1、前言
前面的博客中链接已经给出Hadoop3.1.2和yarn的完整部署(但还不是高可用),此篇博客将给出Hadoop的高可用部署,以及HBase高可用,为之后应用数据层开发提供底层的BigTable支持。前面的文章,我们已经深入讨论的ZooKeeper这个中间件的原理以及分布式锁的实现,事实上zookeeper使用最广泛的场景是“选举”主从角色,Hadoop以及Hbase的高可用(主从架构)正是通过ZooKeeper的临时节点机制实现。
以下的配置会跳过Hadoop3.1.2的部署,仅给出ZooKeeper分布式物理方式部署、以及HBase的部署过程、测试结果。
2、ZooKeeper与Hadoop、HBase的关系
ZooKeeper作为协调器,在大数据组件中提供:管理Hadoop集群中的NameNode、HBase中HBaseMaster的选举,节点之间状态同步等。例如在HBase中,存储HBase的Schema,实时监控HRegionServer,存储所有Region的寻址入口,当然还有最常见的功能就是保证HBase集群中只有一个Master。
3、Hadoop与HBase的关系
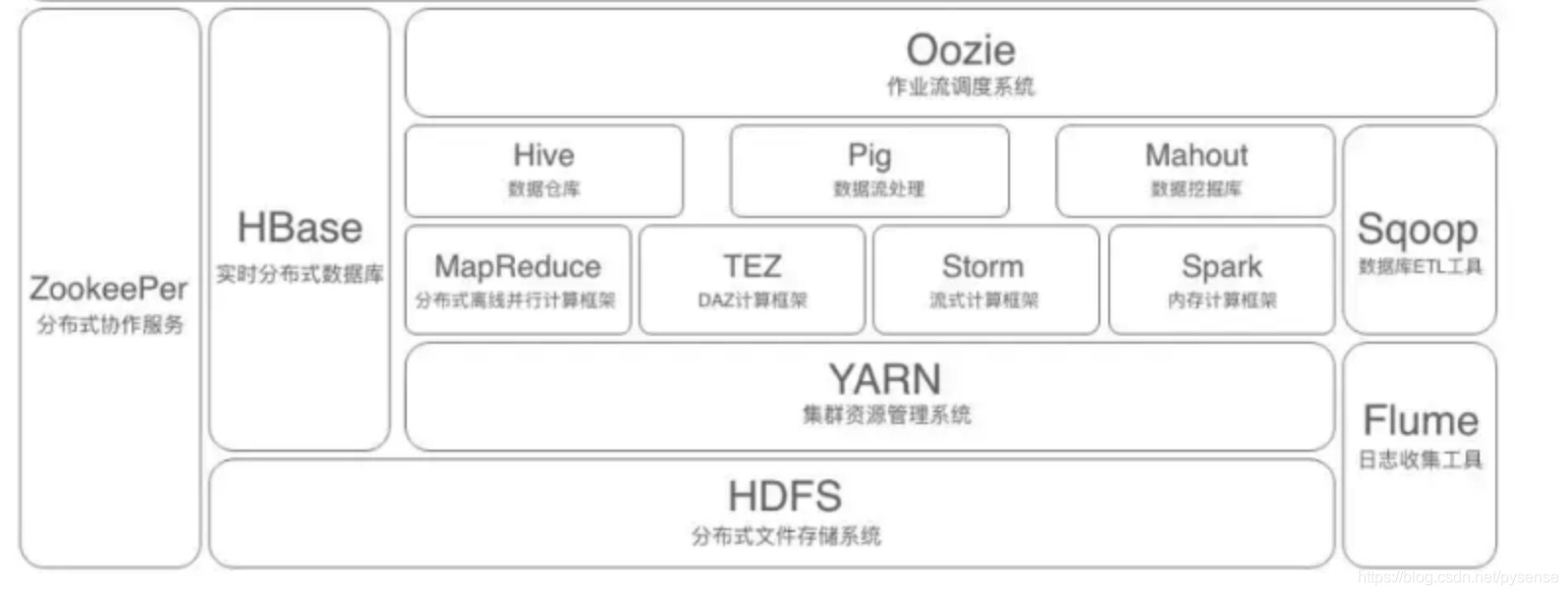
完整的hadoop组件环境架构图