本文接前面ConcurrentHashMap文章的内容,继续深入到TreeBin这个特殊节点的读写锁竞争机制。
7、TreeBin类设计原理
对TreeBin类深入分析,不仅能够理解为何CHM能支持并发读的底层实现,而且也能加深jk1.8的ConcurrentHashMap整体设计原理。本文将详细深入地解析TreeBin优秀的读写锁控制设计,此部分内容在全网的相关文章很少涉及。
7.1 保证加锁对象不改变的设计思想
首先看其源码的注释说明:
TreeNodes used at the heads of bins. TreeBins do not hold user keys or values, but instead point to list of TreeNodes and their root. They also maintain a parasitic read-write lock forcing writers (who hold bin lock) to wait for readers (who do not) to complete before tree restructuring operations.
TreeBins节点不是用于放置key和value,而是用于指向TreeNodes和TreeNodes的根节点。TreeBins内部会维护一把读写锁,用于保证在树重构前,持有锁的写线程被强制等待无锁读线程完成。
当然这注释也未能回答这样核心问题:为何对于桶位是红黑树的情况下,CHM放置的一个TreeBin节点,而不像HashMap那样放置一个TreeNode节点?
首先看看TreeBin的使用场景,在put场景下:
1 | synchronized (f) { |
当key所在桶位可以放入key时,先对头节点加锁synchronized (f),注意这是独占锁,要求头节点对象在锁期间不会改变,否则就不能锁住同一对象。
为论证f头节点是TreeNode类型不适用并发的CHM场景,不妨假设CHM使用TreeNode作为CHM桶位上红黑树的头节点,于是在put场景下:
1 | // ① 假设当前头节点f是一个TreeNode节点,则执行流会进入②分支 |
这里关键是第③步逻辑:将key和value插入到红黑树当中,会发生什么事情?
我们知道,在HashMap节点,将一个节点put入红黑树后,需要做插入平衡处理和将红黑树root节点移到双向链表的头节点位置,目的是为了保证桶位上的头节点即是红黑树的根节点也是双向链表的头结点,下面就是HashMap对应的操作
1 | final TreeNode<K,V> putTreeVal(HashMap<K,V> map, Node<K,V>[] tab, |
但对于并发CHM来说,红黑树的插入平衡处理会导致root节点发生了改变(例如插入平衡前根节点是treeNodeA,插入平衡后根节点是treeNodeB)而不是位于桶位头节点上,如果CHM桶位头节点还是TreeNode,那么就会出现以下图示的不能保证写线程独占操作的线程不安全情况。
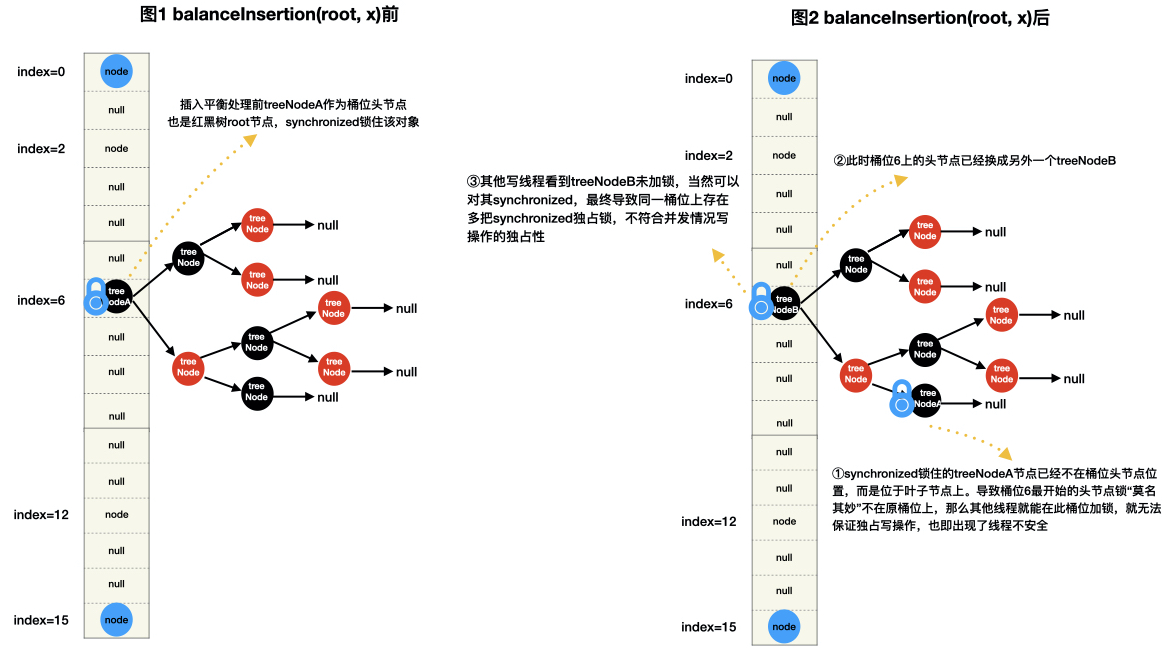
如何解决以上遇到的问题?