本文基于本博客已发布的CHM文章中分析fullAddCount方法基础上,介绍LongAdder这个高并发计数性能,并通过与原子计数器AtomicLong进行比较,最后给出Striped64类相关分析(因其内部真正实现了高并发计数逻辑)。
为何需要介绍下LongAdder类?
因为在fullAddCount方法的定义上,因为在CHM源代码上,Doug Lea有提到:fullAddCount的设计原理可通过LongAdder这个类得到相关解释::
1 | // See LongAdder version for explanation |
1、两种并发计数器的性能比较
longAdderCost和atomicLongCost的目的:指定一定数量的线程并发执行该逻辑:每个线程计数从0增加到1000*1000
1 | package juc.demo; |
输出结果如下:
1 | LongAdder:线程数为1,计算1000000次,总用时205ms |
对以上数据进行作图如下:

可以非常清楚看到两者存在性能差异:
(1)剔除单线程数据,LongAdder并发计数耗时最少,并且随着线程数量增加,并发计数耗时趋势相对稳定
(2)剔除单线程数据,AtomicLong并发计数耗时长,并且随着线程数量增加,并发计数性耗时基本呈指数上升趋势
2、两者性能差异的原因分析
2.1 单线程情况
首先对于单线程情况下,也即线程数量为1,因为LongAdder的increment方法里面调用add方法且在add方法内部需要做一些基本判断,这些代码的执行需要消耗一定时间:
1 |
|
对比atomicLong.incrementAndGet()方法:该方法直接进行计数,代码执行流程显然比上面要快
1 | public final long incrementAndGet() { |
因此单线程情况下,从实际测试结果来看,AtomicLong肯定会比LongAdder快
2.2 多线程并发计数情况
当线程数量开始增加时,LongAdder计数比AtomicLong快,要知道这两个都是使用lockness机制也即Unsafe的CAS去实现的,为何两者性能差距这么明显?
主要还是两者的设计思路导致的
(1)对于AtomicLong来说:incrementAndGet方法如下
1 | public final long incrementAndGet() { |
内部调用的是getAndAddLong方法,如下:
1 | public final long getAndAddLong(Object o, long offset, long delta) { |
可以看到其设计相对简陋,如下图所示:

while自旋+对offset进行CAS加delta值计数,也即当有1000个线程并发去incrementAndGet时,由于线程竞争激烈,导致每轮自旋只能有1个线程成功拿到本轮的CAS,那么最后效果:越多线程参与计数效率就越慢,因为竞争激烈时,可能有一部分线程一直竞争CAS都失败,它们占用cpu时间片不说,还未做“加1计数”的贡献。
打个通俗比喻:
有一个窗口放着一个小黑版,上面写着一个count,小黑板每次只让一个人对其加1计数,如果采用AtomicLong的“while自旋+CAS”设计,当有1000个人同时想在小黑板做加1计数时,每轮只能有一个人走到窗口前在小黑板加1,只要这个人还没写完,那么其他999个人就得一起不断来回走到窗口前看看能否抢到“小黑班写的权利”,显然这种“一起来回走动”浪费资源,效率也低。
(2)对于LongAdder来说:increment内部其实使用是相对高效的、能降低线程竞争的设计:longAccumulate,其实也是ConcurrentHashMap里面的fullAddCount方法,原理图在CHM的源代码已经给出,如下图所示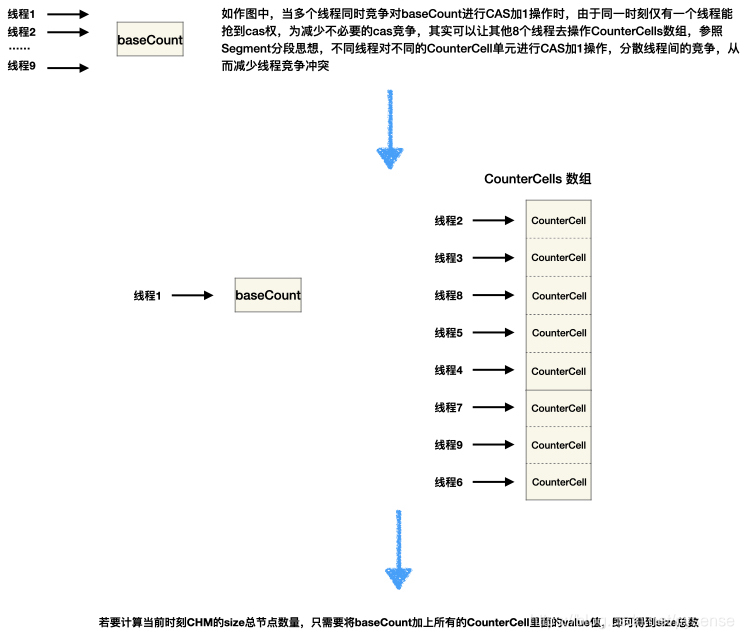
设计思想:
(1)当线程竞争不激烈情况下,通过自旋+cas对baseCount进行加1计数,这一阶段类似AtomicLong的计数逻辑
(2)当线程竞争十分激烈的情况下,有一部分线程很幸运能够抢到cas权力成功对baseCount加1,而剩下对baseCount加1cas失败的线程,它们就会创建一个CounterCells计数的数组,然后线程给对应自己的桶位Cell对象进行cas加1操作,这样一来就实现了“线程分流”,减少竞争。
亮点设计在于这个“CounterCells计数的数组”
打个通俗比喻(同上):
当人数量少时,开1个窗口给他们在小黑板写
当人数量多,多开几个窗口,例如开8个窗口,每个窗口都放置一块小黑板,那么
每个窗口平均下来也就125个人在竞争,相比于之前1000个人激烈竞争1个窗口,
这个窗口最大数量跟cpu数量一致,能充分利用每个cpu core,显然性能就上来了。
其实两者的性能说明在LongAdder的源代码注释已给出:
