
Thread-46因无桶位可分配,此线程直接退出
Thread-47因无桶位可分配,此线程直接退出
Thread-48因无桶位可分配,此线程直接退出
Thread-49因无桶位可分配,此线程直接退出
Thread-50因无桶位可分配,此线程直接退出
Thread-51因无桶位可分配,此线程直接退出
Thread-52因无桶位可分配,此线程直接退出
Thread-53因无桶位可分配,此线程直接退出
Thread-54因无桶位可分配,此线程直接退出
Thread-55因无桶位可分配,此线程直接退出
Thread-56因无桶位可分配,此线程直接退出
Thread-57因无桶位可分配,此线程直接退出
Thread-58因无桶位可分配,此线程直接退出
Thread-59因无桶位可分配,此线程直接退出
Thread-60因无桶位可分配,此线程直接退出
Thread-61因无桶位可分配,此线程直接退出
Thread-62因无桶位可分配,此线程直接退出
Thread-63因无桶位可分配,此线程直接退出
|
以上就是使用埋入打印点调试transfer机制,通过“print”来观察其运行机制先对入门,其实debug模式才是真正便捷的调试方式,继续查阅下面内容。
使用IDEA 断点debug方式观测
1、只需在transfer以下位置打一个断点即可,也即在桶位区间cas分配的逻辑里的advance=true,如下,
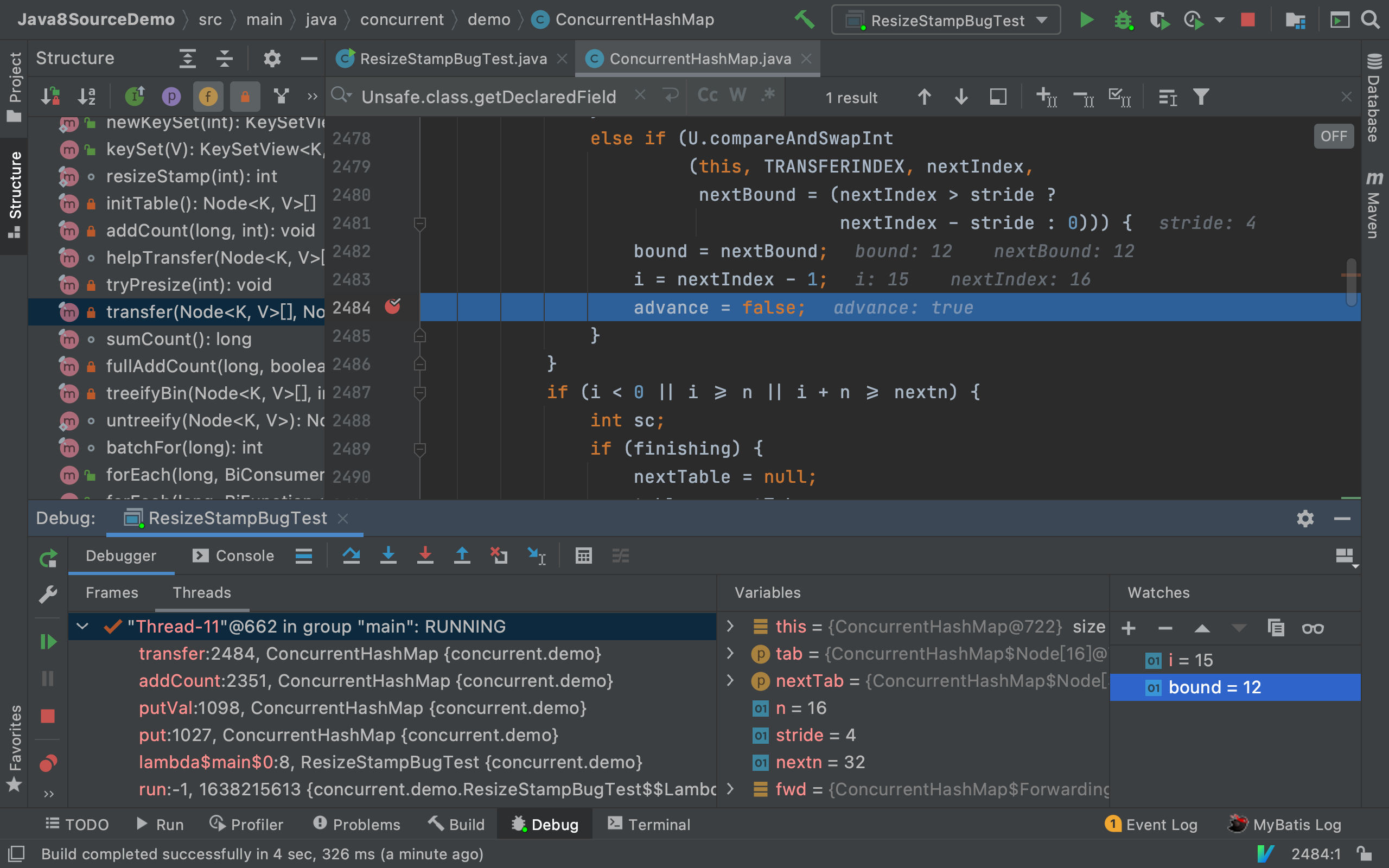
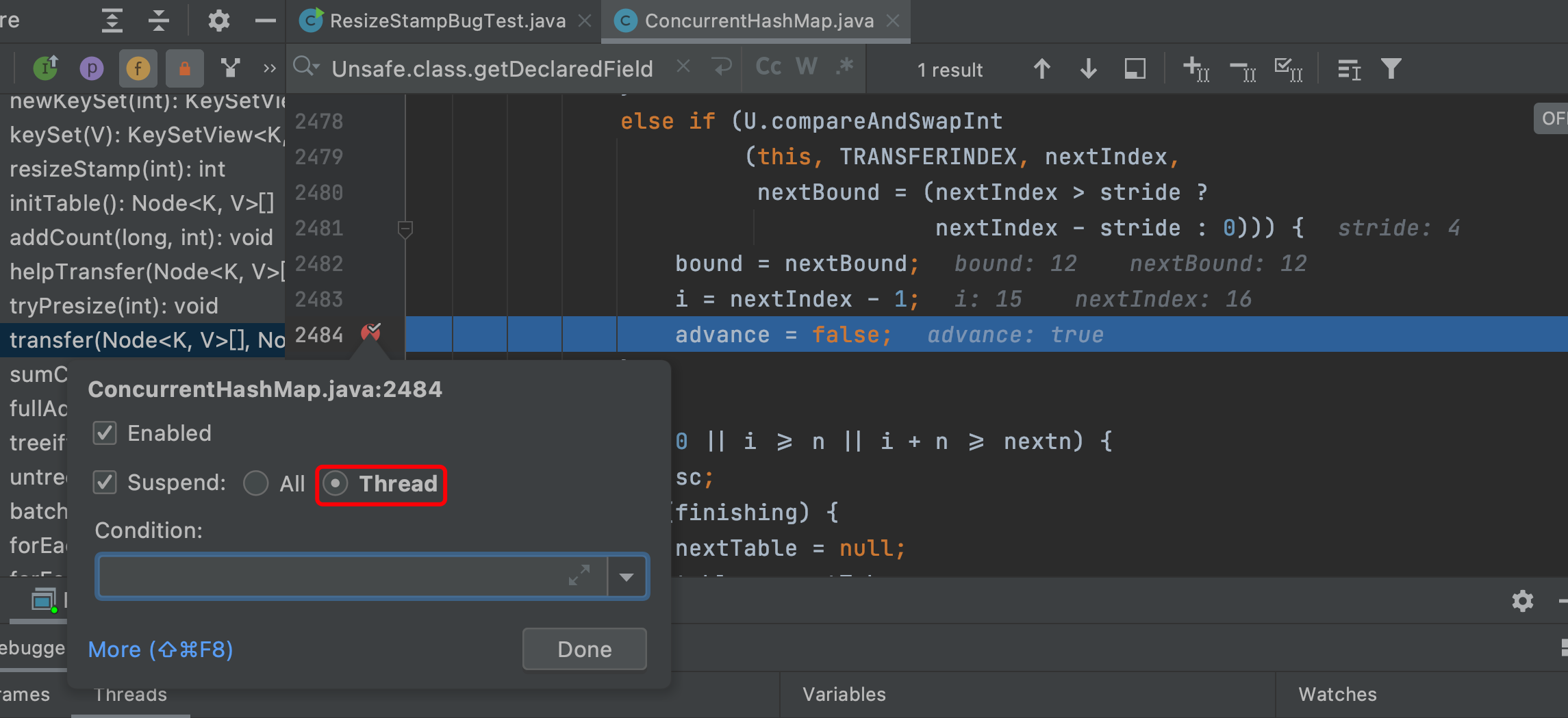
并将断点的Suspend设为Thread,如下:
2、启动debug,IDEA进入debug操作,此处无需图。
3、在Watchs栏目加入要“观测的变量”,这里当然是关注每个线程分配到的桶位区间的左边界bound和右边界i
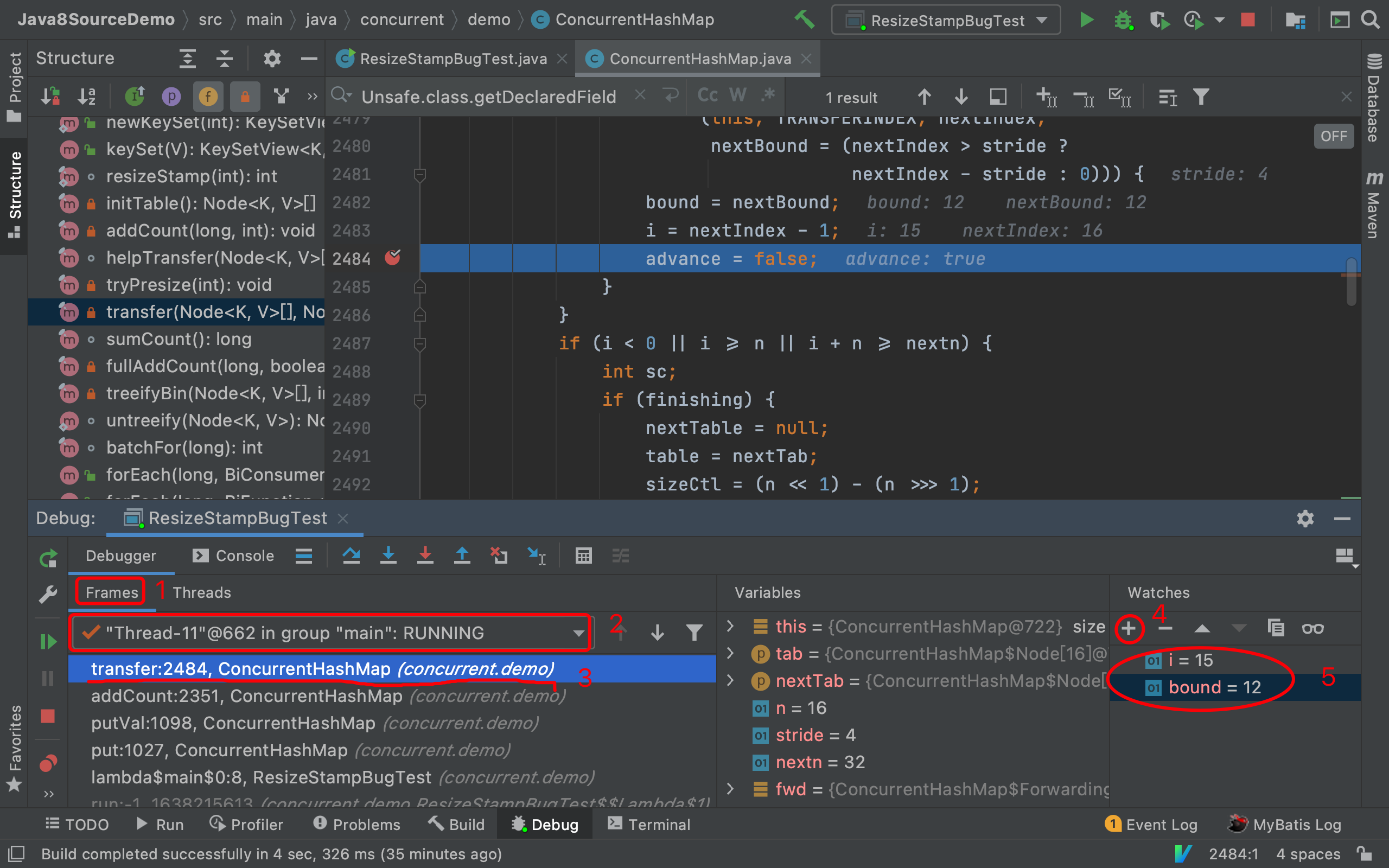
Frames栏目可以显示每个线程的方法调用栈,在点选Thread-11作为观察目标,你可以清晰看到Thread-11的方法调用栈:
1
2
3
4
5
| transfer
addCount
putval
put
