本文介绍Spark DataFrame、Spark SQL、Spark Streaming入门使用教程,这些内容将为后面几篇进阶的streaming实时计算的项目提供基本计算指引,本文绝大部分内容来自Spark官网文档(基于PySpark):
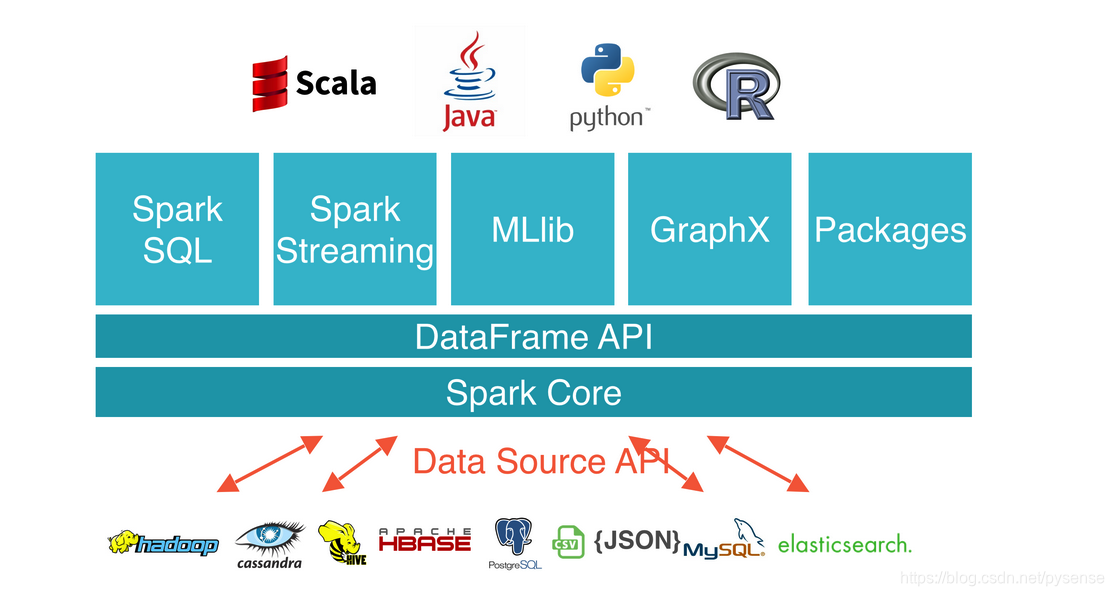
Spark DataFrame、Spark SQL、Spark Streaming
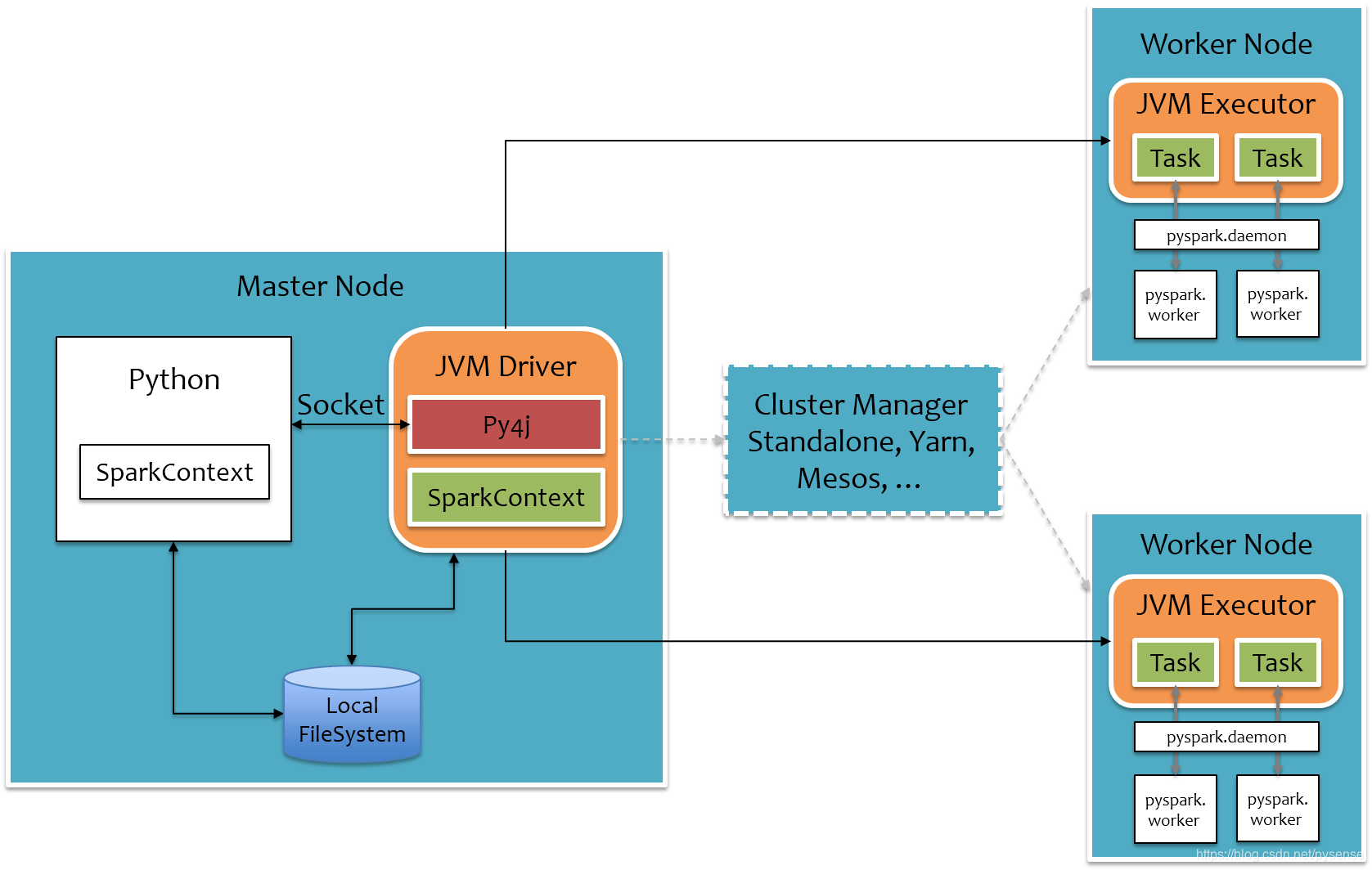
1、RDD、Spark DataFrame、Spark SQL、Spark Streaming
RDD:大家最熟悉的数据结构,主要使用transmissions和actions 相关函数式算子完成数据处理和数理统计,例如map、reduceByKey,rdd没有定义 Schema(一般指未定义字段名及其数据类型), 所以一般用列表索引号来指定每一个字段。 例如, 在电影数据的推荐例子中:1