This class is usually preferable to AtomicLong when multiple threads update a common sum that is used for purposes such as collecting statistics, not for fine-grained synchronization control. Under low update contention, the two classes have similar characteristics. But under high contention, expected throughput of this class is significantly higher, at the expense of higher space consumption.
在线程竞争不激烈的写(更新)操作,两者性能类似。在线程竞争激烈情况下,也即线程并发高时,LongAdder拥有更高的throughput(一般指吞吐量,在这里可以理解为并发计数量),但代价是占用更多内存(上面的例子代价就是多开几个窗口)
LongAdder是典型的空间换时间的设计!
3、Striped64类分析
考虑到CHM的fullAddCount源代码设计其实就是LongAdder里面的longAccumulate方法而该方法来自Striped64类,因此本文不再给出longAccumulate的源代码解析,具体可参考之前的文章:
关于LongAdder类,因为其源代码设计简单,也不再作为详细说明,本文重点讲解Striped64的设计:
LongAdder继承自Striped64
1 | public class LongAdder extends Striped64 implements Serializable { |
Striped64继承自Number,源代码总共413行
1 | abstract class Striped64 extends Number { |
3.1 Cell内部类
在线程对base cas发生激烈冲突时,线程通过创建Cell数据并对桶位上的Cell进行cas加值操作,可以看到其内部独立使用了Unsafe机制,并且定义了一个更新值的cas方法:
1 |
|
Striped64的Cell类对比CHM fullAddCount CounterCell计数类
1 | /* ---------------- Counter support -------------- */ |
3.2 其他成员变量
1 |
|
至于这里为何这里键值对:(当前线程,线程对应的随机值)中线程对应的随机不是用java.util.Random生成?这是因为ThreadLocalRandom比Random更适合用在高并发情况,这里说的更适合是指“生成随机数性能更高而且与当前线程关联”,关键点为:ThreadLocalRandom,每个线程都有自己seed用于生成随机数:
1 | static final void localInit() { |
3.3 longAccumulat
longAccumulat设计跟CHM里面的fullAddCount设计一致,只不过这里多了参数: update function
1 | /** |
这个 update function有什么用呢?如下:
例如定义个匿名函数
1 | x -> 2 * x +1 |
那么每次cas就可以不只是cas(this,value1,value2)这种形式,而是cas(this,value1,fn(value2)能对value2进一步处理后再给到cas放入主存中。
调用点1:
1 | else if (!wasUncontended) // CAS already known to fail |
调用点2:
1 |
|
与longAccumulat类似逻辑的是double类型的doubleAccumulate高并发计数方法,这里不再累赘。
个人认为Striped64类里面表达最重要信息之一是:源码内部的详细代码功能注释说明,本文不再一一翻译,所有详细的设计和逻辑都在CHM文章中fullAddCount章节给出非常详细的解析,因此你可以基于源码的理解来对照以下官方源码注释:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
* 1、首先介绍Striped64类数据结构:底层是可原子写操作的table+base变量
* This class maintains a lazily-initialized table of atomically
* updated variables, plus an extra "base" field. The table size
* is a power of two. Indexing uses masked per-thread hash codes.