main主函数入口
|
点选“transfer”方法帧,然后右侧Variables栏目会展示该方法内部的局部变量值,由于我们想观测线程桶位区间的左边界bound和右边界i,因此在Watches加入这两个变量,图中可以非常直观看出Thread-11的桶位区间为[bound=12,i=15]
若想看其他线程分配的桶位,很简单,在下拉框选中其他线程即可,如Thread-12,可以在Watches栏目看到Thread-12的桶位区间为[bound=8,i=11]
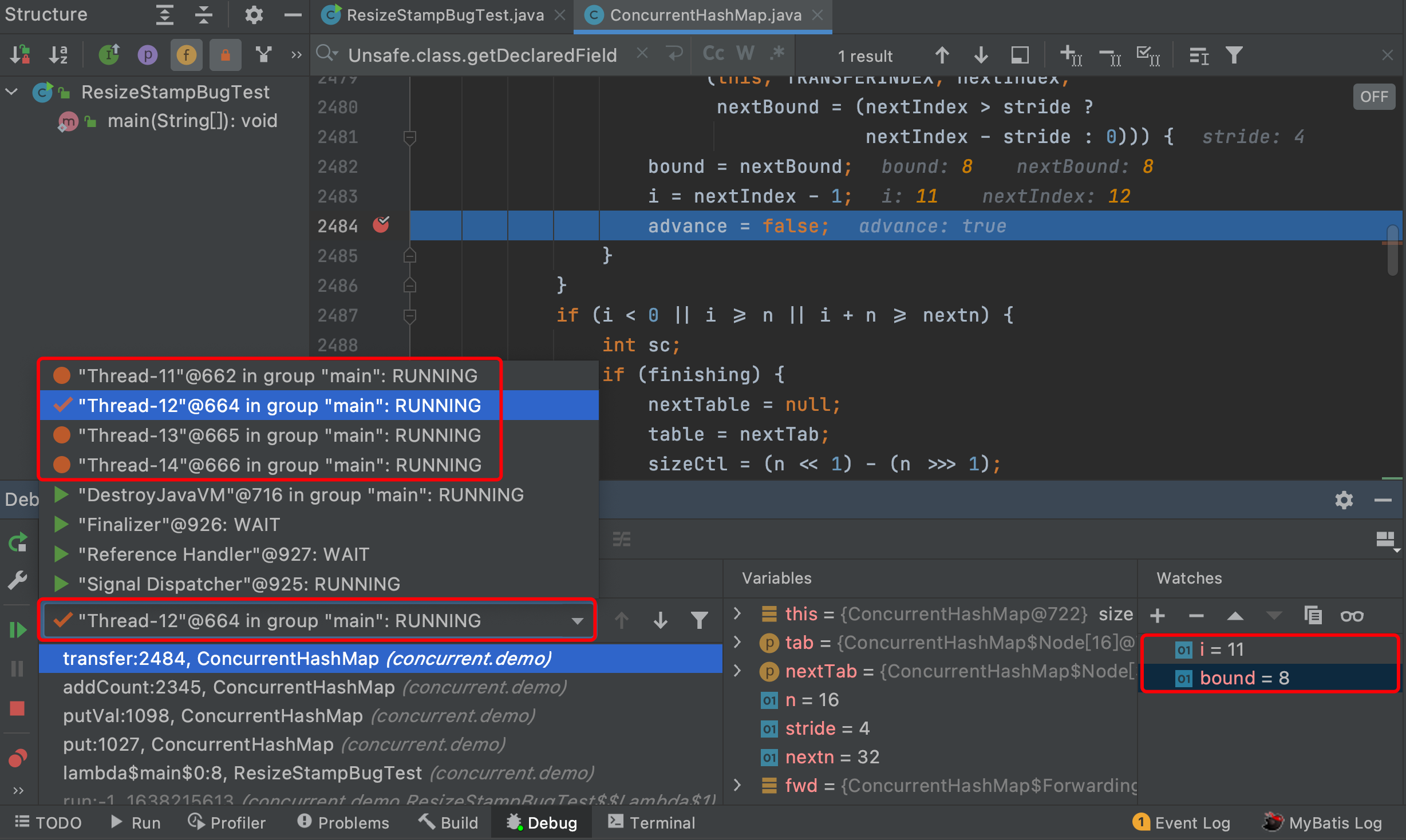
同理也可以看出Thread-13、Thread-14的界面,这里不再一一展示。
5、所观测的方法帧里面的变量和Watches对应

如上图所示,Watches提示无法找到局部变量i和局部bound变量,这是因为当前观测的是在addCount这个方法帧,显然
addCount内部没有i和bound变量。此外,也可从addCount的局部变量表Variables栏目看Watches是否在里面。
为何Frames只显示4个线程在RUNING状态?
答案已经在第一小节的“使用埋点打印法观测”后面给出了详细的解释,这里也简要说明:
(1)第0到第15号线程put完节点后,其中第0到第10号线程结束退出,第11号线程发现put完后CHM节点数量达到扩容阈值12,因此进入AddCount分支2,并作为第1个进入扩容逻辑transfer的线程,故Thread-11分配到了桶位区间[12,15]
(2)线程Thread-12、Thread-13、Thread-14 put完节点也因为s节点数量达到扩容阈值,都进入到transfer方法,也分配到对应的桶位区间
(3)等线程Thread-15 put完节点后,发现已无桶位可分配,因此Thread-15 结束
(4)其他剩余的线程第16到第63号线程也同样因为“已无桶位可分配而结束”
小结
可以看出,IDEA调试并发环境的CHM确实小有难度,最好能在掌握源代码情况下debug,通过这种实践而非源代码分析的观测方式,你能任意控制多线程并发执行流以及观测其内部协调机制、竞争机制,从而能深入掌握JUC并发设计和源代码实现。