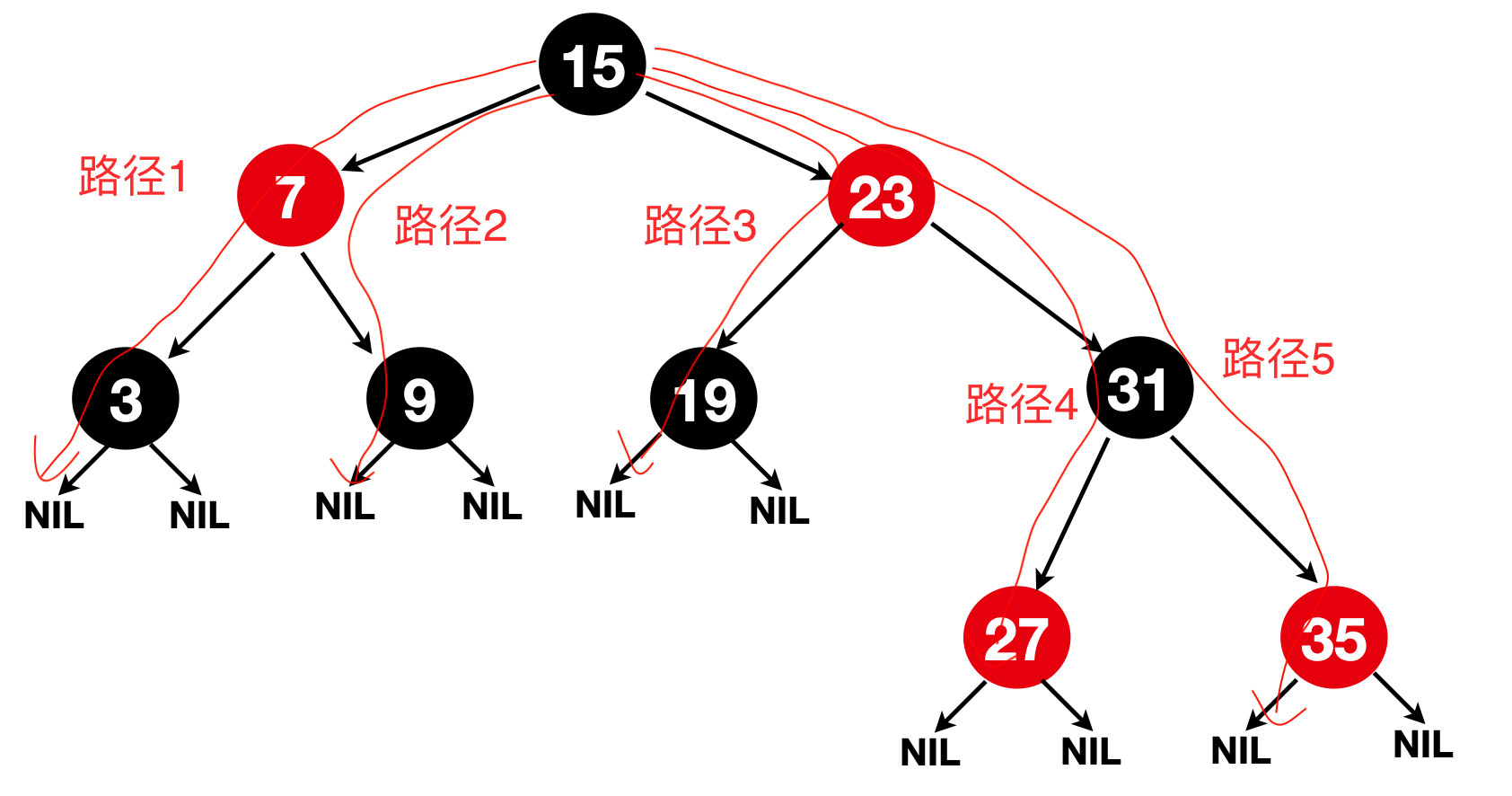
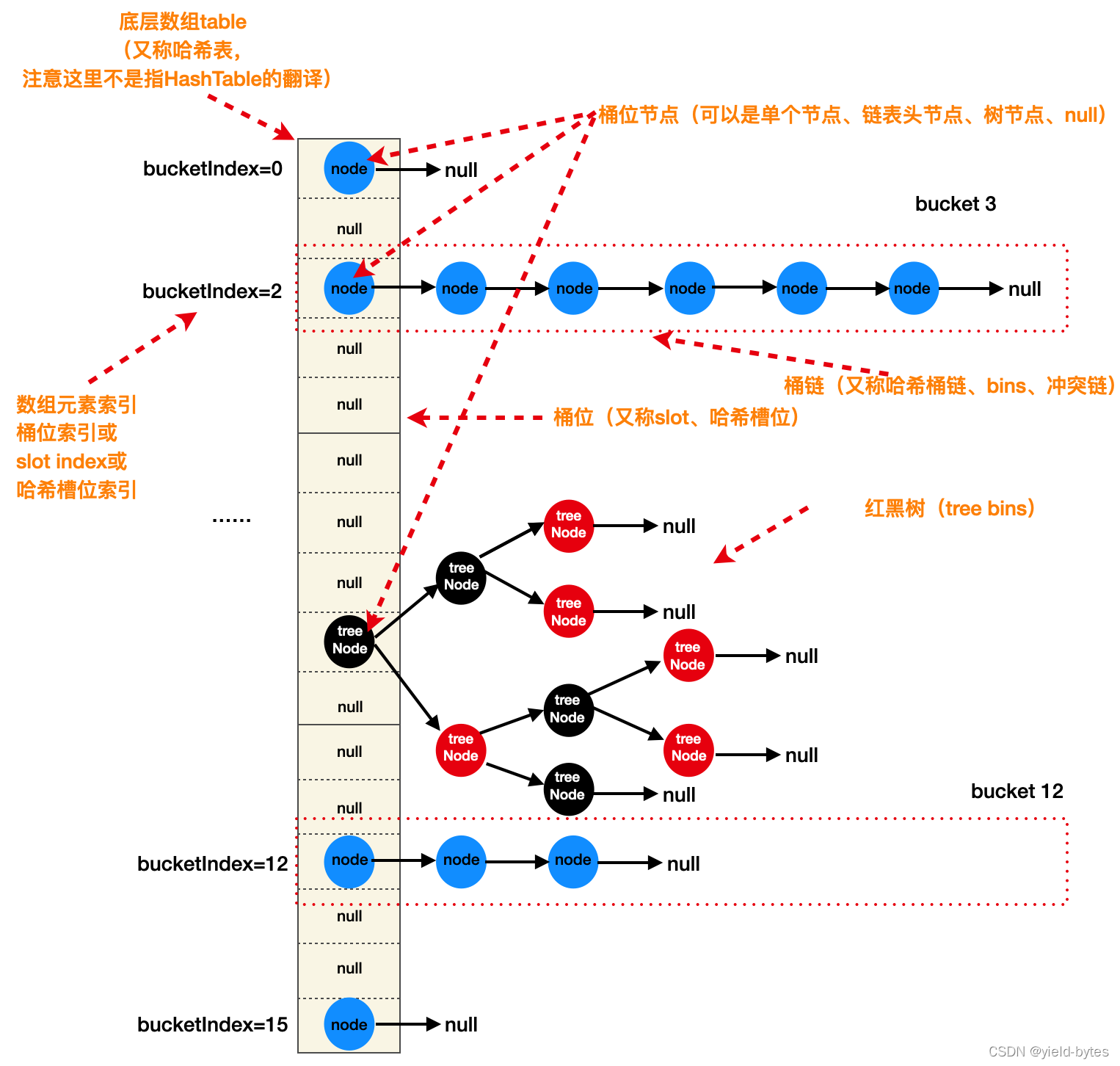
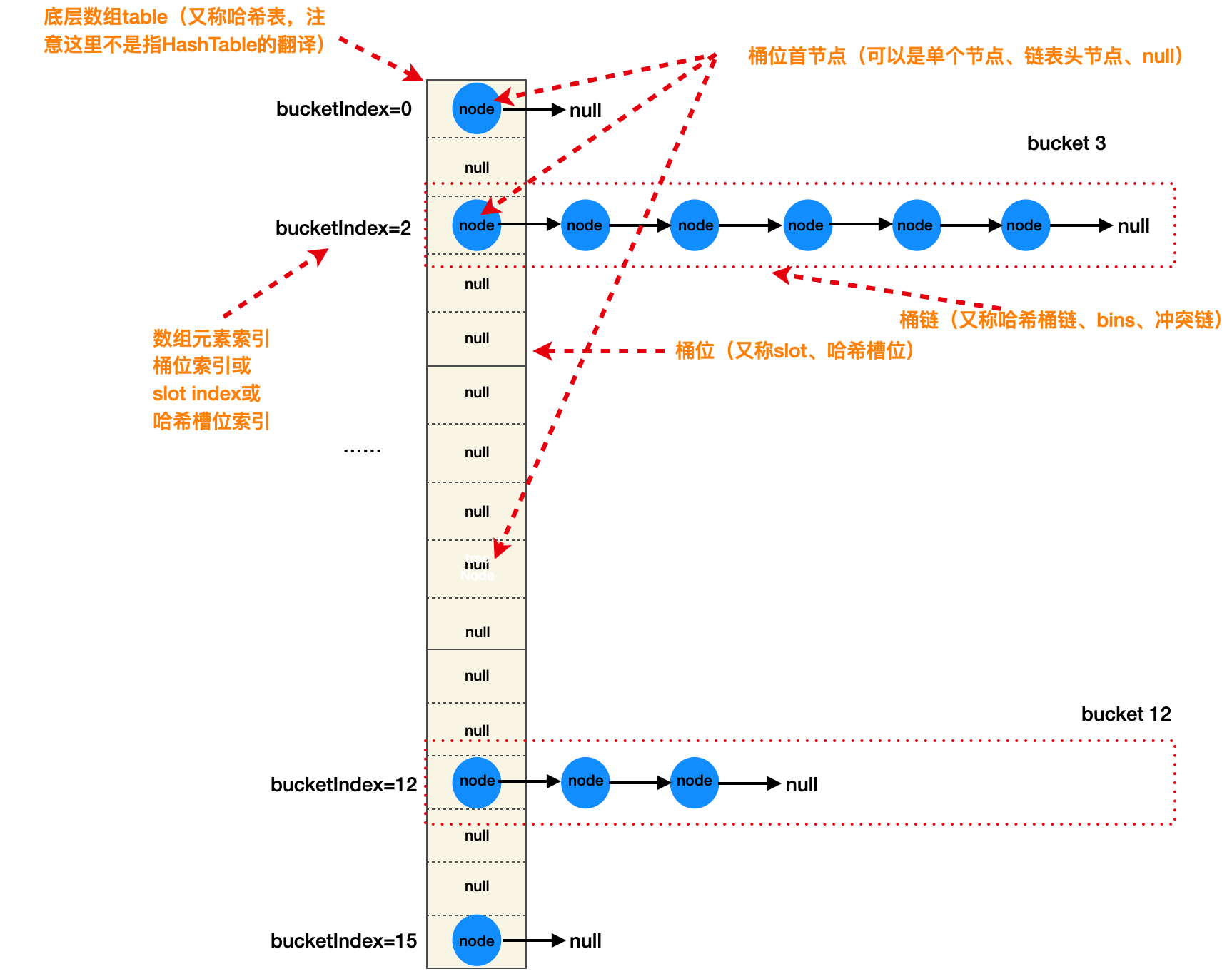
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| pool-1-thread-4:[foo, bar, writer, writer]
pool-1-thread-7:[foo, bar, writer, writer, writer]
pool-1-thread-9:[foo, bar, writer, writer, writer, writer]
pool-1-thread-11:[foo, bar, writer, writer, writer, writer, writer]
pool-1-thread-11:[foo, bar, writer, writer, writer, writer, writer, writer]
pool-1-thread-11:[foo, bar, writer, writer, writer, writer, writer, writer, writer]
pool-1-thread-11:[foo, bar, writer, writer, writer, writer, writer, writer, writer, writer]
pool-1-thread-11:[foo, bar, writer, writer, writer, writer, writer, writer, writer, writer, writer]
pool-1-thread-11:[foo, bar, writer, writer, writer, writer, writer, writer, writer, writer, writer, writer]
Exception in thread "pool-1-thread-2" java.util.ConcurrentModificationException
at java.util.ArrayList$Itr.checkForComodification(ArrayList.java:909)
at java.util.ArrayList$Itr.next(ArrayList.java:859)
at java.util.AbstractCollection.toString(AbstractCollection.java:461)
at java.lang.String.valueOf(String.java:2994)
at java.lang.StringBuilder.append(StringBuilder.java:131)
at concurrent.demo.Reader.run(ArrayListDemo.java:43)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
|