move_rdd.map(lambda line:line.split('|')).map(lambda a_list:(alist[0],a_list[1],a_list[2]))
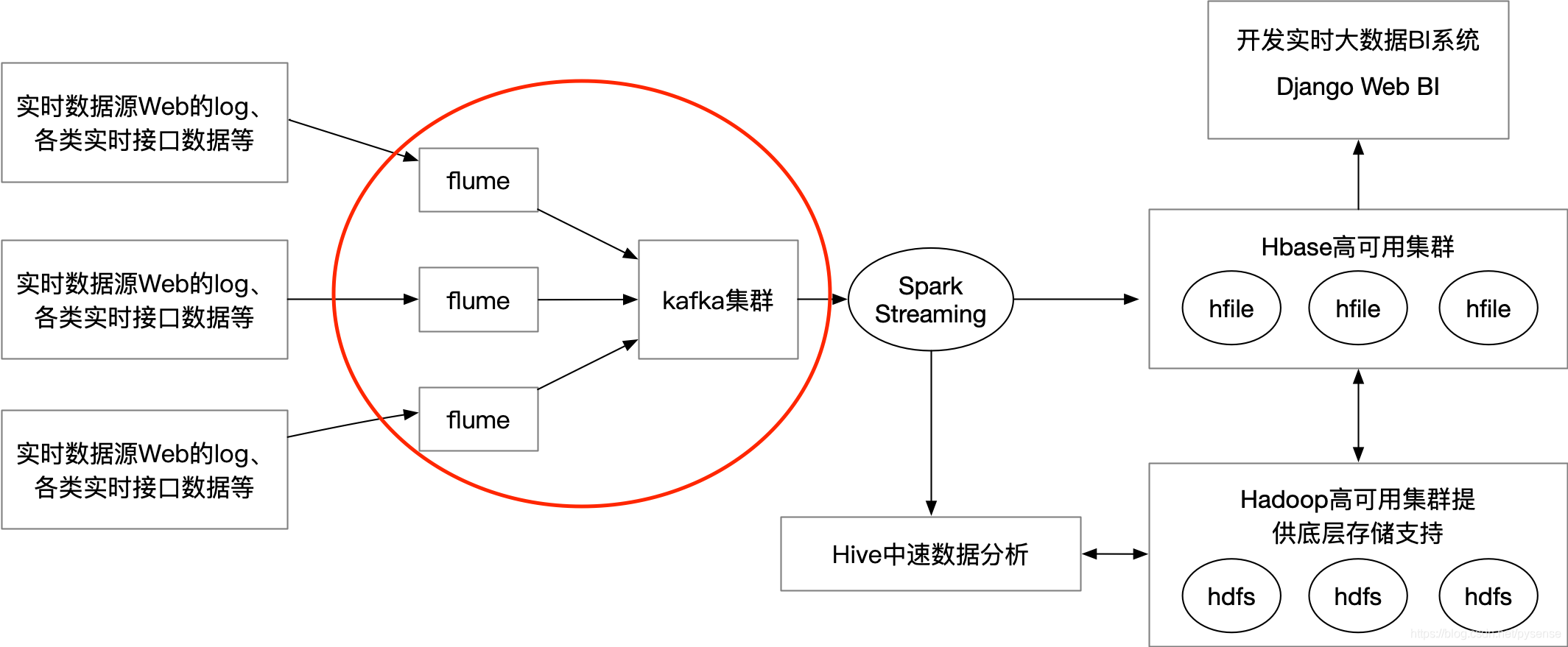 flume NG集群前向的source是各类实时的log数据,通过flume sink将这些日志实时sink到后向kafka集群,所有flume sink其实是本架构里kafka的producer角色,kafka集群后向连接spark streaming,用于消费kafka的实时消息(log日志数据)流。
flume NG集群前向的source是各类实时的log数据,通过flume sink将这些日志实时sink到后向kafka集群,所有flume sink其实是本架构里kafka的producer角色,kafka集群后向连接spark streaming,用于消费kafka的实时消息(log日志数据)流。