在前面的文章《在hadoopHA节点上部署kafka集群组件》,介绍大数据实时分析平台生态圈组件——kafka,前向用于连接flume,后向连接spark streaming。在研究Kafka过程中,发现该中间件的设计很巧妙,因此专设一篇文章用于深入理解Kafka核心知识。Kafka已经纳入个人目前最欣赏的中间件list:redis,zookeeper,kafka
1、kafka集群架构图
以下为kafka集群一种经典的架构图,该图以《在hadoopHA节点上部署kafka集群组件》文章的kafka集群以及sparkapp topic作为示例绘成,本文的内容将以该图为标准作为说明。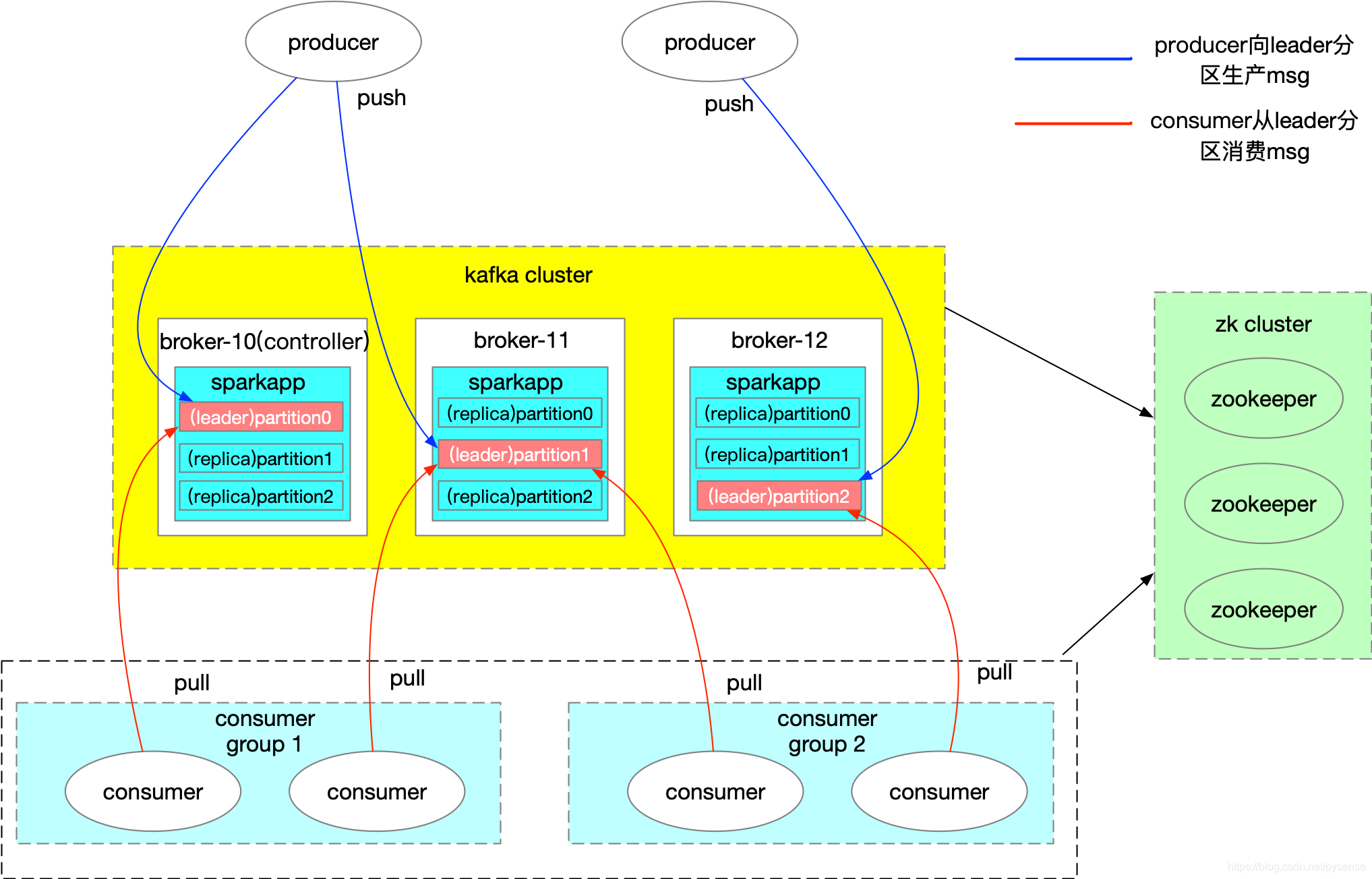 图1 kafka集群架构图
图1 kafka集群架构图
 如上图所示,架构主要有以下4个部分
如上图所示,架构主要有以下4个部分