* Nearly all declarations in this class are package-private,
* accessed directly by subclasses.
*
* 2、Cell类的设计说明
* Table entries are of class Cell; a variant of AtomicLong padded
* (via @sun.misc.Contended) to reduce cache contention. Padding
* is overkill for most Atomics because they are usually
* irregularly scattered in memory and thus don't interfere much
* with each other. But Atomic objects residing in arrays will
* tend to be placed adjacent to each other, and so will most
* often share cache lines (with a huge negative performance
* impact) without this precaution.
*
* 3、Cells[] 数组的设计目的
* In part because Cells are relatively large, we avoid creating
* them until they are needed. When there is no contention, all
* updates are made to the base field. Upon first contention (a
* failed CAS on base update), the table is initialized to size 2.
* The table size is doubled upon further contention until
* reaching the nearest power of two greater than or equal to the
* number of CPUS. Table slots remain empty (null) until they are
* needed.
*
* 4、设计cellsBusy锁的目的
* A single spinlock ("cellsBusy") is used for initializing and
* resizing the table, as well as populating slots with new Cells.
* There is no need for a blocking lock; when the lock is not
* available, threads try other slots (or the base). During these
* retries, there is increased contention and reduced locality,
* which is still better than alternatives.
*
* 5、Thread probe用于定位在Cells数组哪个桶位
* The Thread probe fields maintained via ThreadLocalRandom serve
* as per-thread hash codes. We let them remain uninitialized as
* zero (if they come in this way) until they contend at slot
* 0. They are then initialized to values that typically do not
* often conflict with others. Contention and/or table collisions
* are indicated by failed CASes when performing an update
* operation. Upon a collision, if the table size is less than
* the capacity, it is doubled in size unless some other thread
* holds the lock. If a hashed slot is empty, and lock is
* available, a new Cell is created. Otherwise, if the slot
* exists, a CAS is tried. Retries proceed by "double hashing",
* using a secondary hash (Marsaglia XorShift) to try to find a
* free slot.
*
* 6、capped翻译为:用...封顶(盖住) Cells数组长度最大只能扩容到和CPU数量相同
* The table size is capped because, when there are more threads
* than CPUs, supposing that each thread were bound to a CPU,
* there would exist a perfect hash function mapping threads to
* slots that eliminates collisions. When we reach capacity, we
* search for this mapping by randomly varying the hash codes of
* colliding threads. Because search is random, and collisions
* only become known via CAS failures, convergence can be slow,
* and because threads are typically not bound to CPUS forever,
* may not occur at all. However, despite these limitations,
* observed contention rates are typically low in these cases.
*
* 7、在Cells数组有些桶位的Cell可能没被线程命中用于CAS加值计数,但没关系,不用理会它,也不需要去找到这的Cell桶位然后删除之(画蛇添足)。
* It is possible for a Cell to become unused when threads that
* once hashed to it terminate, as well as in the case where
* doubling the table causes no thread to hash to it under
* expanded mask. We do not try to detect or remove such cells,
* under the assumption that for long-running instances, observed
* contention levels will recur, so the cells will eventually be
* needed again; and for short-lived ones, it does not matter.
*/